










Hey, it’s Leilei from Dify! I’ve got some exciting news to share with you in our latest version 0.6.11. Our team collaborated with Firecrawl to add a new web data source to our knowledge base, and it worked really well. I’m excited to fill you in on the details and some other cool integrations we completed.
Bridge Between Web Data and Your RAG App
Firecrawl can turn websites into LLM-ready data by crawling and converting any website into clean markdown or structured data. This data is perfectly suitable for use when building your RAG application on Dify.
Getting Started
The new 'Sync from website' option is conveniently located on the Knowledge dashboard. To get started, simply configure your settings by obtaining an API key from Firecrawl. You'll receive 500 free credits (pages), which is suitable for anyone interested in exploring their cloud service.
On the other hand, Firecrawl also offers an open-source software (OSS) edition, empowering you to set up your own server and perform unlimited crawling and scraping. The OSS version can work efficiently with Dify as well. In this introduction, however, I will focus on the cloud edition.
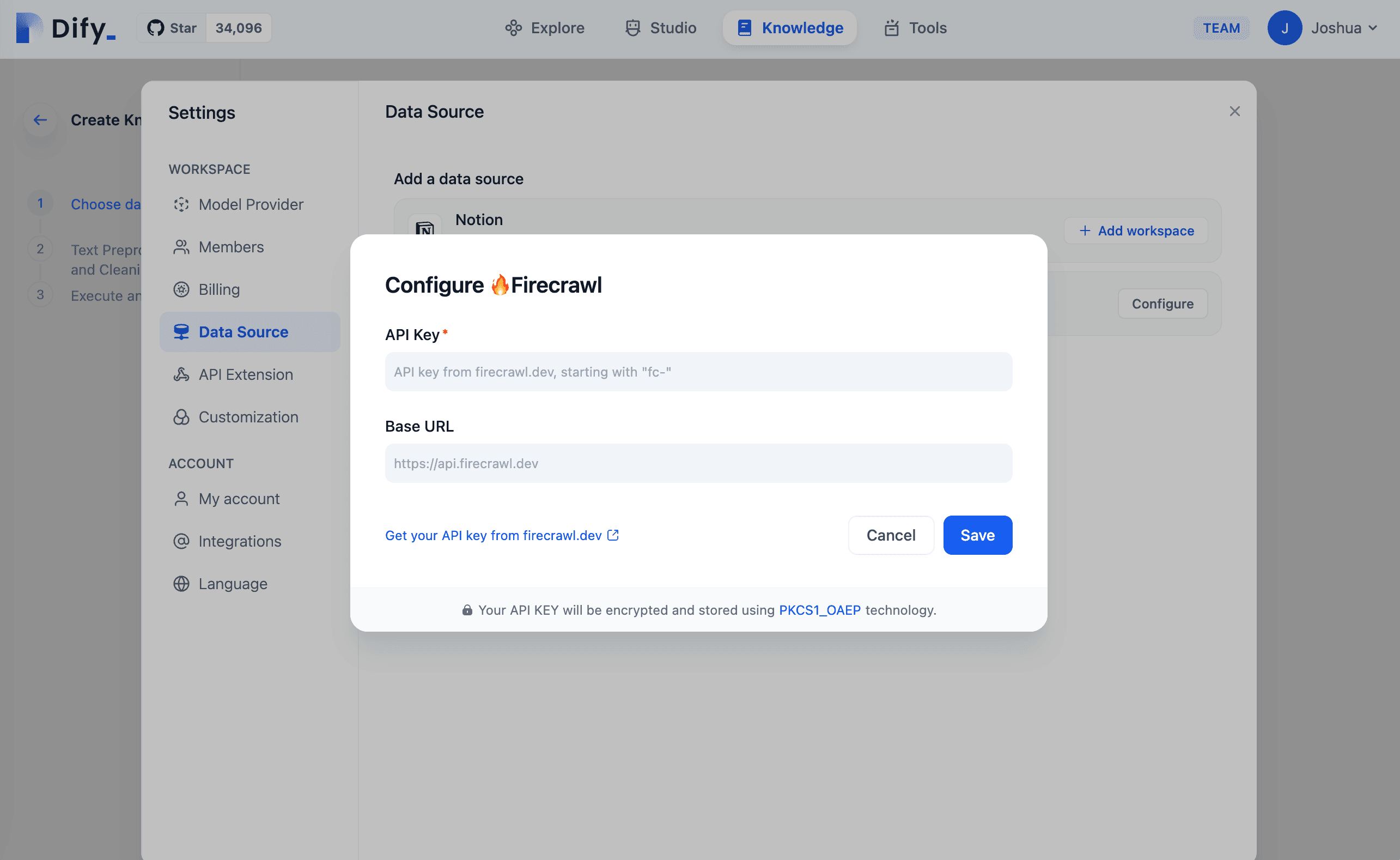
Easy Setup
Firecrawl crawls all accessible subpages, even without a sitemap, and returns a clean, structured markdown. In Dify, we provide some options for you to easily set according to your specific needs.
The 'Crawl sub-pages' option allows you to:
- Set the limit for the total number of sub-pages
- Set the max depth relative to the entered URL (Depth 0 scrapes only the entered URL, while depth 1 scrapes the URL and its immediate sub-pages)
These two options can cover most of your basic requirements. Additionally, we provide Exclude and Include path options to further refine your web crawling needs.
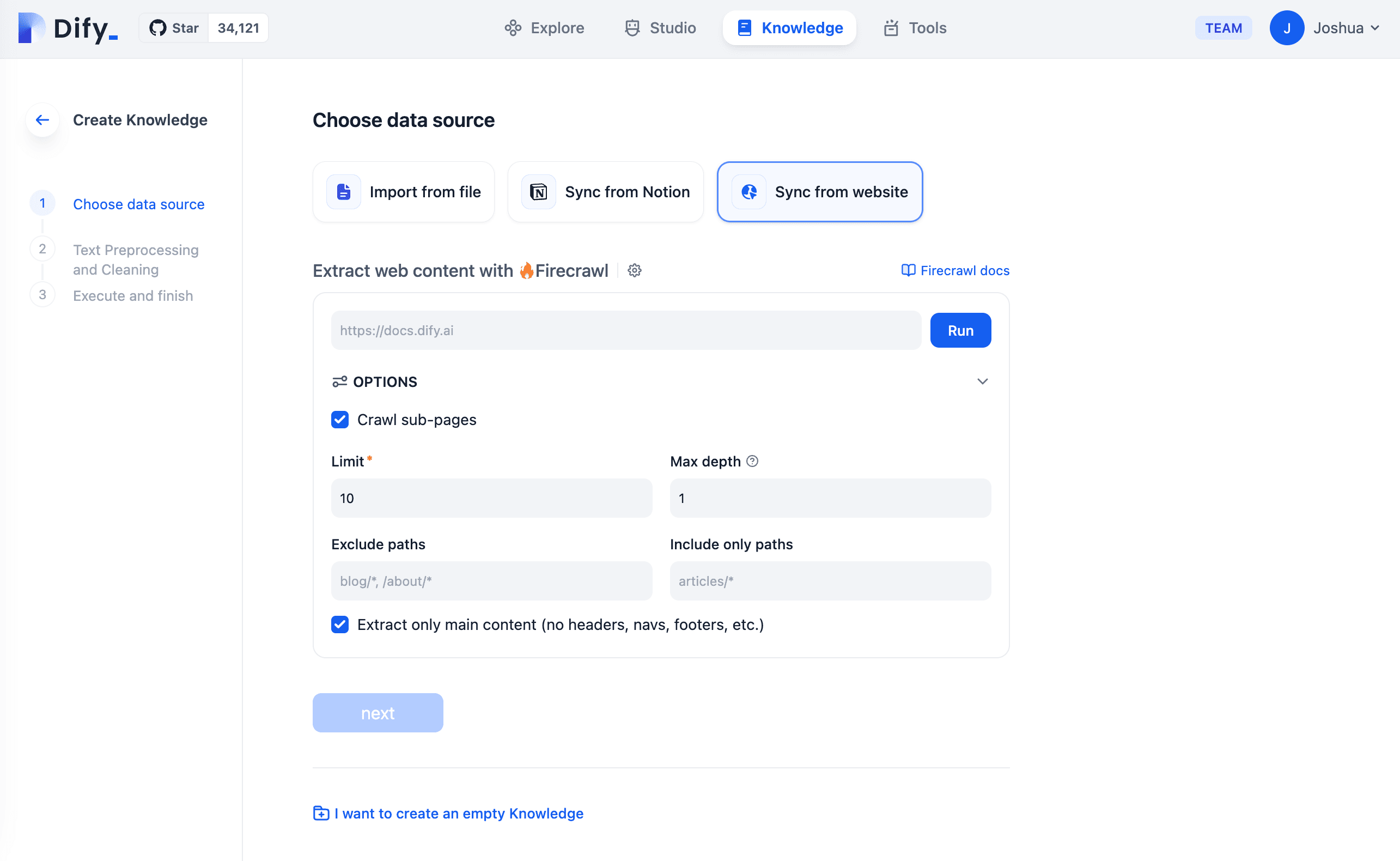
Data Embedding with Dify
Firecrawl efficiently crawls web pages in parallel, delivering results quickly. Once the crawling process is complete, you can easily select the desired pages of web data directly on Dify. The selected web data is then ready for further text preprocessing and cleaning steps. After these steps are completed, the data will be embedded and stored in Dify's vector DB as a new knowledge base.
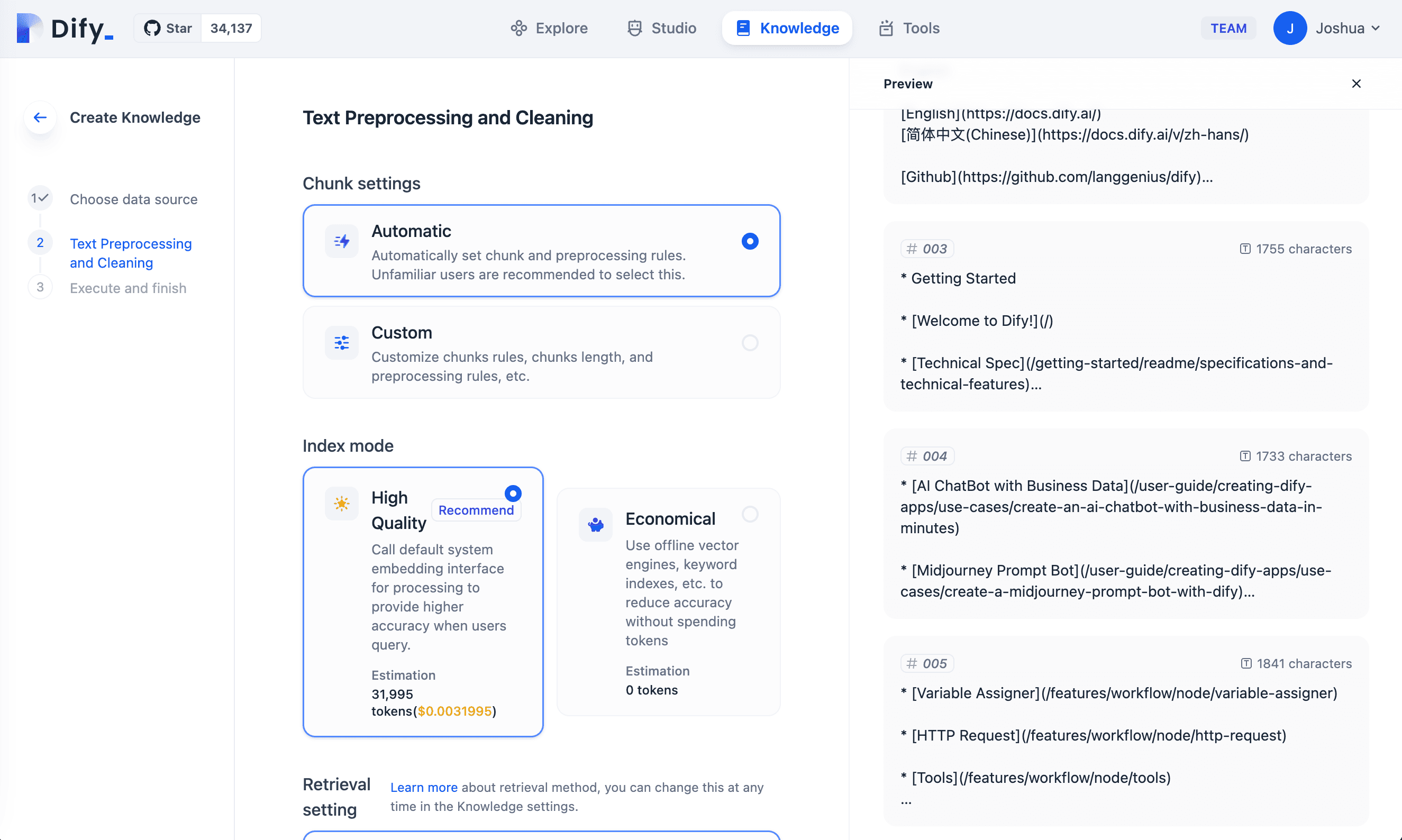
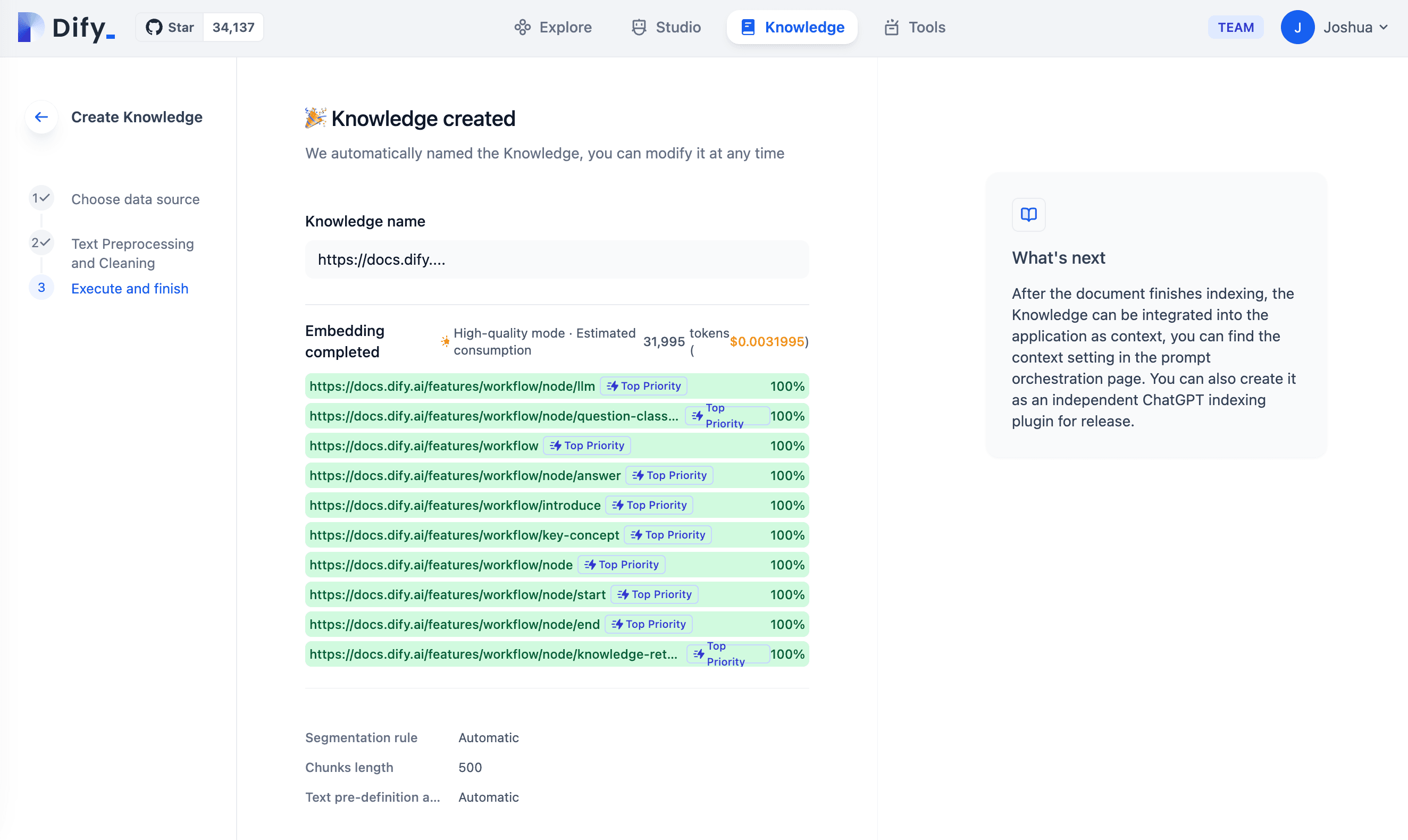
Ready for RAG Application
Now, you can create a RAG app that uses web data as contextual knowledge on Dify! These latest data can be leveraged even more effectively in business scenarios, such as monitoring market trends, staying updated with news, and tracking competitor information.
Boosting Workflow Collaboration
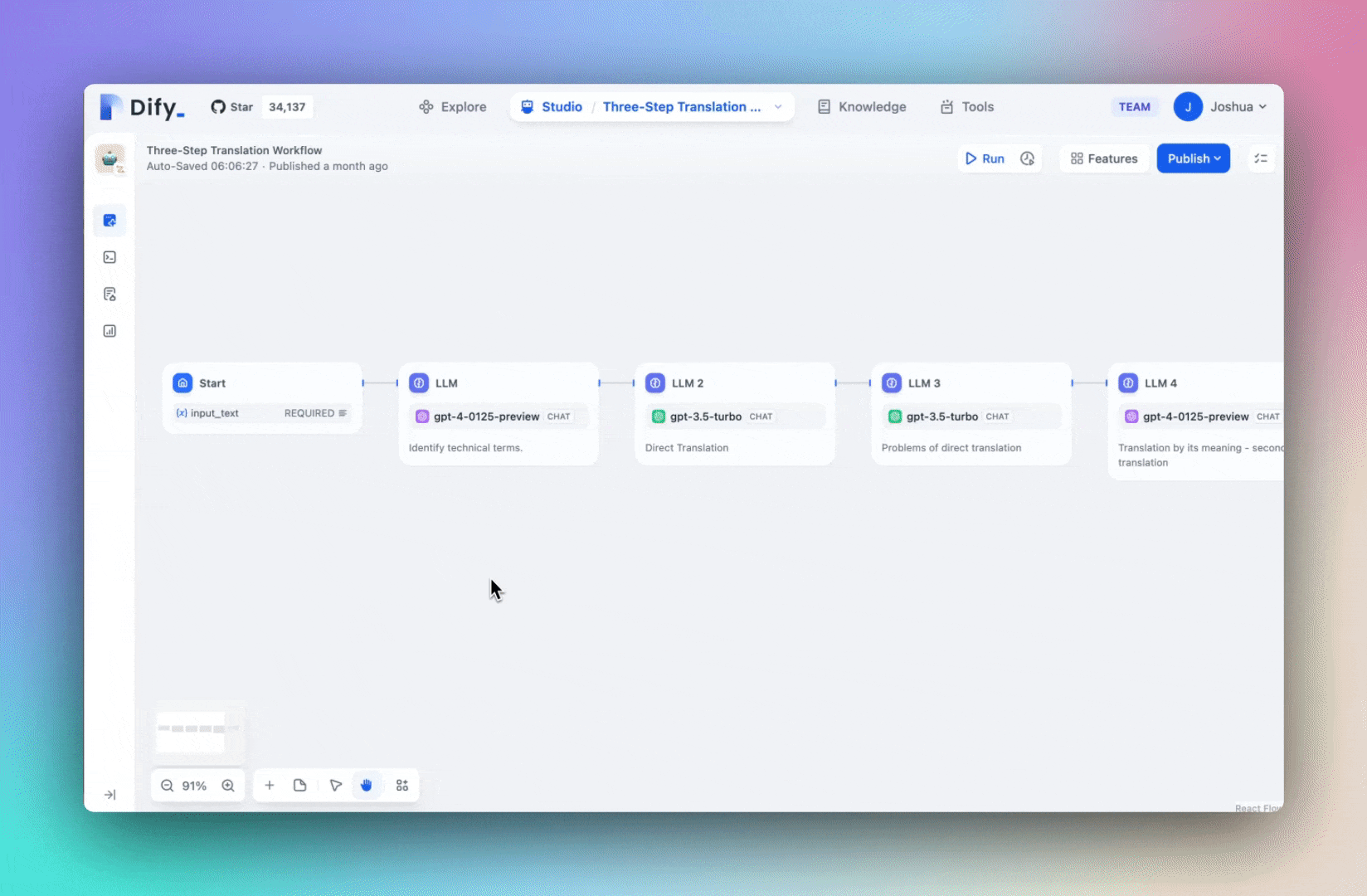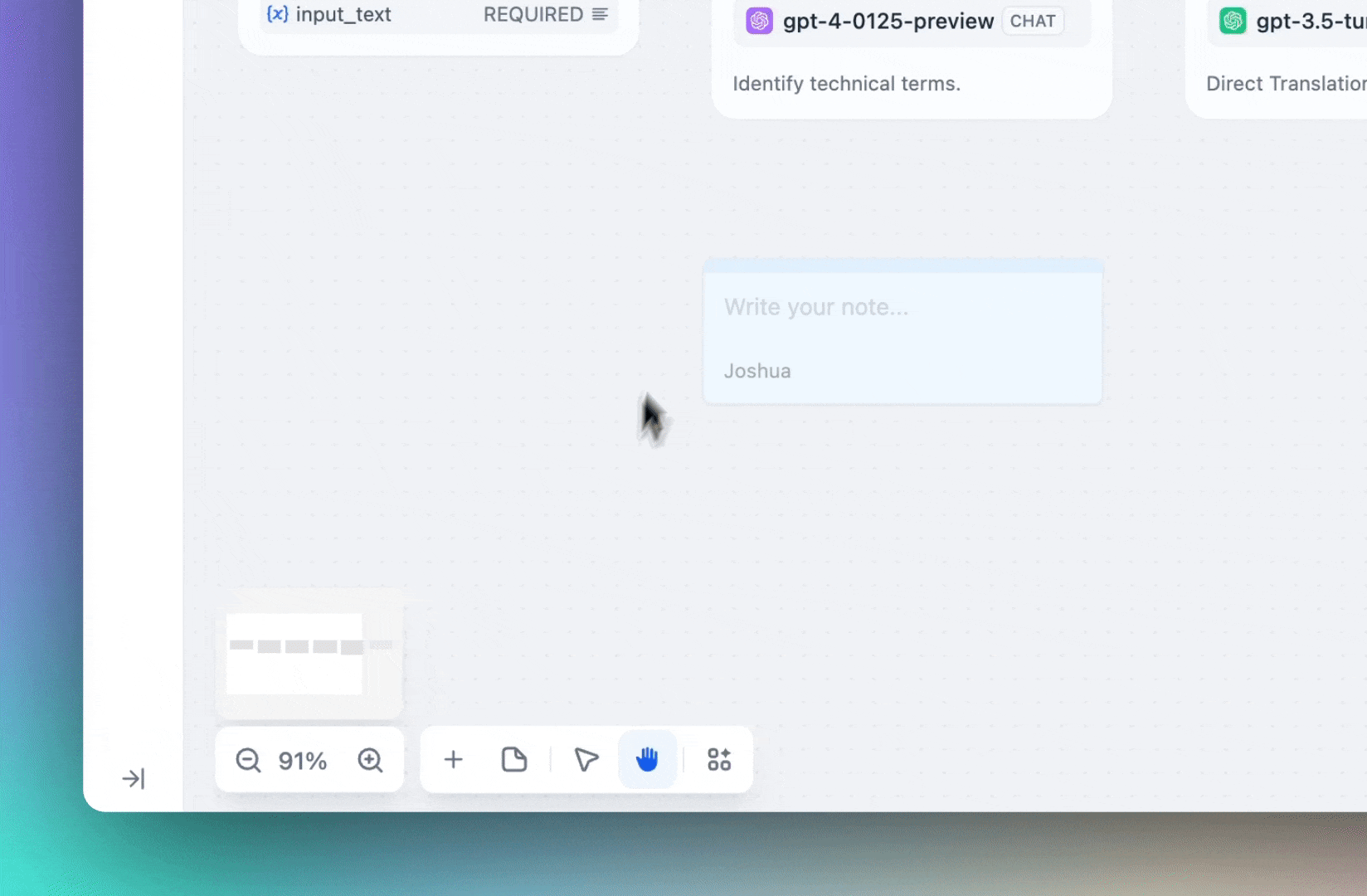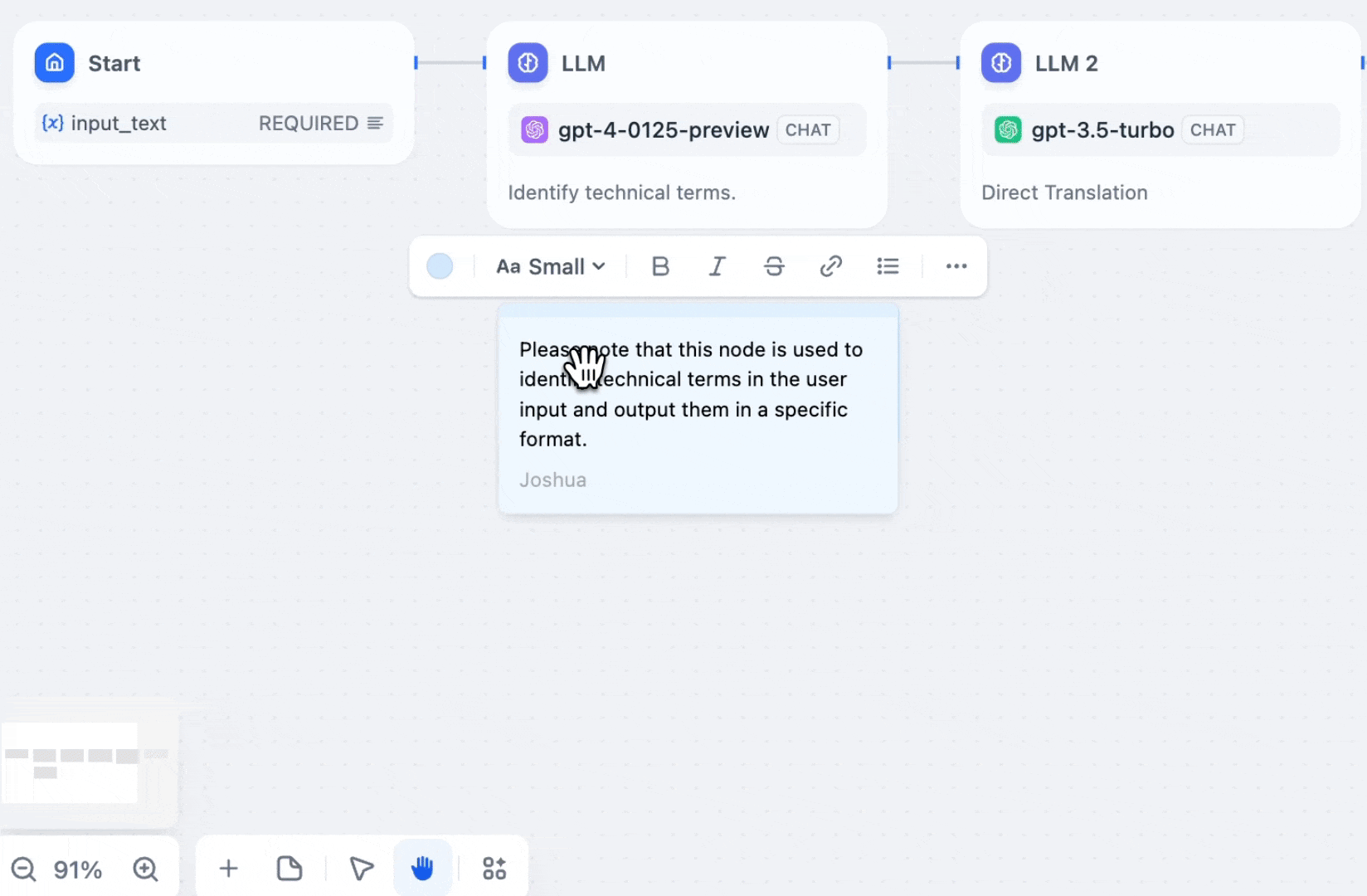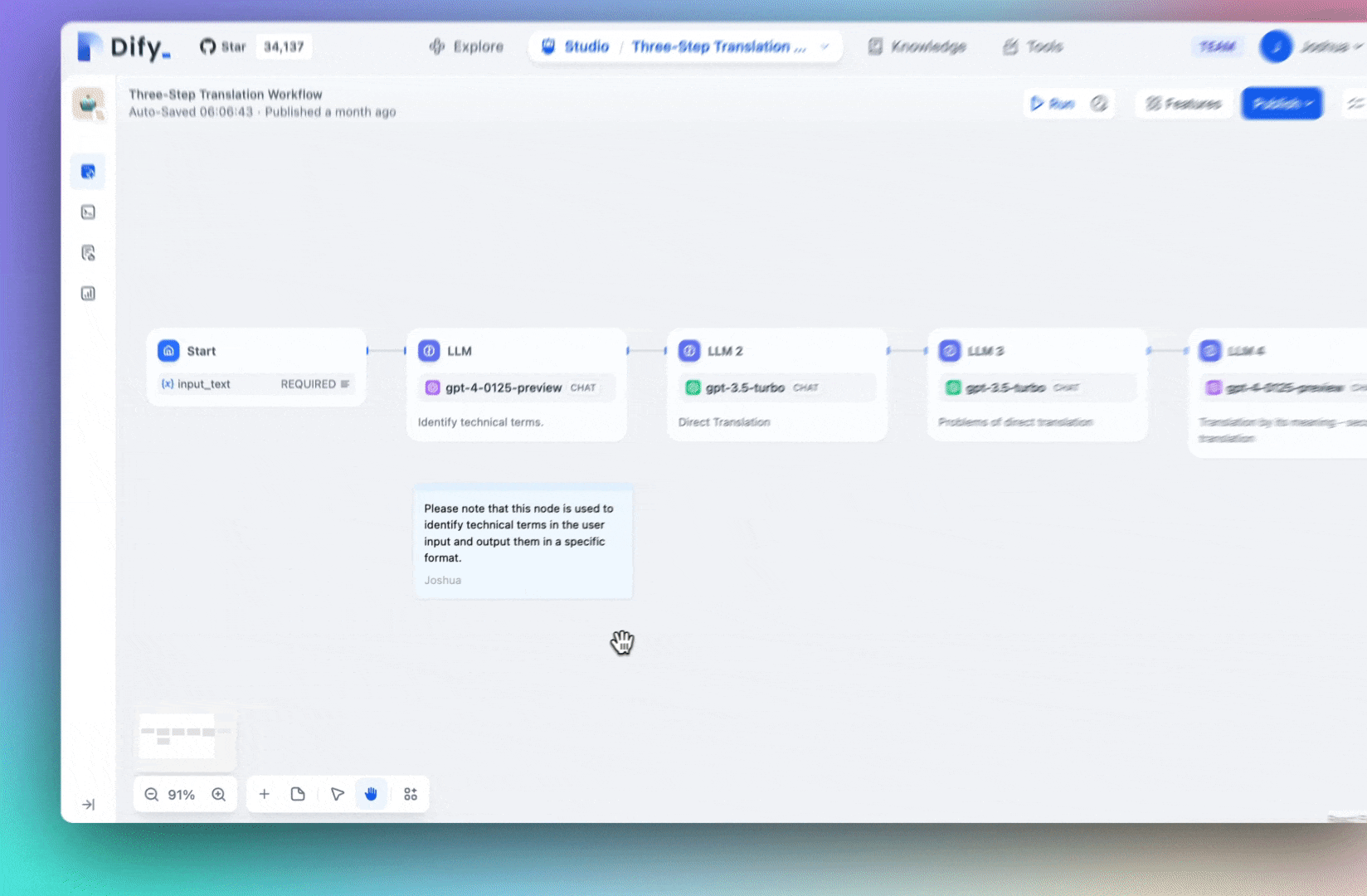
In addition to integrating web data sources for Dify Knowledge, Dify v0.6.11 has also introduced improvements to facilitate collaboration when building your workflow.
You can now add notes at any point on the Workflow orchestration page, making it easier to share ideas and work together with your team. When you share the Workflow as a DSL file, these notes will be preserved, allowing you to effectively communicate your creative ideas with your team and the community.
Added Benefits
Besides those two major updates I've already shared above, here are some additional highlights you might be interested in:
- Added three new model providers and updated models for four, including the Jina-CLIP-v1 embedding model.
- Integrated new vector databases from TiDB, Chroma, and Tencent cloud into your RAG engine.
- Dependency Management: Transitioning from pip to poetry for better package management, offering faster parallel dependency downloads and superior conflict resolution.
- New ‘Editor’ User Role in Dify Workspace: Editors can now add and edit apps within the workspace.
Join the community
We'd love to hear your thoughts on these updates! Feel free to share your perspective with us by mentioning @dify_ai or @DifyJapan on Twitter. We're always eager to learn from our users and improve our product. Our Discord channel is also open for you to engage with the community, share your ideas, and get the latest news.
For a comprehensive list of changes, please refer to the release log on GitHub.
Related articles
- Product
Grounding Dify Agents in Real Data: MongoDB Atlas and Voyage AI Are Now Native to Dify RAG Workflows
Dify and MongoDB make it easier to build grounded AI agents that retrieve, reason over, and act on real business data, without stitching together custom RAG infrastructure from scratch.

 MongoDB & Dify
MongoDB & Dify - Product
Dify Creator Center & Template Marketplace: Share Your Workflows
Dify’s new Creator Center and Template Marketplace let creators publish workflow templates and users discover and one-click adopt them, with optional PartnerStack affiliate linking to earn recurring commissions from subscriptions driven by template links.
Dify - Product
Try OpenAI, Claude, Gemini & Grok Free on Dify Cloud
Supports OpenAI, Claude, Gemini, and Grok. Try curated templates with zero configuration.
Dify - Product
The Human Input Node: Bringing Human Judgment into Automated Workflows
Dify v1.13.0 adds a Human Input node so workflows can pause for human review and resume with approved, edited, or rerouted decisions.
 Leilei
Leilei