










Dify v0.8.0: Accelerating Workflow Processing with Parallel Branch
We’ve enhanced Workflow with parallel processing capabilities in Dify v0.8.0. It can now run multiple branches simultaneously, enabling the parallel execution of various tasks. This new model significantly improves execution efficiency, helping LLM applications handle complex tasks more quickly and flexibly.

Dify Workflow is widely used for its user-friendly setup and powerful functionality. However, previous versions executed steps serially, waiting for each node to complete before moving to the next. While providing a clear structure, this slowed processing for complex tasks, increasing latency and response times.
Dify v0.8.0 addresses these limitations by introducing parallel processing capabilities. Workflow can now execute multiple branches concurrently, enabling simultaneous processing of different tasks. This significantly improves execution efficiency, allowing LLM applications to handle complex workloads faster and with greater flexibility.
Creating parallel branches
To define parallel branches in a Workflow:
- Hover over a node
- Click the + icon that appears
- Add different node types
The branches will execute in parallel and combine their outputs. Refer to the documentation for detailed instructions.
Workflow includes several parallel scenarios. Experiment with these to speed up processes. If you’ve built Workflows in earlier versions, consider restructuring them with parallel patterns to improve performance.
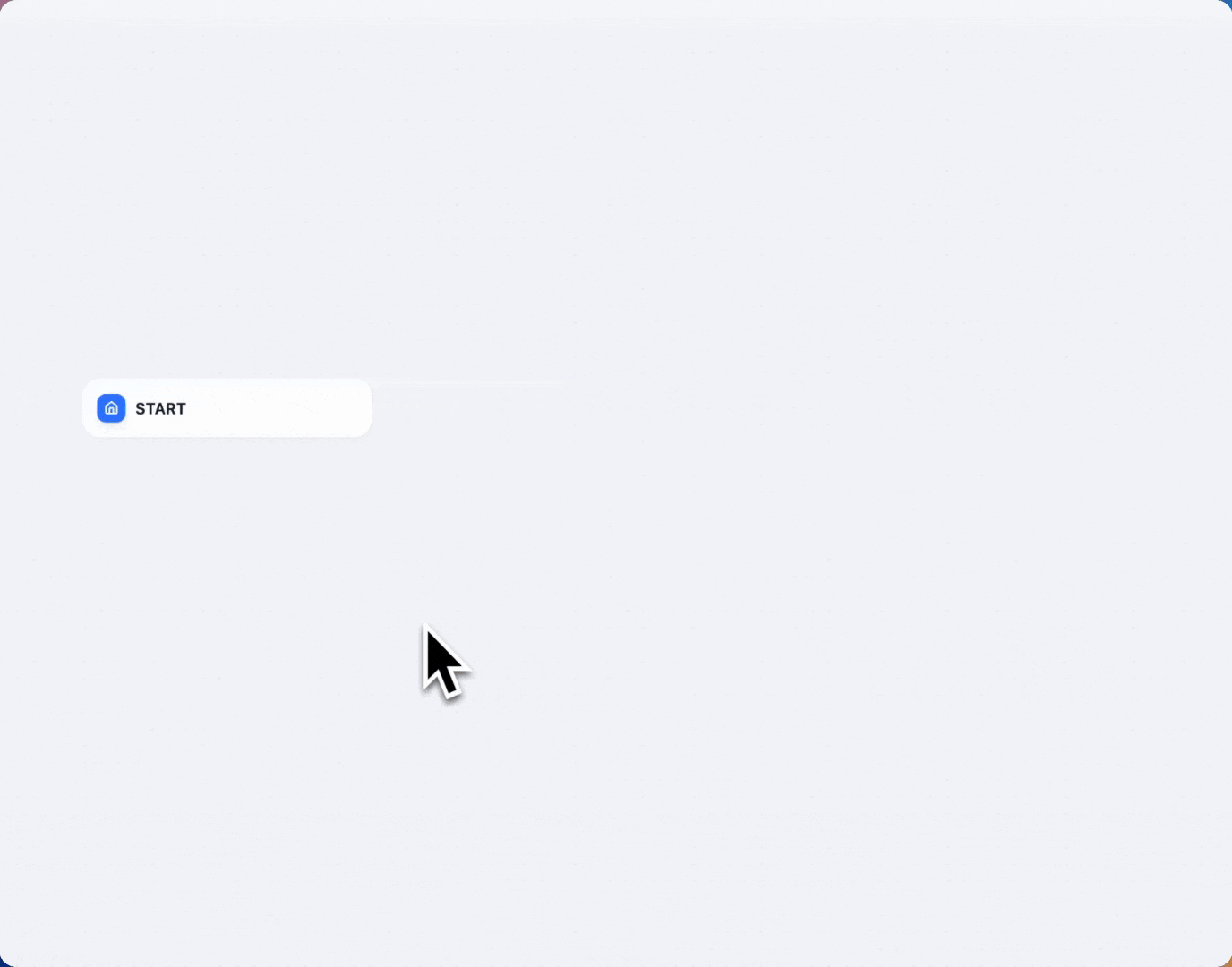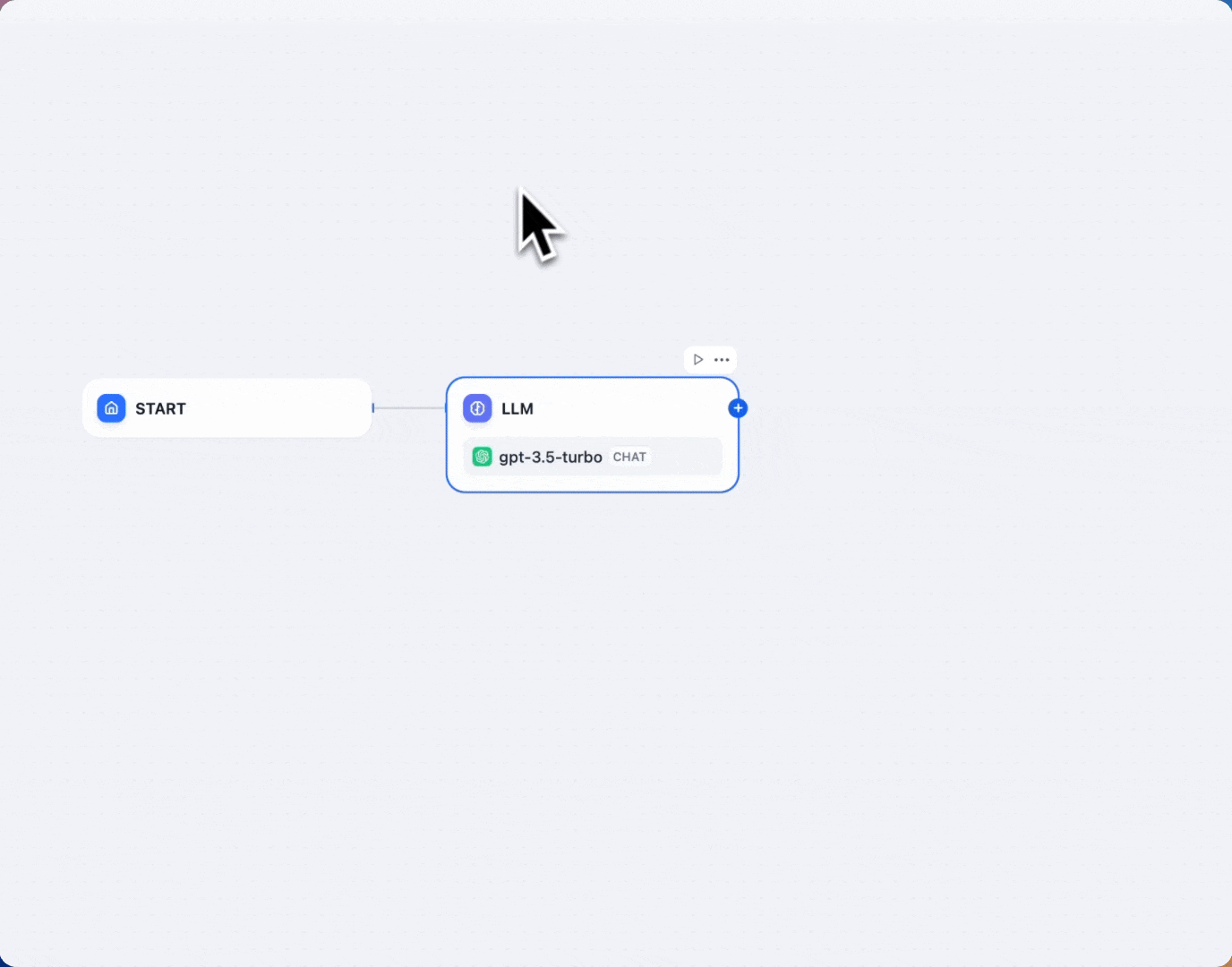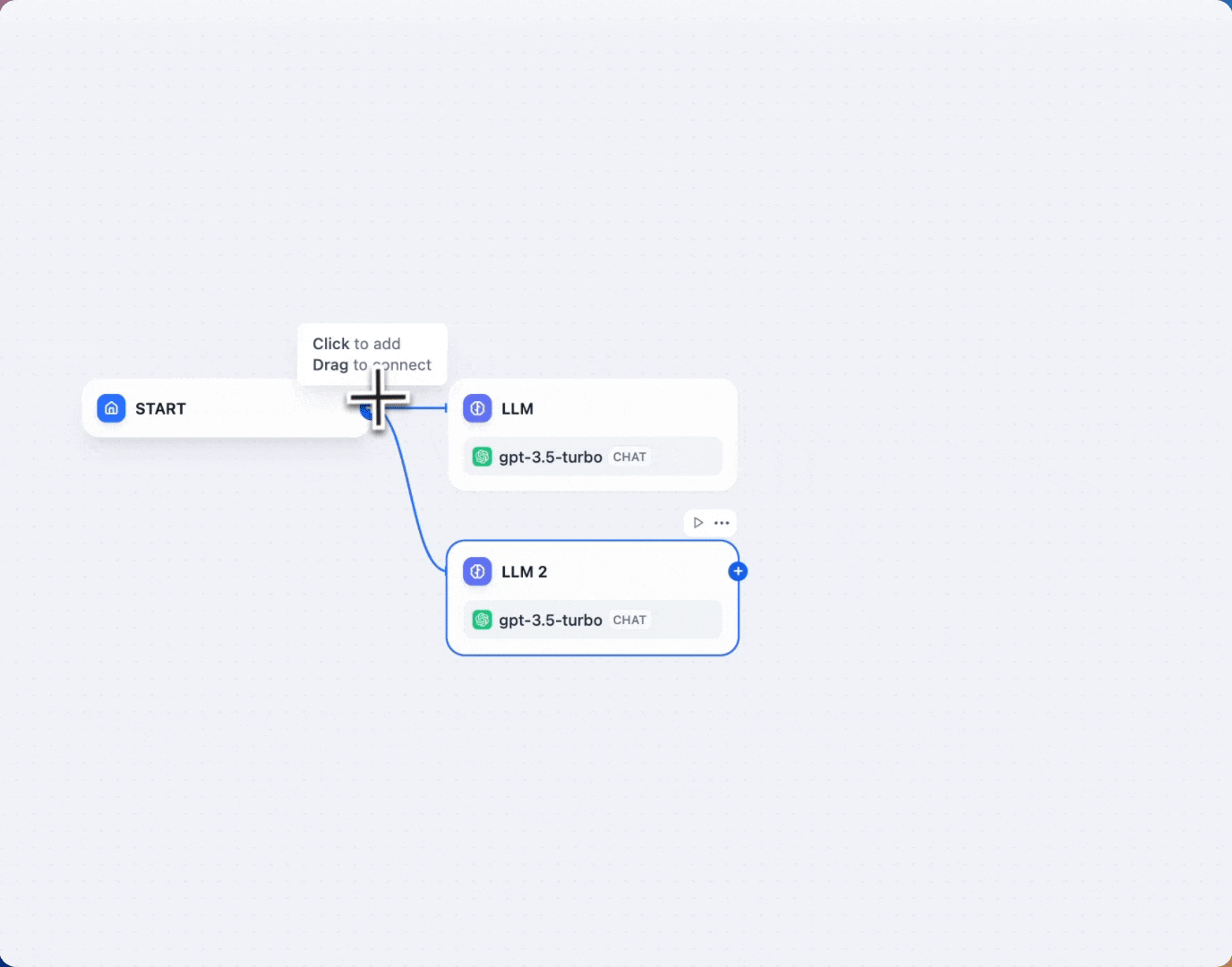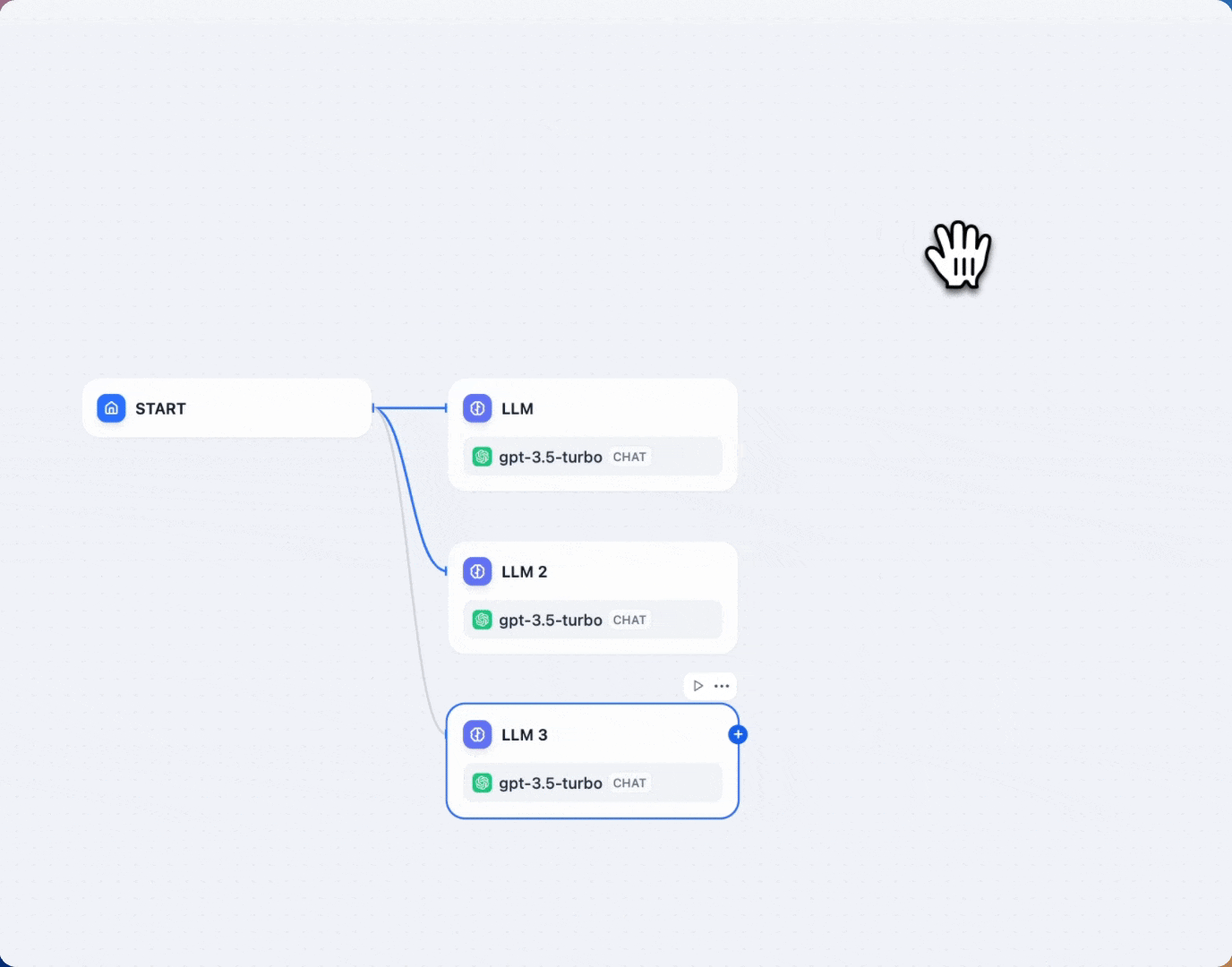
Simple parallelism
For basic scenarios, create multiple parallel branches from a fixed node (e.g., the start node). This setup handles similar subtasks concurrently, such as translations or model comparisons. The video below shows simple parallelism in a model comparison workflow:
Nested parallelism
Nested parallelism allows for multi-level parallel structures within a Workflow. From an initial node, it branches into multiple parallel paths, each containing its own parallel processes. The "Science Writing Assistant" example shows two nesting levels:
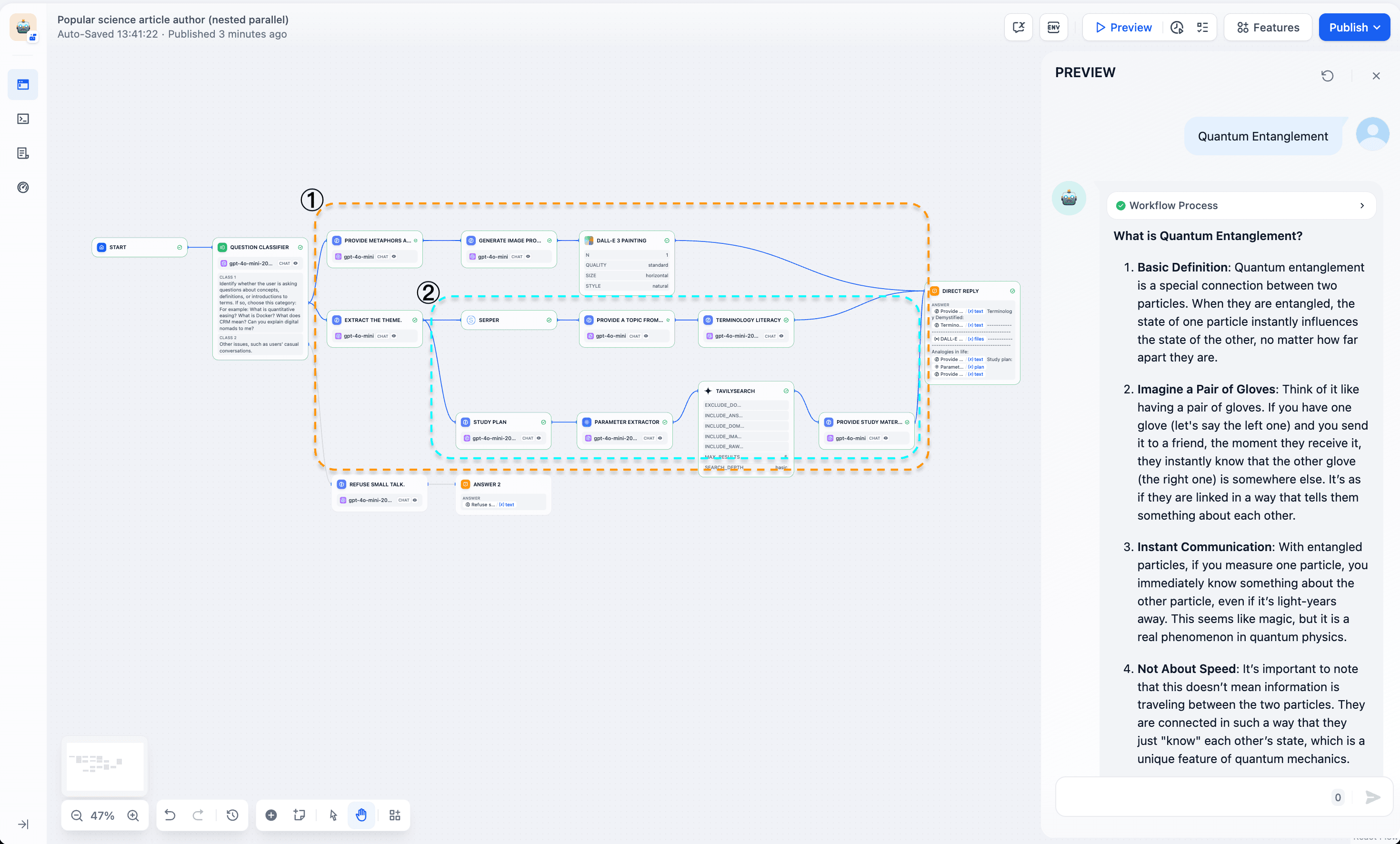
- First level (Box 1): From the question classifier, two main branches emerge:
a. Concept explanation (Box 1)
b. Handling off-topic conversations ("Refuse small talk" branch)
The concept explanation branch (Box 1) includes:
- Metaphors and analogies branch for enhanced concept understanding
- Theme extraction | Second level nesting (Box 2) for detailed concept analysis and content generation - Second level (Box 2): The theme extraction branch performs two parallel tasks:
a. Extract theme and search (Extract the theme -> Serper) for background information
b. Extract theme and generate study plan (Study Plan -> Parameter Extractor -> TavilySearch)
This multi-level nested parallel structure is ideal for complex, multi-stage tasks like in-depth concept analysis and science communication content creation. It processes different concept aspects concurrently, including basic explanations, analogies, background research, and learning plans, improving processing efficiency and output quality.
Iterative Parallelism
Iteration parallelism involves parallel processing within a loop structure. The "Stock News Sentiment Analysis" example demonstrates this approach:
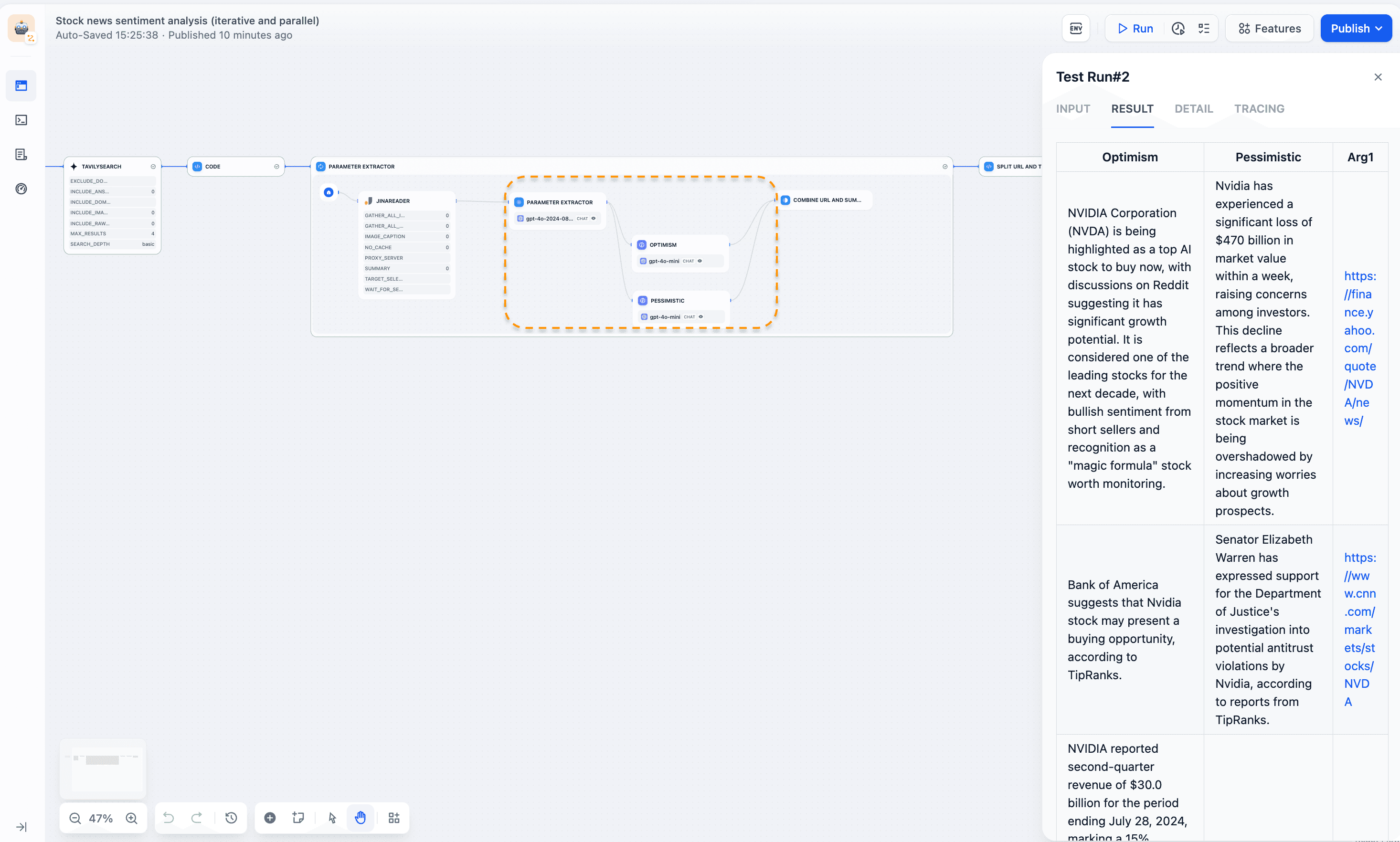
- Setup: Search and extract multiple news URLs for a specific stock.
- Iterative processing: For each URL, execute in parallel:
a. Content retrieval: Use JinaReader to scrape and parse webpage content.
b. Opinion extraction: Identify optimistic and pessimistic views using a parameter extractor.
c. Opinion summarization: Use two independent LLM models to summarize optimistic and pessimistic views concurrently. - Combine results: Consolidate all findings into a single table.
This method efficiently processes large volumes of news articles, analyzing sentiment from multiple perspectives to help investors make informed decisions. Parallel processing within iterations accelerates tasks with similar data structures, saving time and improving performance.
Conditional parallelism
Conditional branch parallelism runs different parallel task branches based on conditions. The "Interview Preparation Assistant" example shows this setup:
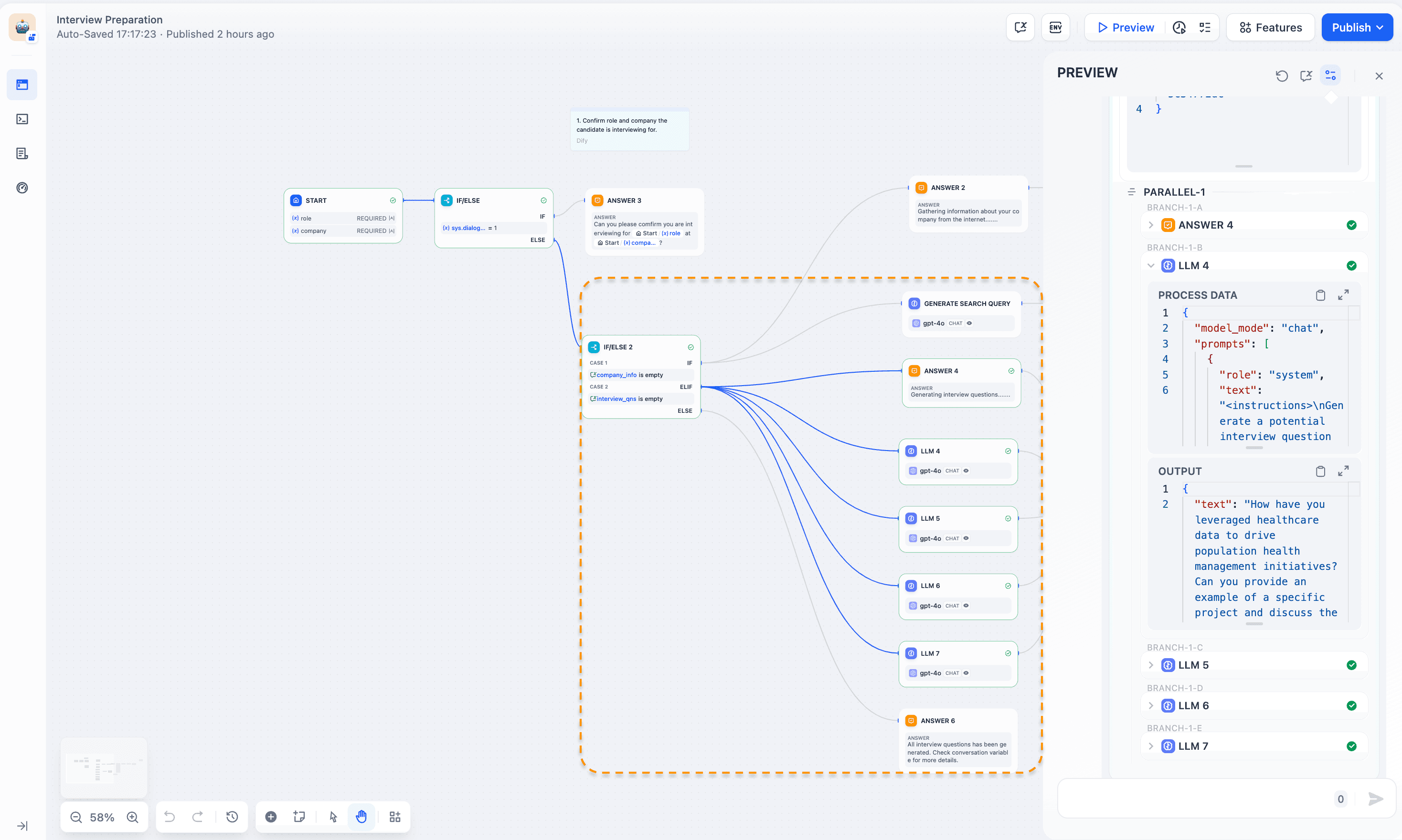
- Main condition (IF/ELSE node): Splits process based on dialogue_count:
a. First dialogue: Confirm interview role and company
b. Later dialogues: Enter deeper processing - Secondary condition (IF/ELSE 2 node): In later dialogues, branches based on existing company info and interview questions:
a. Missing company info: Run parallel tasks to search company, scrape webpage, summarize company info
b. Missing interview questions: Generate multiple questions in parallel - Parallel task execution: For question generation, multiple LLM nodes start at the same time, each creating a different question
This IF/ELSE structure lets Workflow flexibly run different parallel tasks based on current state and needs. (The question classifier node can serve a similar function.) This improves efficiency while keeping things orderly. It suits situations needing simultaneous complex tasks based on various conditions, like this interview prep process.
Benefiting from Workflow parallelism
These four parallel methods (simple, nested, iterative, and conditional) boost Dify Workflow's performance. They support multi-model teamwork, simplify difficult tasks, and adjust execution paths dynamically. These upgrades increase efficiency and broaden applications, handling tough work situations better. You can quickly try these new features in the matching templates on the explore page.
We will continue to enhance Workflow, offering more powerful and flexible automation solutions. Stay tuned!
Related articles
- Product
Now on Dify Marketplace: Qubrid AI Brings Multi-Model Access to Every Dify Workflow
Install the Qubrid AI plugin on Dify to unlock unified access to DeepSeek, Kimi, Qwen, MiniMax, GLM, and more, all through one API key.

 Qbrid AI & Dify
Qbrid AI & Dify - Product
Grounding Dify Agents in Real Data: MongoDB Atlas and Voyage AI Are Now Native to Dify RAG Workflows
Dify and MongoDB make it easier to build grounded AI agents that retrieve, reason over, and act on real business data, without stitching together custom RAG infrastructure from scratch.
 MongoDB & Dify
MongoDB & Dify - Product
Dify Creator Center & Template Marketplace: Share Your Workflows
Dify’s new Creator Center and Template Marketplace let creators publish workflow templates and users discover and one-click adopt them, with optional PartnerStack affiliate linking to earn recurring commissions from subscriptions driven by template links.
Dify - Product
Try OpenAI, Claude, Gemini & Grok Free on Dify Cloud
Supports OpenAI, Claude, Gemini, and Grok. Try curated templates with zero configuration.
Dify