










Dify v1.1.0: Filtering Knowledge Retrieval with Customized Metadata
Today, we’re launching Dify v1.1.0 featuring Metadata as a Knowledge Filter, which enhances accuracy, security, and efficiency by allowing precise filtering and access control of data, crucial for effective retrieval-augmented generation (RAG) management.

Hi, I'm Yawen from the Dify product team. Today, we're excited to launch Dify v1.1.0 with the new features of Metadata as a Knowledge Filter. Metadata filtering enhances the retrieval and accuracy of relevant data in knowledge bases by leveraging custom metadata attributes. Previously, users had to search through an entire vast dataset without the ability to filter or control access based on specific needs, making it difficult to narrow results to the most relevant information. With metadata, data is essentially tagged and categorized, significantly improving retrieval efficiency and accuracy. This concept is particularly significant in the context of RAG(retrieval-augmented generation) , where vast amounts of information need to be efficiently managed and accessed.
Understanding Metadata Filtering
Metadata is essentially "data about data". It provides additional context or attributes that describe the main data, enabling more precise searches and retrievals. For instance, in a document management system, metadata might include the document's name, author, creation date and etc. This structured information allows systems to filter results based on specific criteria, improving the relevance of the retrieved content.
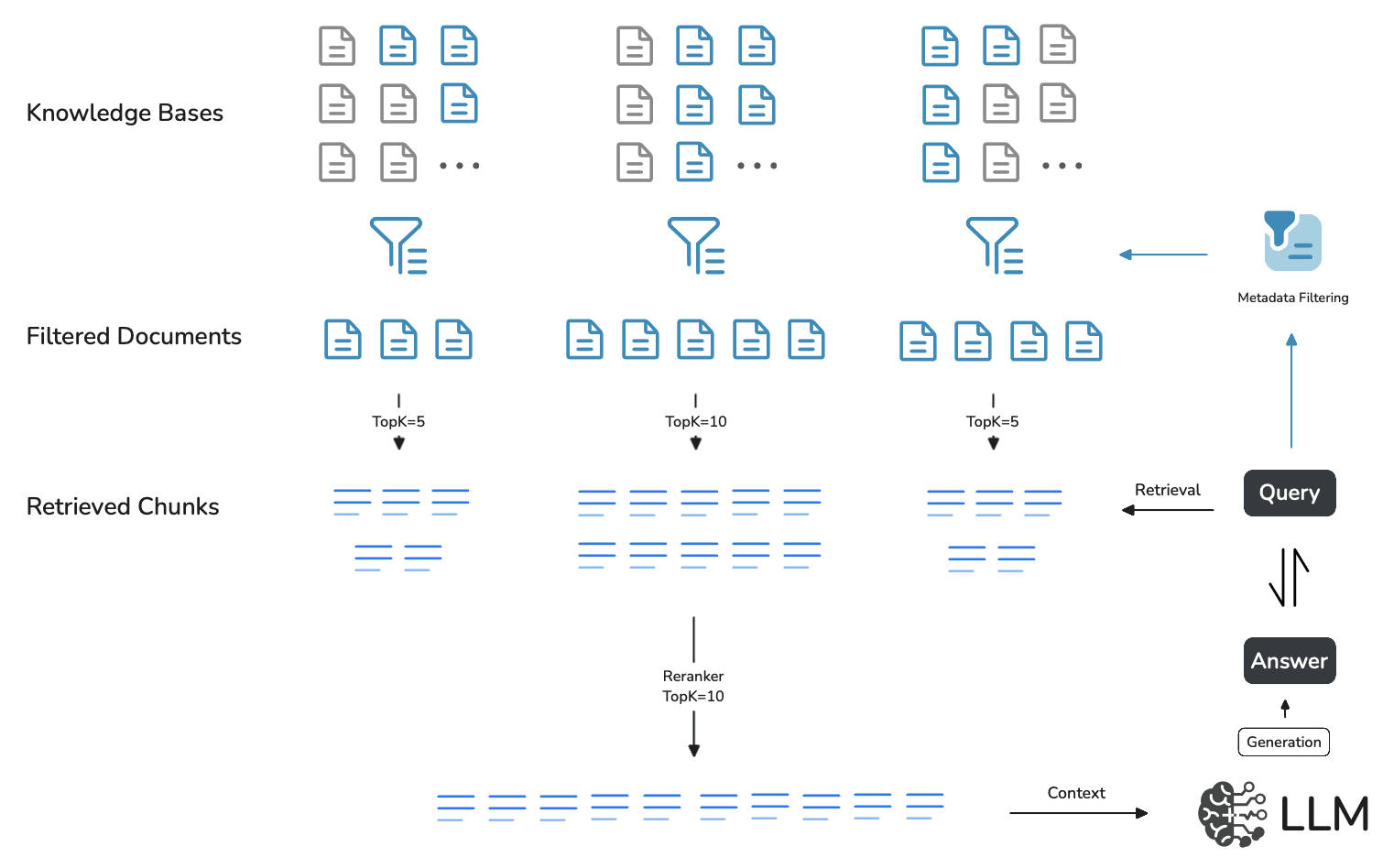
Advantages of applying Metadata Filtering
Metadata filtering enhances search accuracy by enabling users to quickly locate relevant documents while minimizing irrelevant results. It strengthens data security by enforcing access controls, ensuring that only authorized users can view sensitive information. Additionally, it optimizes search performance by refining query scope, improving efficiency, and conserving computational resources. This customization enhances user experience, facilitating faster and more intuitive navigation through large document repositories, particularly in enterprise environments.
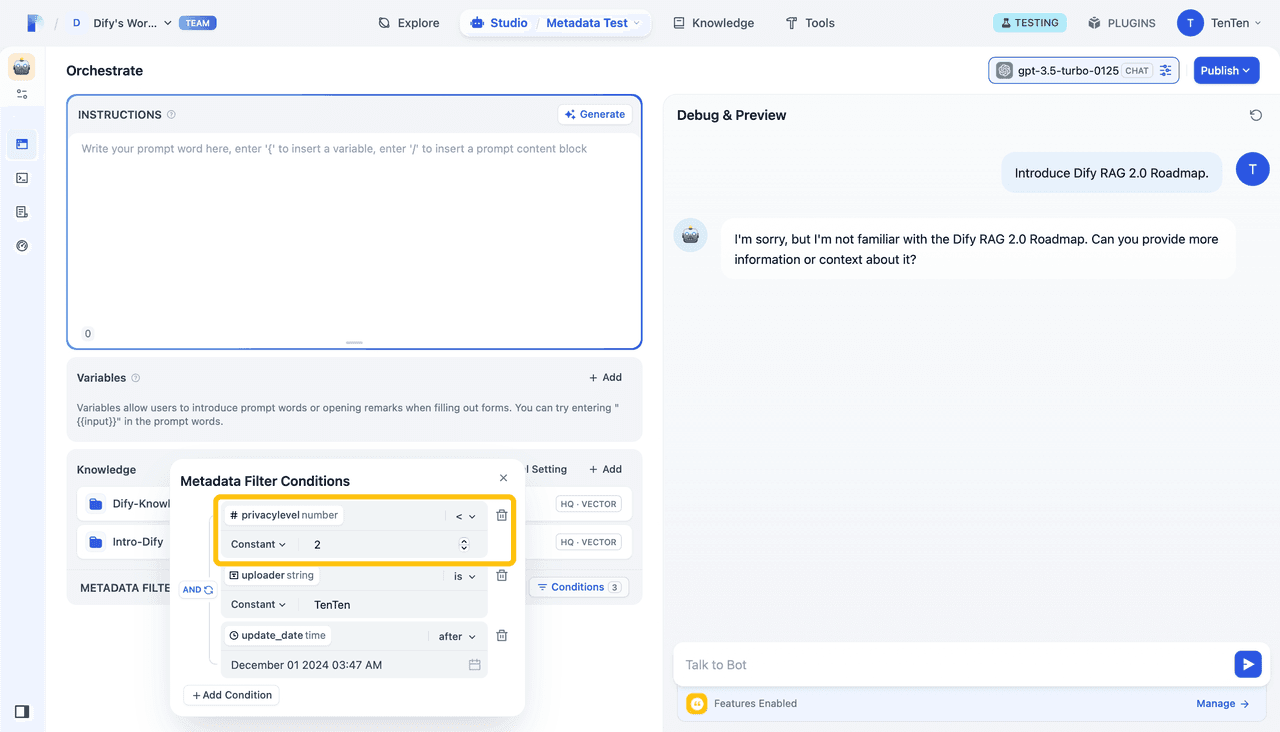
The diagram below illustrates a comparison of access control, demonstrating how Metadata filtering enables fine-grained access management. In this example, three filtering criteria are applied: privacylevel, uploader, and update_date.
By adjusting privacylevel, user access to the RAG 2.0 Roadmap can be controlled. This allows administrators to precisely manage which users can retrieve or view specific information, enhancing both security and efficiency in data access.
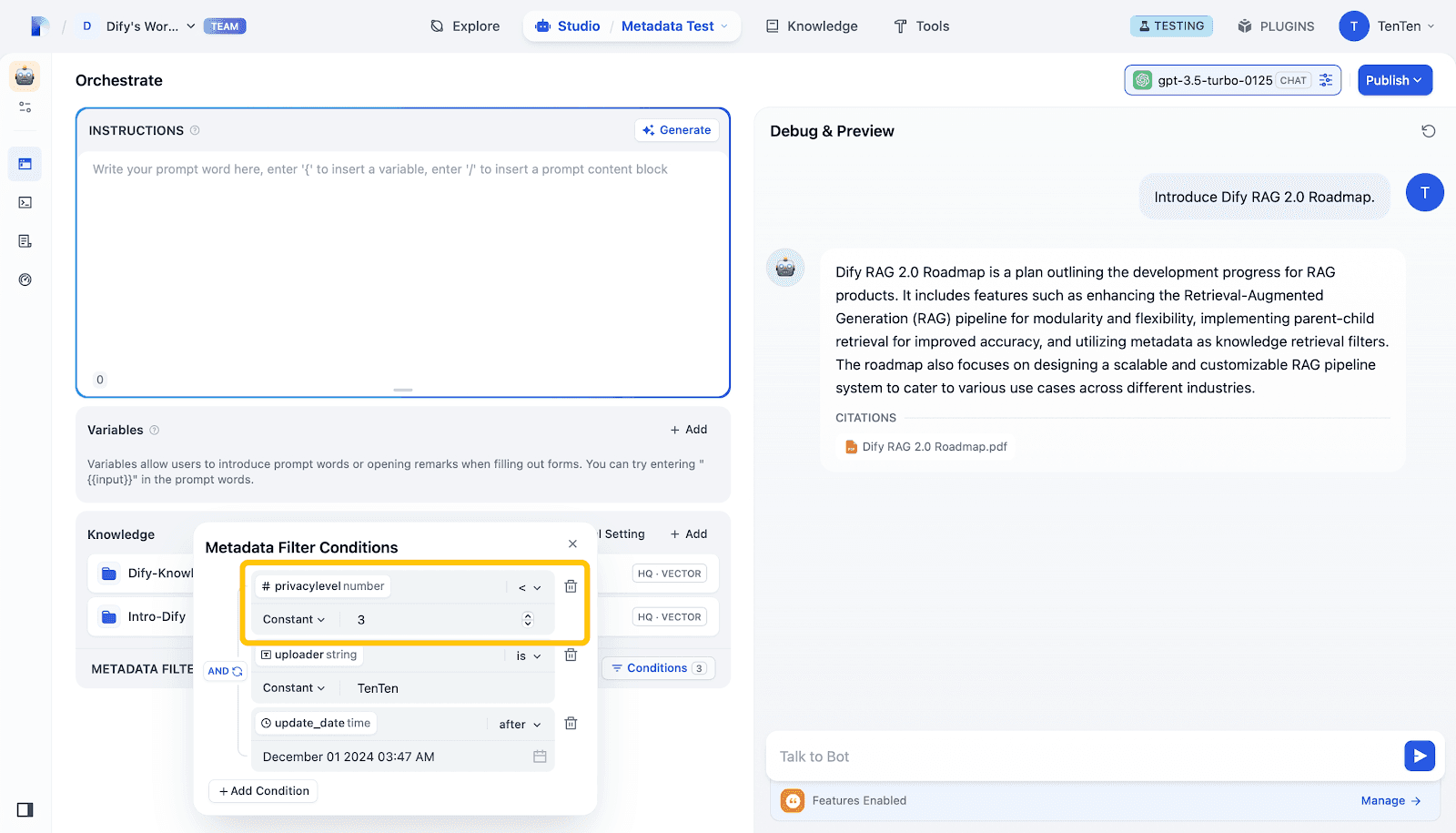
In short, metadata serves as an intelligent knowledge filter, enabling smarter, more secure, and efficient information retrieval by adding contextual layers and access controls. This is especially crucial in RAG(retrieval-augmented generation) systems, where maintaining knowledge privacy and relevance is essential.
How to use Metadata as a Knowledge Filter?
Step 1: Adding Metadata to Documents in the Knowledge Base
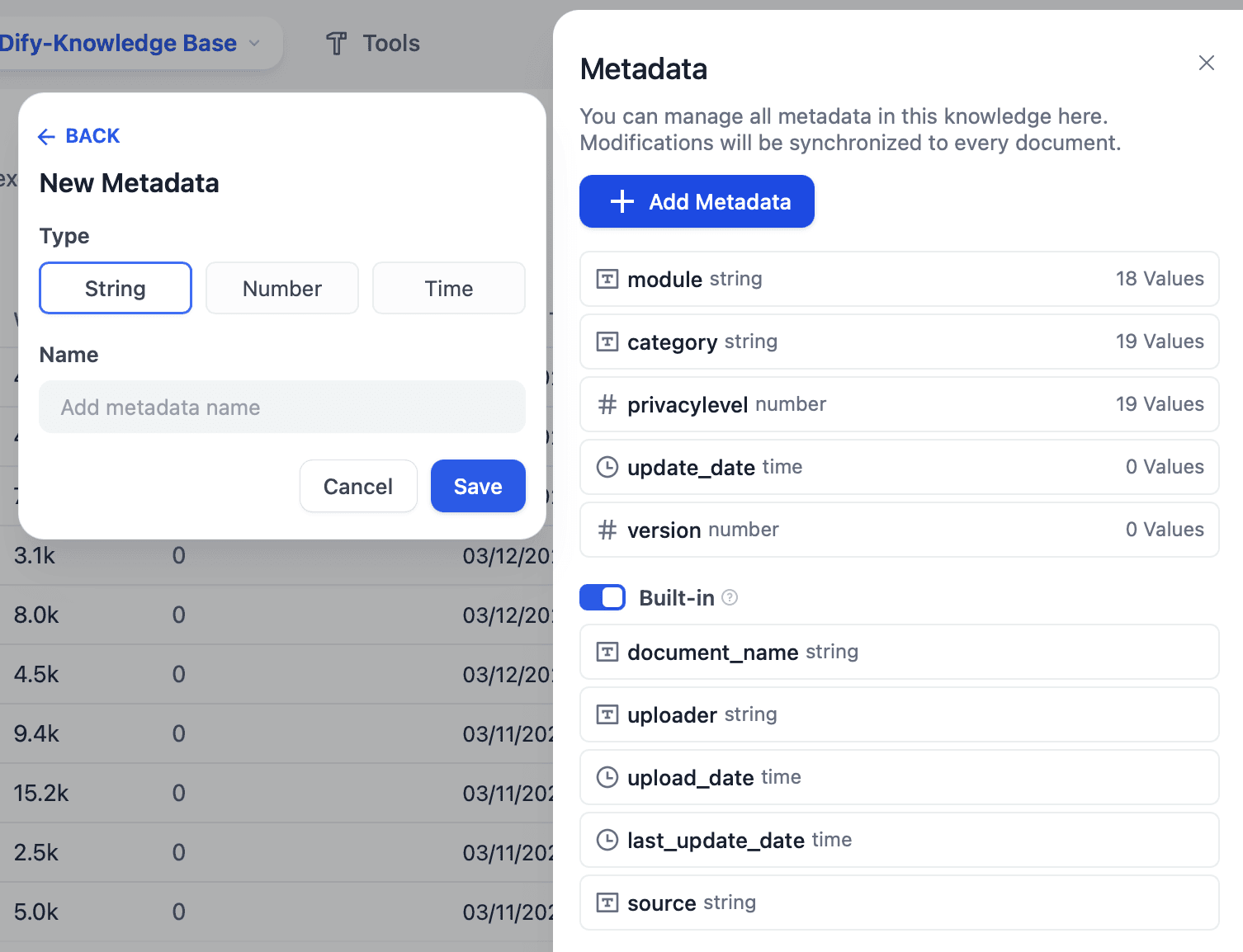
Users can add and manage metadata for documents in the knowledge base. Each document is automatically assigned some default metadata upon creation, such as filename, uploader, upload date, etc. Users can also manually add new metadata fields, set field names and data types, and perform batch edits or modifications on existing documents. This tagging process allows users to add additional structured information to documents, making them easier to search and manage later.
Step 2: Configuring Metadata Filtering in Applications
Users can find metadata filtering in the Context part of Chatbot or the Knowledge Retrieval node of Chatflow or Workflow, enables users to precisely filter and retrieve information based on metadata attributes. Users can choose between automatic or manual metadata filtering options. In automatic mode, metadata filtering conditions are extracted and generated from the user query. When manually configuring, users can set filtering conditions based on the metadata field type (such as string, number, or time) and further set the relationship between multiple conditions to And or OR.
Three types of Metadata and their applications
We support three types of metadata: string, number, and time. Each type can be flexibly applied based on actual use cases. Below are some examples:
- String Metadata – Enhancing Contextual Relevance
String metadata helps refine search results by filtering out irrelevant information. For instance, when a user searches for "project reports," metadata tags like "Marketing" or "R&D" ensure that only documents related to those specific departments or projects are returned.
- Number Metadata – Enforcing Access Control
Number metadata can be used to restrict access based on predefined criteria. For example, a user may only retrieve documents with a privacy level above a certain threshold, ensuring secure and appropriate data access.
- Time Metadata – Managing Document Versions
Time metadata allows differentiation between old and new versions of documents. When content is updated and re-uploaded, time-based filtering ensures that searches prioritize the most recent version. When the uploader is set to itself, users can conveniently conduct comparative retrieval tests on multiple versions uploaded in different batches with consistent document processing.
If you want to know more detailed operations, please refer to the Knowledge Base|Dify documentation for detailed instructions and experience it yourself on Dify.AI!
Related articles
- Product
Now on Dify Marketplace: Qubrid AI Brings Multi-Model Access to Every Dify Workflow
Install the Qubrid AI plugin on Dify to unlock unified access to DeepSeek, Kimi, Qwen, MiniMax, GLM, and more, all through one API key.

 Qubrid AI & Dify
Qubrid AI & Dify - Product
Grounding Dify Agents in Real Data: MongoDB Atlas and Voyage AI Are Now Native to Dify RAG Workflows
Dify and MongoDB make it easier to build grounded AI agents that retrieve, reason over, and act on real business data, without stitching together custom RAG infrastructure from scratch.
 MongoDB & Dify
MongoDB & Dify - Product
Dify Creator Center & Template Marketplace: Share Your Workflows
Dify’s new Creator Center and Template Marketplace let creators publish workflow templates and users discover and one-click adopt them, with optional PartnerStack affiliate linking to earn recurring commissions from subscriptions driven by template links.
Dify - Product
Try OpenAI, Claude, Gemini & Grok Free on Dify Cloud
Supports OpenAI, Claude, Gemini, and Grok. Try curated templates with zero configuration.
Dify