










Dify v0.7.0: Enhancing LLM Memory with Conversation Variables and Variable Assigners
Dify v0.7.0 tackles LLM memory limitations with Conversation Variables and Variable Assigner nodes. These features give Chatflow-built apps precise memory control, boosting LLMs' ability to handle complex scenarios in production.

We have been focusing on enhancing LLM application memory management to meet specific scenario needs. While LLMs can store chat history in context windows, attention limitations often lead to memory gaps or imprecise focus in complex use cases.
Dify's latest release tackles this with two new features: Conversation Variables and Variable Assigner nodes. Together, these give Chatflow-built LLM apps more flexible memory control. They allow reading and writing of key user inputs, boosting LLMs' ability to handle specific app needs and improving their real-world use in production.
Conversation Variables: Precise context memory storage
Conversation Variables enable LLM applications to store and reference context information. Developers can use these variables within a Chatflow session to temporarily store specific data like context, user preferences, and soon, uploaded files. Variable Assigner nodes can write or update this information at any point in the conversation flow.
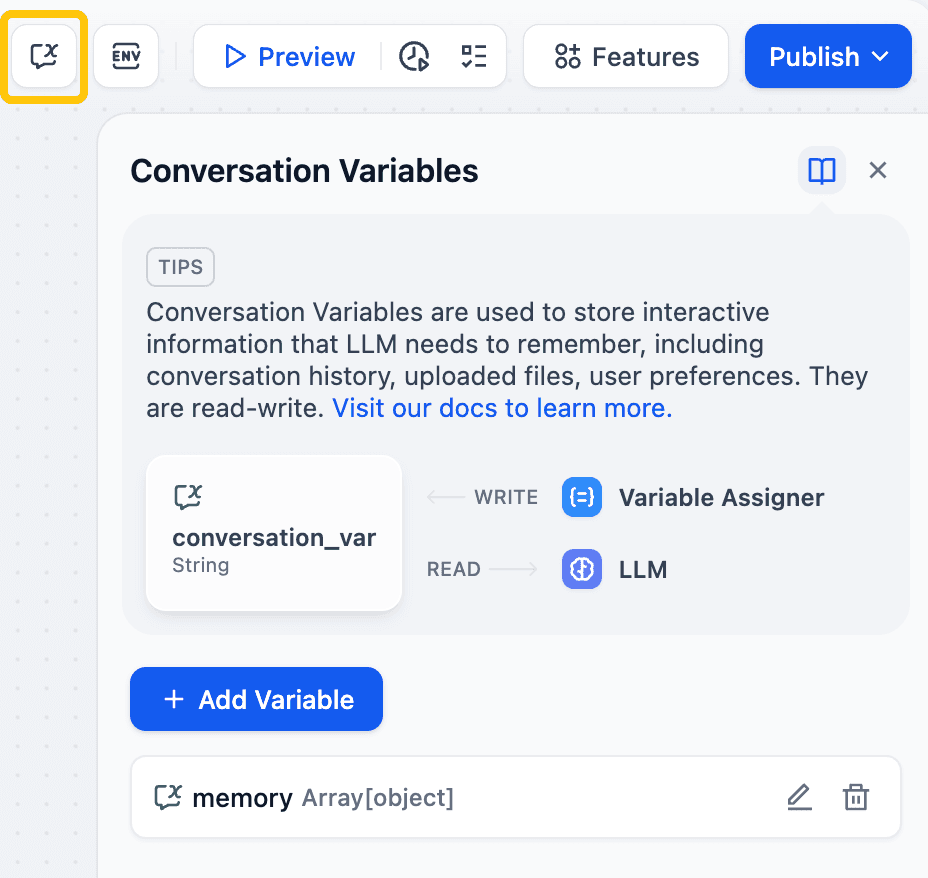
Pros of Conversation Variables:
- Precise context management: Manage information at the variable level, not just entire chat logs.
- Structured data support: Handle complex data types, including strings, numbers, objects, and arrays.
- Workflow integration: Write or update variables anywhere in the Chatflow for downstream LLM nodes to access.
Conversation Variables offer more granular management than default chat history. This allows applications to accurately remember and reference specific information, enabling more personalized multi-turn interactions.
Variable Assigner nodes: Setting and writing conversation variables
Variable Assigner nodes set values for writable variables, like the newly introduced Conversation Variables. These nodes let developers store user input temporarily for ongoing reference in the dialogue.
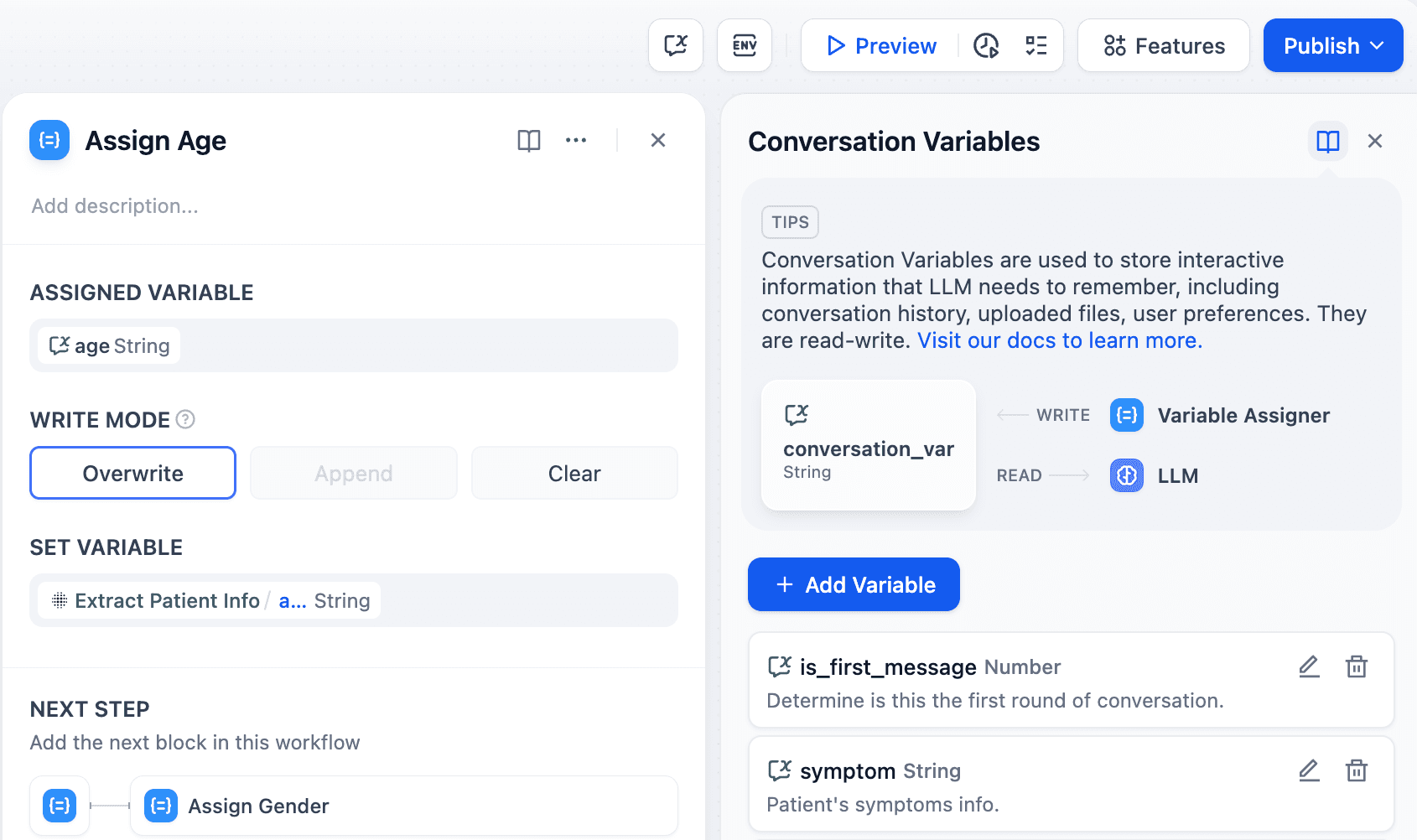
For applications needing to record initial user preferences, developers can use Conversation Variables and Variable Assigner nodes to:
- Store user language preferences
- Consistently use the chosen language in subsequent responses
For instance, if a user selects Chinese at the conversation's start, a Variable Assigner node writes this to the `language` conversation variable. The LLM then uses this variable to maintain Chinese communication throughout the interaction.
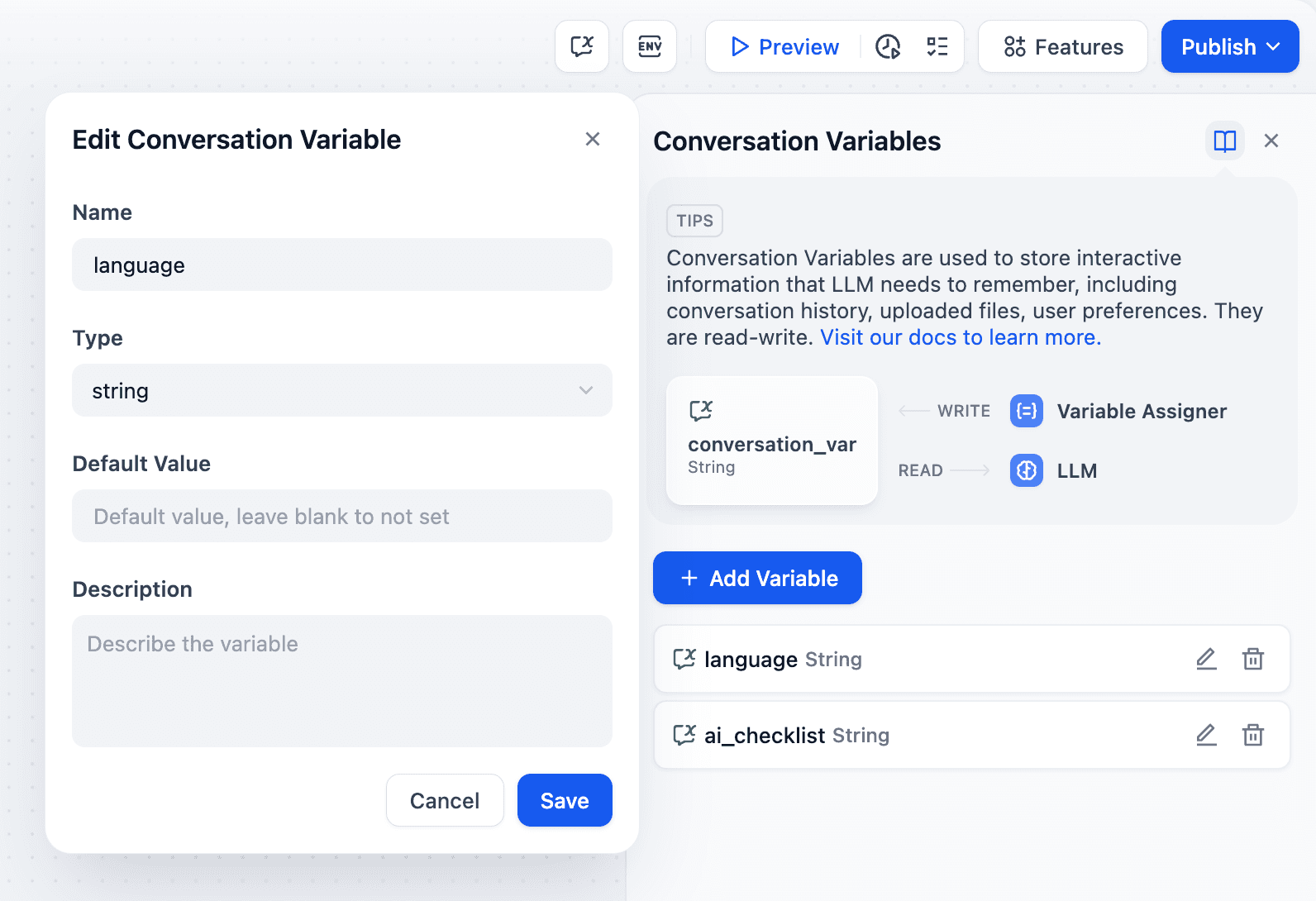
This approach simplifies preference capture and use, improving conversation flow and user experience in LLM applications.
Additional use cases
Conversation Variables and Variable Assigner nodes extend beyond storing preferences. Consider these applications:
- Patient Intake assistant: Stores user-input gender, age, and symptoms in variables, enabling tailored department recommendations.
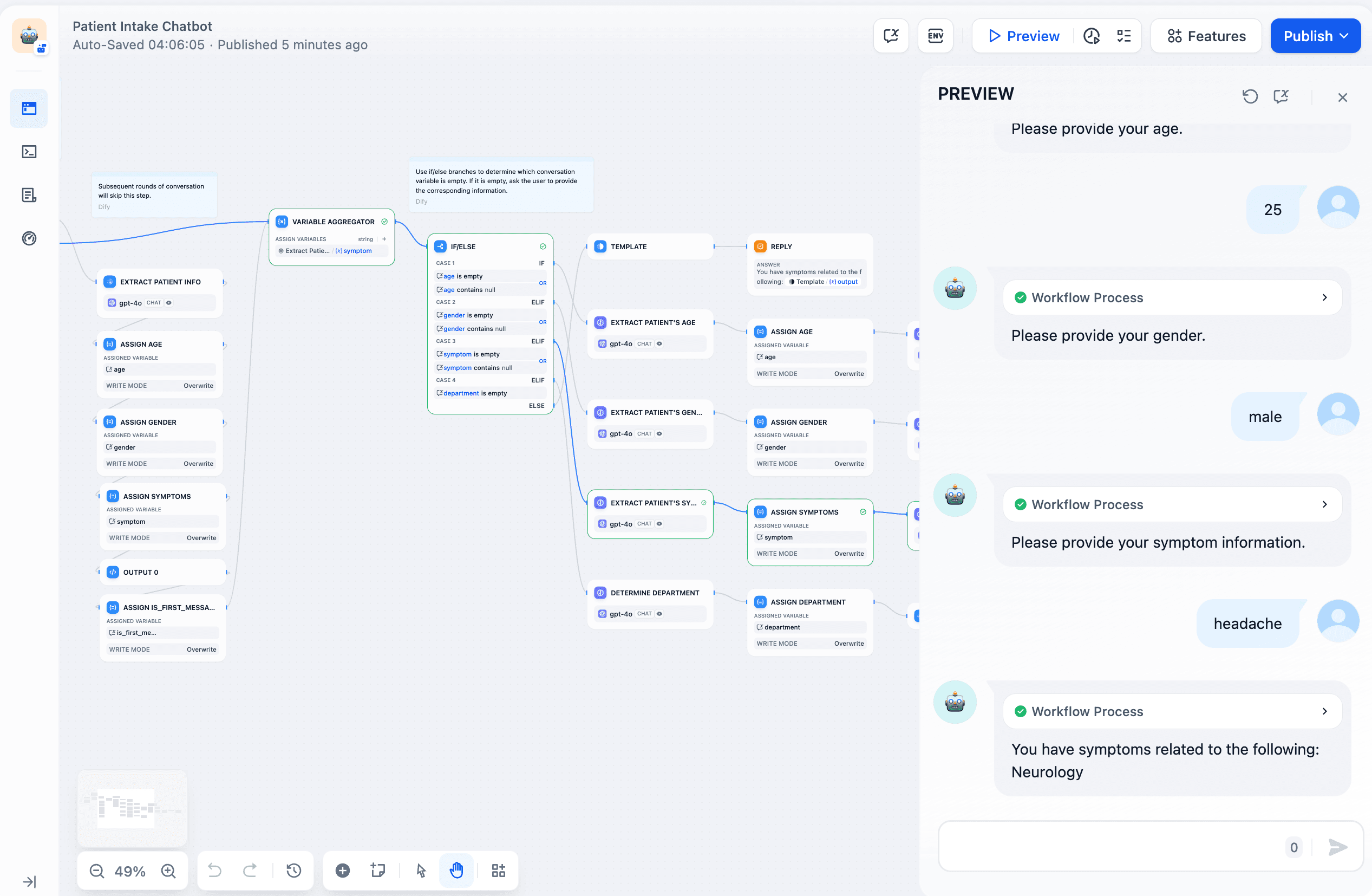
- Dialogue summarization: Uses Variable Assigner nodes in upstream LLM nodes to extract overviews, preventing memory overload from full chat histories.
- Data analysis helper: Enables retrieval of external system data during conversations for use in subsequent exchanges.
- Creative writing: Supports dynamic story creation by storing and modifying elements as Object arrays:
[{name: "Alice", role: "protagonist", trait: "brave"},{name: "Mystical Forest", type: "setting", atmosphere: "eerie"}]
These examples show how Conversation Variables and Variable Assigner nodes meet complex needs with personalized memory storage. Check our docs and templates to start building memory-enabled LLM apps today!
Related articles
- Product
Now on Dify Marketplace: Qubrid AI Brings Multi-Model Access to Every Dify Workflow
Install the Qubrid AI plugin on Dify to unlock unified access to DeepSeek, Kimi, Qwen, MiniMax, GLM, and more, all through one API key.

 Qubrid AI & Dify
Qubrid AI & Dify - Product
Grounding Dify Agents in Real Data: MongoDB Atlas and Voyage AI Are Now Native to Dify RAG Workflows
Dify and MongoDB make it easier to build grounded AI agents that retrieve, reason over, and act on real business data, without stitching together custom RAG infrastructure from scratch.
 MongoDB & Dify
MongoDB & Dify - Product
Dify Creator Center & Template Marketplace: Share Your Workflows
Dify’s new Creator Center and Template Marketplace let creators publish workflow templates and users discover and one-click adopt them, with optional PartnerStack affiliate linking to earn recurring commissions from subscriptions driven by template links.
Dify - Product
Try OpenAI, Claude, Gemini & Grok Free on Dify Cloud
Supports OpenAI, Claude, Gemini, and Grok. Try curated templates with zero configuration.
Dify