










Dify Rolls Out New Architecture, Enhancing Flexibility and Scalability
We've totally revamped Dify's core architecture, moving to a more modular approach. Our latest Beehive architecture allows each module to stand on its own, enabling developers to adjust parts without affecting the overall structure.

Dify, an open-source platform for creating apps with large language models (LLMs), differs from LangChain and similar products that concentrate on a single touchpoint. Dify provides numerous interaction points and meets more intricate integration requirements. It's a cutting-edge, multi-touchpoint service layer, ensuring high compatibility and uniformity across different interfaces and platforms. This guarantees smooth integration and interaction between a variety of systems and applications.

As 2024 shapes up to be a key year for multimodal development, staying ahead in the industry means quickly adapting to changing tech trends. We get that serving developers better involves blending our architecture's strong base with more flexibility, scalability, and teamwork features. That's led us to totally revamp Dify's architecture, moving to a more modular design. This update lets each component be developed, tested, and deployed on its own. It also enables horizontal scaling, fitting a range of application scenarios without waiting for official updates, and keeps API consistency for smoother compatibility between different touchpoints.
Dify Beehive Architecture
We're super excited that Dify is leading the way in this field, especially at such a key time. Making our first mark in this new era with the Dify Beehive architecture is a big step forward.
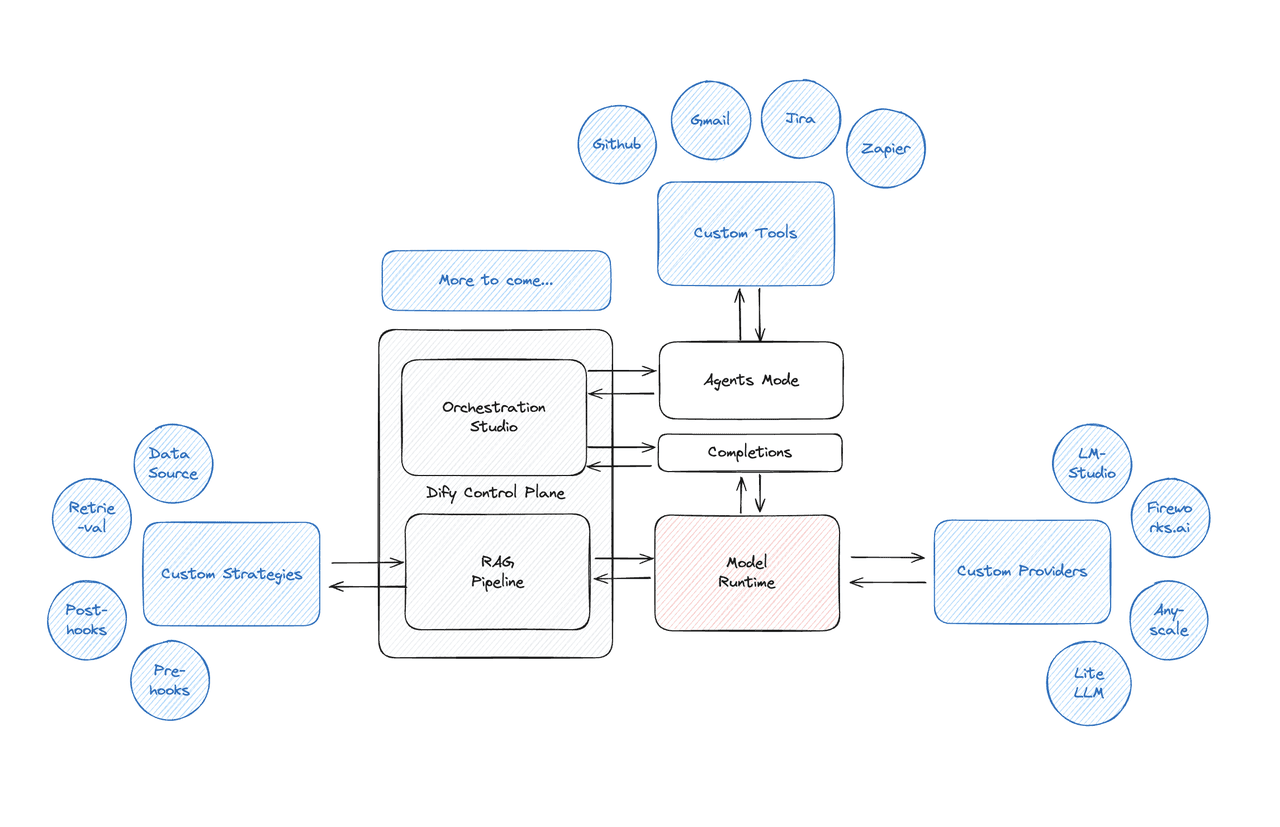
True to its name, the Beehive architecture organizes things in a way that's similar to the hexagonal structure of a beehive. This design makes each part both independent and collaborative, as well as flexible and scalable. It makes the whole system easier to maintain and upgrade, allowing changes to individual modules without messing up the overall structure. The architecture includes all the key tech needed for building LLM applications, like supporting loads of models, an easy-to-use prompt orchestration interface, a top-notch RAG engine, a flexible Agent framework, and a straightforward set of interfaces and APIs. This saves developers from having to start from scratch, letting them focus more on coming up with new ideas and meeting business needs.
The Beehive architecture's tight integration also shows off the teamwork-like nature of a beehive, with different parts and pieces working closely to get complicated tasks done. This kind of teamwork is what Dify has always aimed for in making AI accessible to everyone, even those without tech skills.
What's Next
Looking ahead, Dify plans to modularize even more features to boost its flexibility and ability to grow. This includes:
- RAG Engine Component Modularization: Breaking down the RAG Engine into smaller parts, like ETL, embedding, index building, and data recall. Developers will be able to pick and choose their tools, models, and strategies for each part, giving them more freedom and customization options.
- Adding more tools: Dify will start supporting tools that meet the OpenAPI Specification API standard and can work with tools that follow the OpenAI Plugin standard. This will seriously beef up Dify's toolbox, making it fit for a broader range of uses and user needs.
- More flexible workflow setups: Dify will allow developers to tweak workflows to suit their own business processes and needs. This will make Dify a go-to tool for various industries and situations, better meeting all kinds of business requirements.
Model Runtime
With this restructuring, we've launched our first service module, Model Runtime, marking the beginning of the restructuring plan and a key step towards enhancing flexibility and expandability.

Before version 0.4.0 came out, Dify already backed hundreds of popular commercial and open-source models, both local and MaaS-based. This included LLM, Text Embedding, Rerank, Speech2Text, TTS, and others. But, Dify's dependence on the complex, less adaptable LangChain framework made it tough for developers to add new models. Issues they faced included invasive development, no standard interface specs, and juggling different programming languages for the front-end and back-end.
The Runtime tackles this by making it easier to plug in models and letting developers set up model providers flexibly. This plug-and-play approach means developers can add various models much faster.
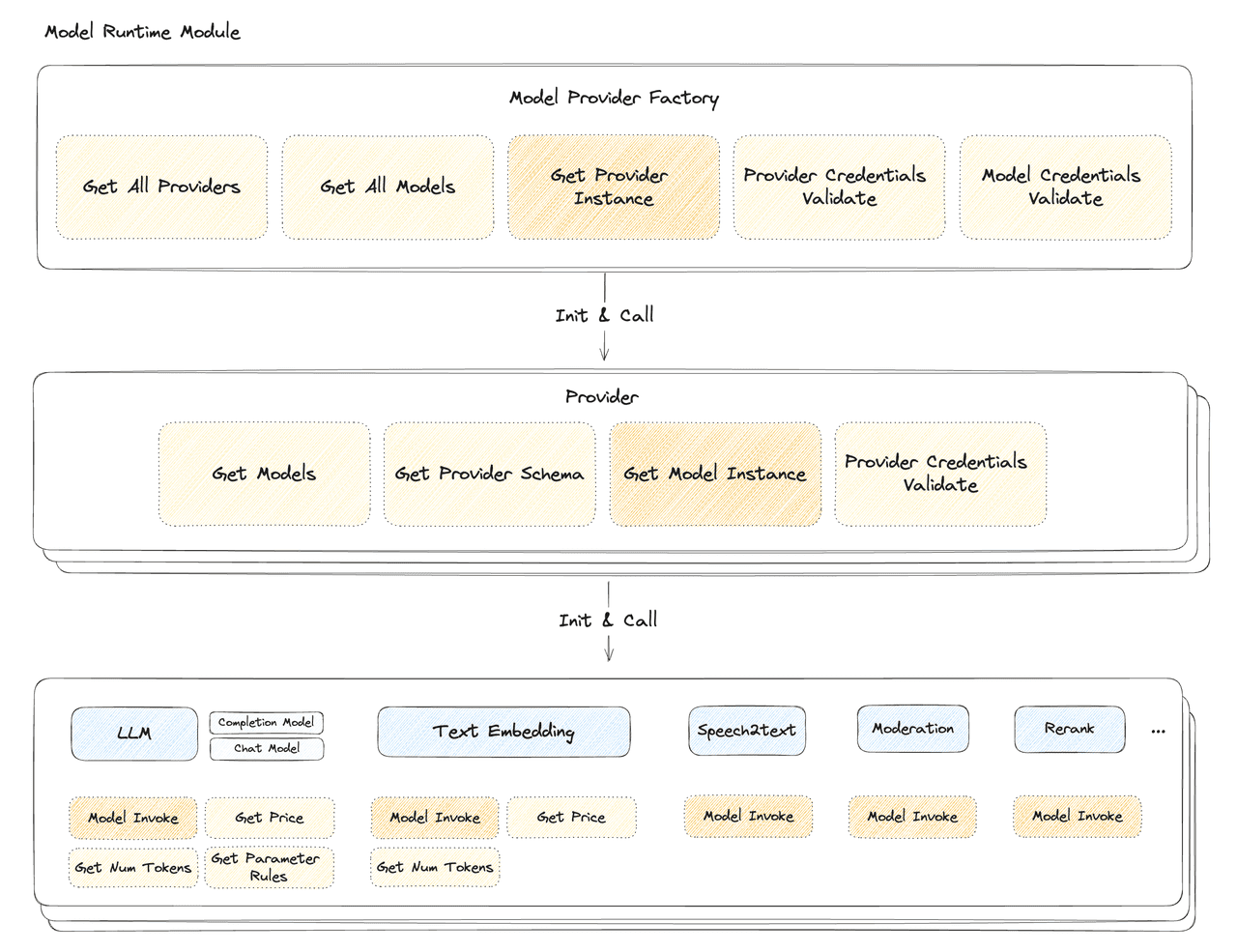
The major advancements
Unified Interface
All model types, like text embedding or inference models, have a streamlined, unified interface. This consistent access method simplifies and makes the process of integrating models more efficient.
# Example using Anthropic's large language model, where all models inherit from a model base classclass AnthropicLargeLanguageModel(LargeLanguageModel): # _invoke() is a universal entry point for calling any model. # In the LLM class, for example, it returns generated text. def _invoke(): # Implements the call's specific logic, including handling input/output transformation, streaming, token counting... # ... Other functionsSimplified Configuration with YAML
Using a designated DSL, we set up model suppliers and models in a declarative way. This clarity in the codebase standardizes adding new models and makes supplier and model parameters more readable and easy to understand.
provider: anthropicdescription: en_US: Anthropic’s powerful models, such as Claude 2 and Claude Instant.supported_model_types:- llm#... credential_form_schemas: - variable: anthropic_api_key label: en_US: API Key type: secret-input# ... Other variablesFront-End Independence
Models are now entirely defined and set up on the backend, eliminating the need for front-end changes. This separation of model logic from UI design makes the code more modular and accelerates the development cycle.
Dynamic Addition
The model supplier configuration interface has been improved. Now, more specific model category tags can be viewed, and models integrated through Runtime can be dynamically added to the list. For instance, adding Google Gemini:
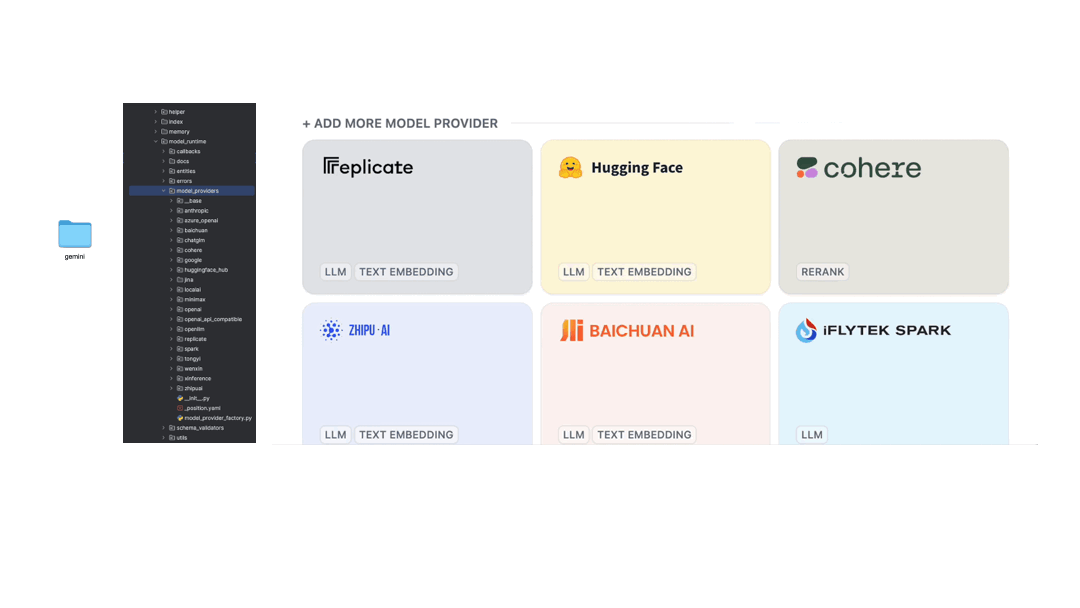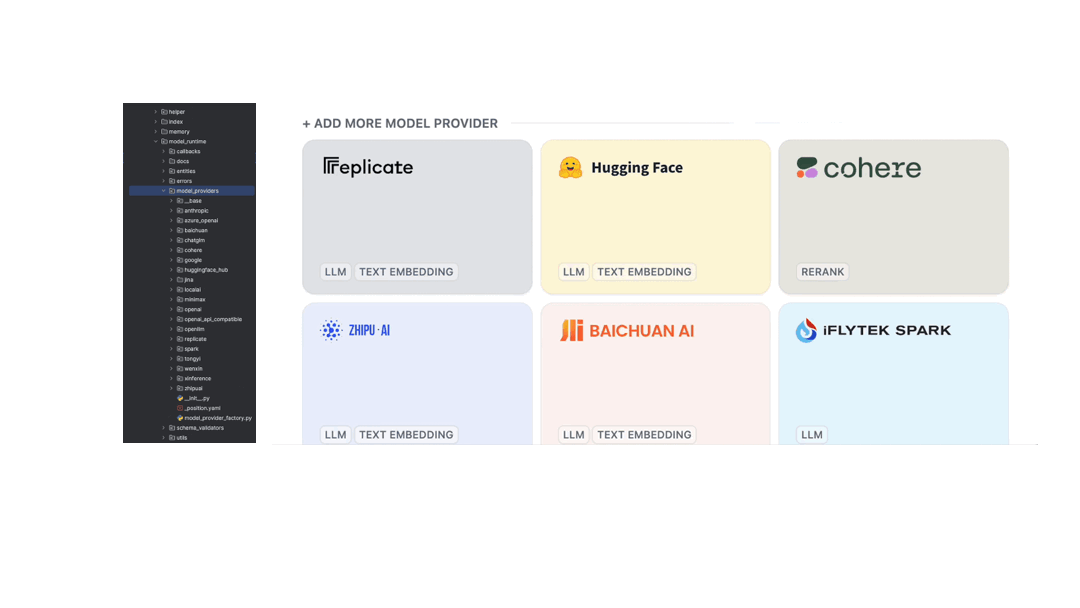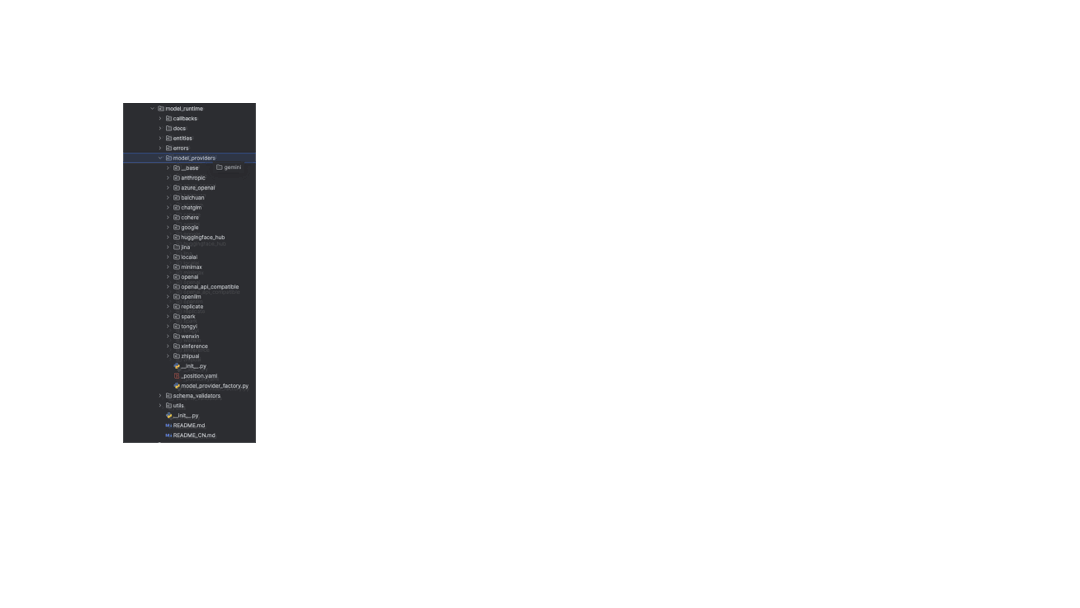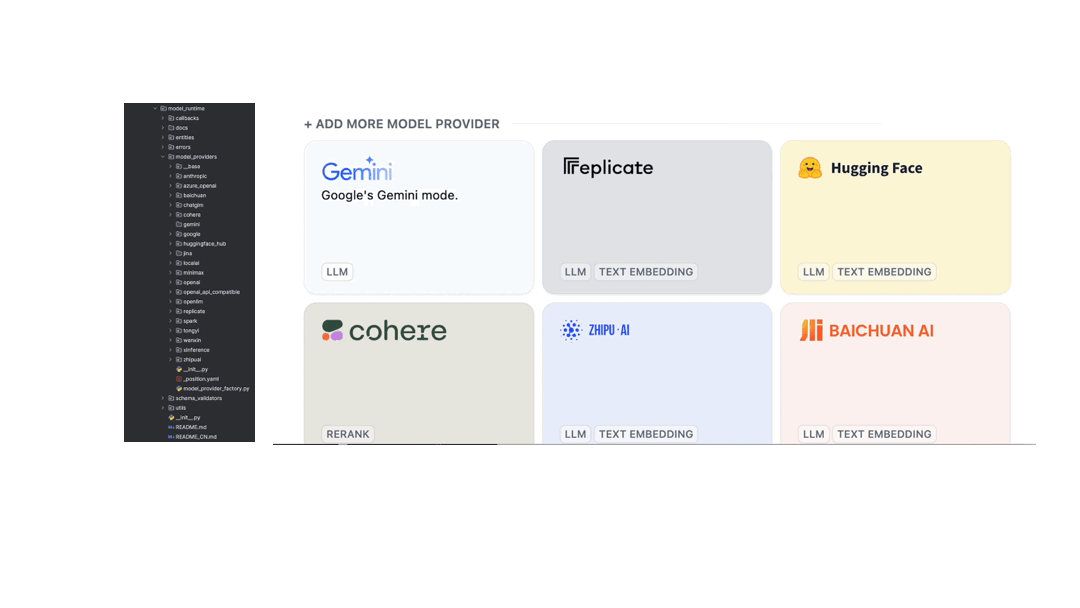
The Road Ahead
On this journey, we want to give a shoutout to trailblazers like LangChain and LlamaIndex. Their groundbreaking work and insights were key to our successful launch of version 0.1.
This major structural revamp shows our dedication to innovation and top-notch quality. We're aiming for it to help us better serve our users and the developer community, as well as keep us ahead in the competitive market. We're pumped about this makeover, and we hope our developers, who've been with Dify from the start, share our enthusiasm.
Related articles
- Product
Now on Dify Marketplace: Qubrid AI Brings Multi-Model Access to Every Dify Workflow
Install the Qubrid AI plugin on Dify to unlock unified access to DeepSeek, Kimi, Qwen, MiniMax, GLM, and more, all through one API key.

 Qubrid AI & Dify
Qubrid AI & Dify - Product
Grounding Dify Agents in Real Data: MongoDB Atlas and Voyage AI Are Now Native to Dify RAG Workflows
Dify and MongoDB make it easier to build grounded AI agents that retrieve, reason over, and act on real business data, without stitching together custom RAG infrastructure from scratch.
 MongoDB & Dify
MongoDB & Dify - Product
Dify Creator Center & Template Marketplace: Share Your Workflows
Dify’s new Creator Center and Template Marketplace let creators publish workflow templates and users discover and one-click adopt them, with optional PartnerStack affiliate linking to earn recurring commissions from subscriptions driven by template links.
Dify - Product
Try OpenAI, Claude, Gemini & Grok Free on Dify Cloud
Supports OpenAI, Claude, Gemini, and Grok. Try curated templates with zero configuration.
Dify