










Dify.AI v0.3.31: Surpassing the Assistants API – Dify's RAG Demonstrates an Impressive 20% Improvement
Dify.AI's latest update enhances its RAG technology, boosting QA efficiency in LLMs. It introduces hybrid search, a semantic rerank model, and multi-path retrieval, demonstrating significant performance improvements and a notable edge over OpenAI's Assistants API.

In the latest update of Dify.AI's dataset module, we've enhanced the Retrieval-Augmented Generation (RAG) technology, pivotal for vector search, to boost the question-answering proficiency of Large Language Models (LLMs). Key upgrades and optimizations include:
- Hybrid Search: We've broadened dataset upload capabilities with multiple search options: vector search, full-text search, and a novel hybrid search that melds the strengths of both methods.
- Rerank Model: This new model enables semantic re-ranking of search results from various technologies, pinpointing answers that most accurately align with user queries. This feature is user-configurable in the search settings.
- Multi-path Retrieval: Tailored for knowledge base Q&A using multiple datasets, this feature concurrently considers all relevant datasets. This ensures the extraction of the most pertinent text segments from each dataset.
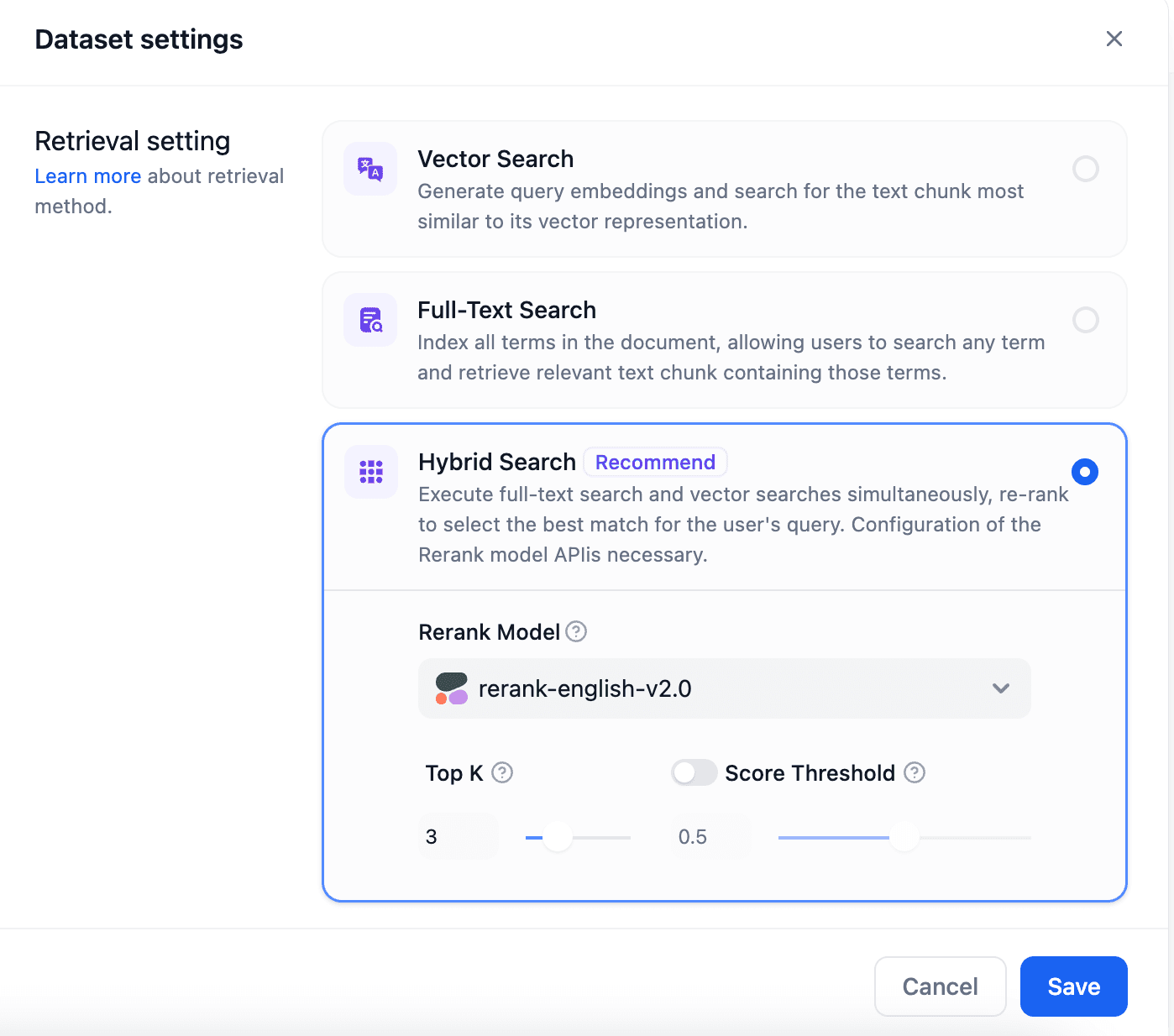
Both hybrid search and multi-path retrieval now automatically incorporate a Rerank model configuration. This is accessible via the settings page under Model Provider, with the Cohere Rerank currently supported and additional Rerank models slated for future release.For more in-depth details on these features, please consult the Official Help Documentation.
These approaches have improved the accuracy of QA targeting and elevated the overall QA experience. In Dify.AI's latest version, we extensively tested the enhanced RAG. The results revealed a notable enhancement in system performance, including a 20% rise in retrieval hit rate, and a distinct edge over OpenAI's Assistants API.
Dify.AI's 20% Performance Improvement with RAG
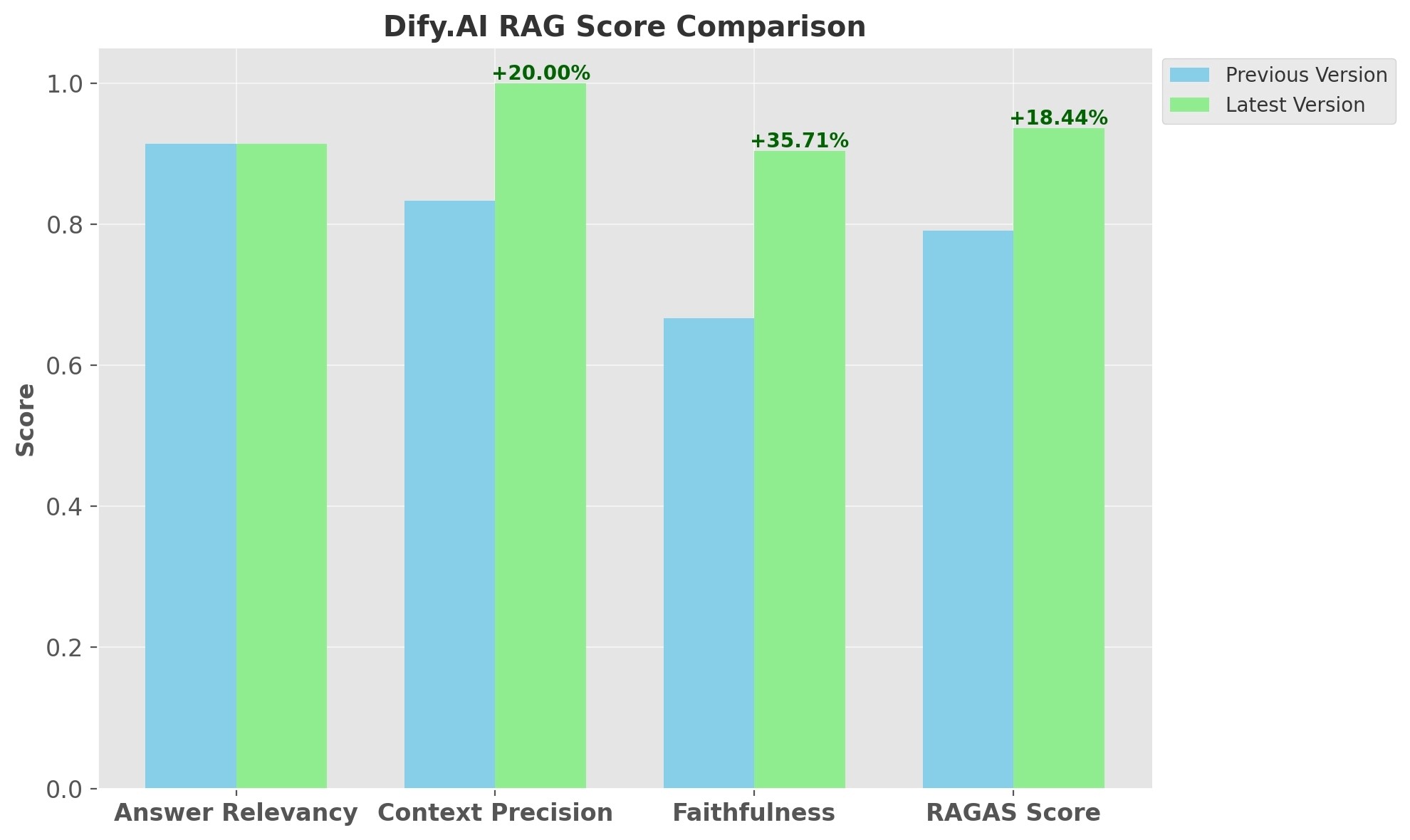
In our recent tests, we utilized the Ragas evaluation framework, specifically designed to assess the RAG pipeline. This framework offers a suite of tools and metrics for evaluating RAG system aspects. We focused on three primary metrics:
- Answer Relevancy: Measures how relevant an answer is to the posed question, evaluating the quality and applicability of answers produced by LLMs.
- Context Precision: Assesses the relevance of the retrieved context to the question. This metric reflects the quality of the retrieval process, ensuring the extracted information is pertinent to the query. The test values span from 0 to 1, with higher values denoting superior precision.
- Faithfulness: Evaluates the factual accuracy of the generated answer in relation to the provided context. This metric also encompasses detecting “hallucination” phenomena in answers. Values range from 0 to 1, with higher scores indicating greater consistency and fewer hallucinations.
Additionally, Ragas includes other metrics like Context Recall for an all-encompassing assessment of RAG's effectiveness. The Ragas Score, an aggregate of these metrics, serves as a comprehensive measure of QA system performance.
Our test outcomes are noteworthy: Ragas Score rose by 18.44%, Context Precision by 20%, and Faithfulness by 35.71%.
Note: Answer Relevancy is linked to LLM performance. Since the same LLM was employed in these tests, the scores were almost identical.
Dify.AI vs Assistants API: A Comparative Overview
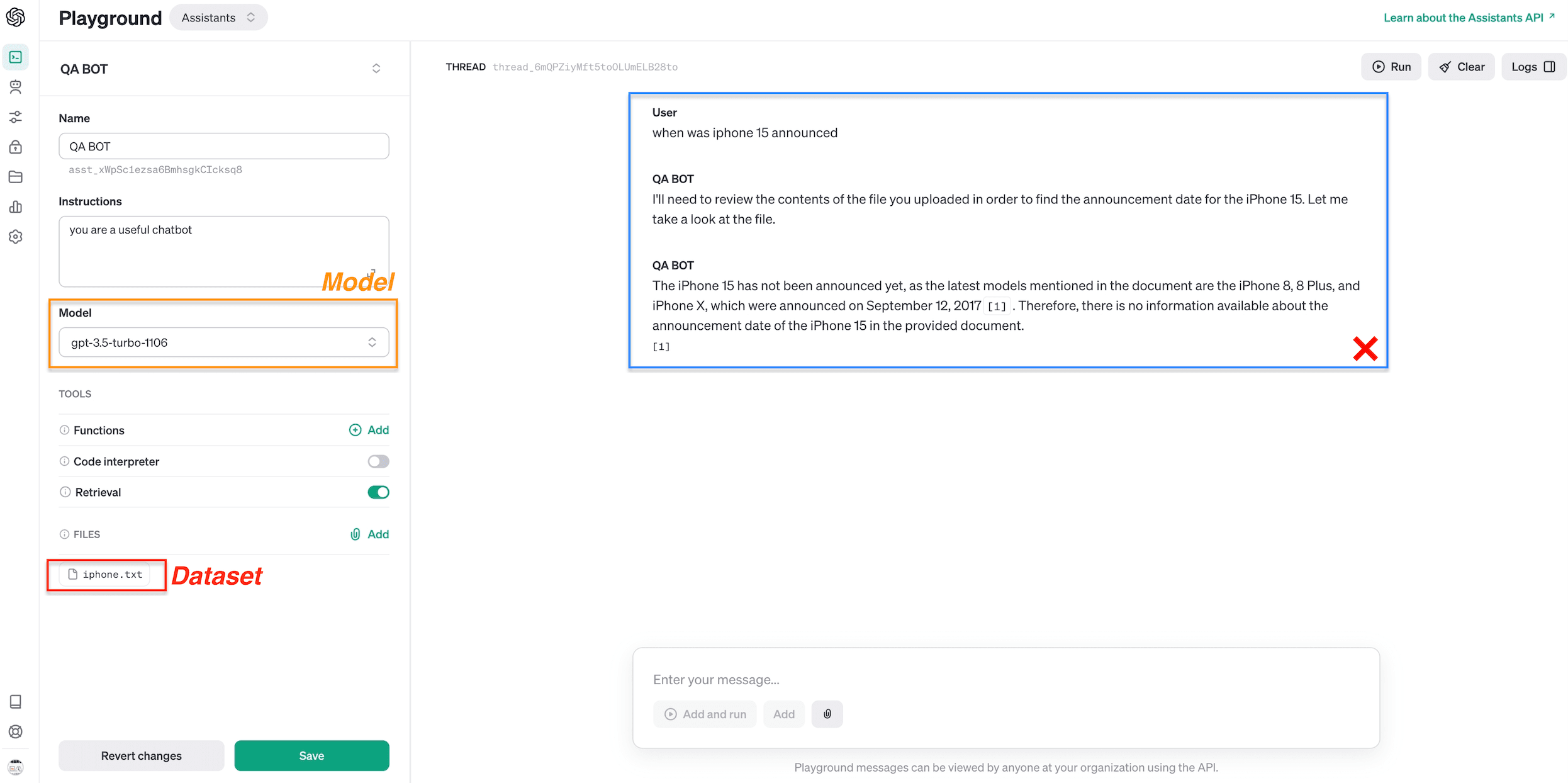
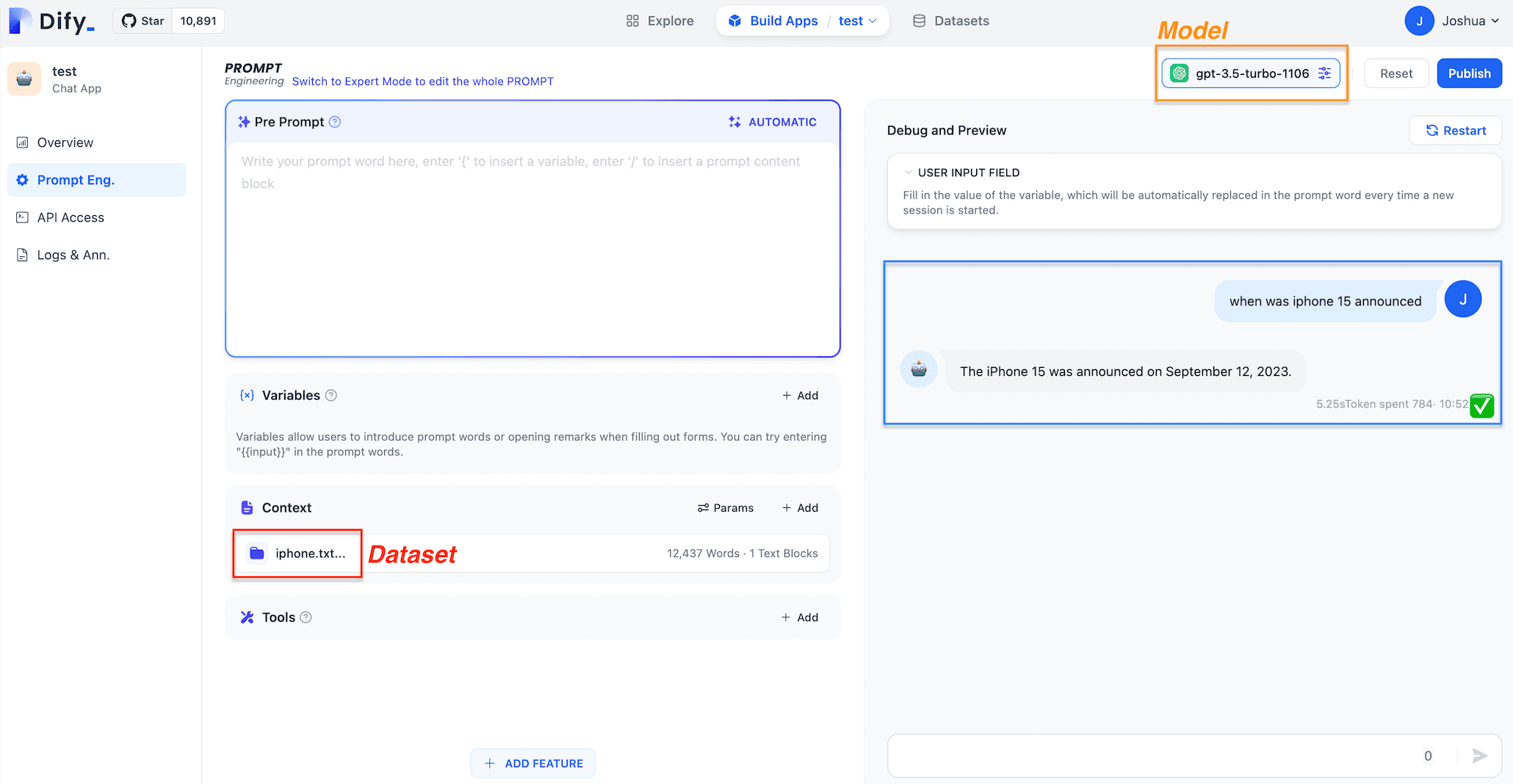
Dify.AI distinguishes itself from OpenAI's Assistants API by supporting a wider array of models, notably including open-source models from Hugging Face and Replicate platforms. Unlike the Assistants API, which utilizes models like gpt-3.5-turbo-1106, Dify.AI leverages its advanced RAG technology for context-based accurate question answering.
For instance, when using the dataset "iphone.txt" that details the release dates and performance comparisons of various iPhone models, Dify.AI outperforms the Assistants API.
For the query, "when was iPhone 15 announced", the Assistants API was unable to extract the relevant information from the context, incorrectly inferring the absence of iPhone 15's release date in the dataset. In contrast, Dify.AI's RAG system accurately retrieved and provided the correct answer: "The iPhone 15 was announced on September 12, 2023."
A key highlight of Dify's RAG system is its open-source nature, inviting community contributions and fostering technology sharing. Developers are encouraged to star us on GitHub and join our collaborative efforts.
We're also excited to announce Dify.AI's support for the newly launched Claude 2.1 model. This model boasts a 200K token context, substantially minimizing hallucinations and inaccuracies in responses, which is crucial for developing more dependable AI applications. We invite you to experience these enhancements firsthand.
via @dify_ai
Related articles
- Release
Dify's Official CLI: difyctl Ships
Dify introduces CLI access, making it easy for Agents to call Dify apps with a single command.
 Dify
Dify - Release
Build · Share · Earn: Dify Creator Center And Template Marketplace Are Now Live
A unified platform for creators to publish and for users to discover, enabling workflows to be quickly reused and adopted at scale.
Dify - Release
Dify 1.14.1: Workflows Become a Team Asset
Move workflows from “built” to “continuously used and reused,” so AI can fit into enterprise processes.
Dify - Release
Dify 1.12.0 Summary Index: From fragmented retrieval to full context
Summary Index lets you attach summaries to chunks so related content is returned together.
Dify