










Applications built on top of large language models involve three key techniques that need to be understood: Prompt Engineering, Embedding, and Fine-tuning. Among these, Embedding is a crucial technique for the large language model to comprehend the semantics of text, finding widespread applications in search engines, private knowledge-based question-answering systems, content recommendation systems, and more.
The Basic Concept of Embedding
What is Embedding? According to the official documentation by OpenAI: "Embeddings are numerical representations of concepts converted to number sequences, which make it easy for computers to understand the relationships between those concepts."
In simple terms, Embedding translates concepts into numerical sequences, enabling computers to comprehend the relationships between these concepts.
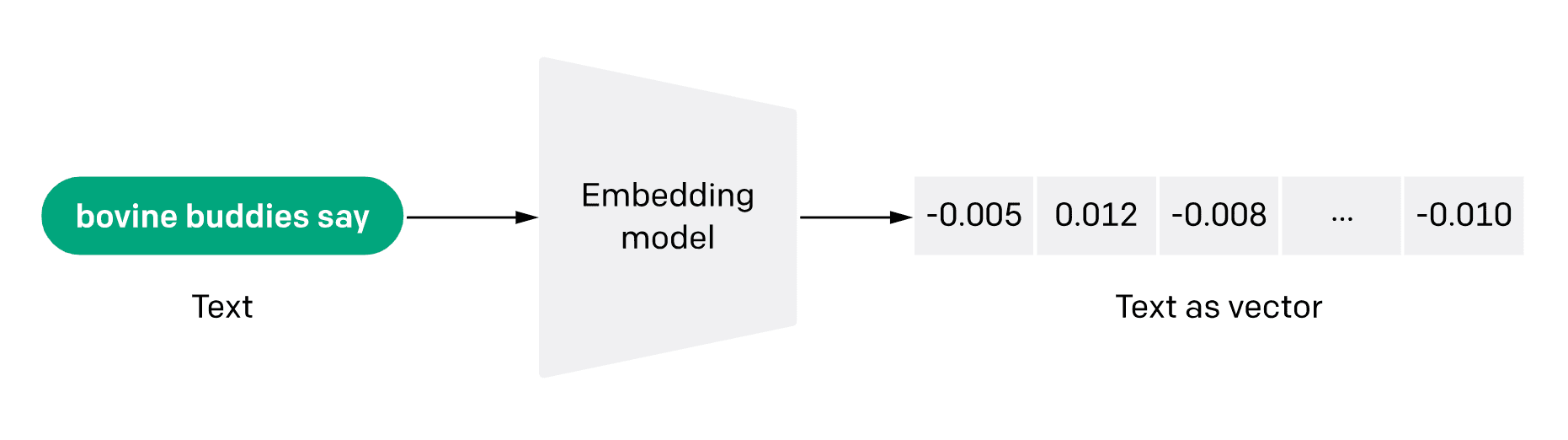
Embedding also represents information-dense representations of textual semantics, with each embedding being a floating-point vector. The distance between two embeddings in the vector space is correlated with the semantic similarity between the two inputs in the original format. For example, if two texts are similar, their vector representations should also be similar. This array of vector representations in the vector space describes subtle feature differences between texts.
In summary, Embedding helps computers understand the "meaning" represented by human information. Embedding can be used to capture the "relatedness" of features in text, images, videos, or other forms of information, commonly utilized for tasks such as search, recommendation, classification, and clustering.
How does Embedding Work?
Let's take three sentences as an example:
- "The cat chases the mouse."
- "The kitten hunts rodents."
- "I like ham sandwiches."
If a human were to categorize these three sentences, sentences 1 and 2 would be considered almost the same in meaning, while sentence 3 is entirely different. However, when we examine the original English sentences, sentences 1 and 2 share only "The," with no other common words. How does a computer understand the relatedness between the first two sentences?
Embedding compresses discrete information (words and symbols) into distributed continuous value data (vectors). If we were to plot the phrases on a chart, it might look like this:
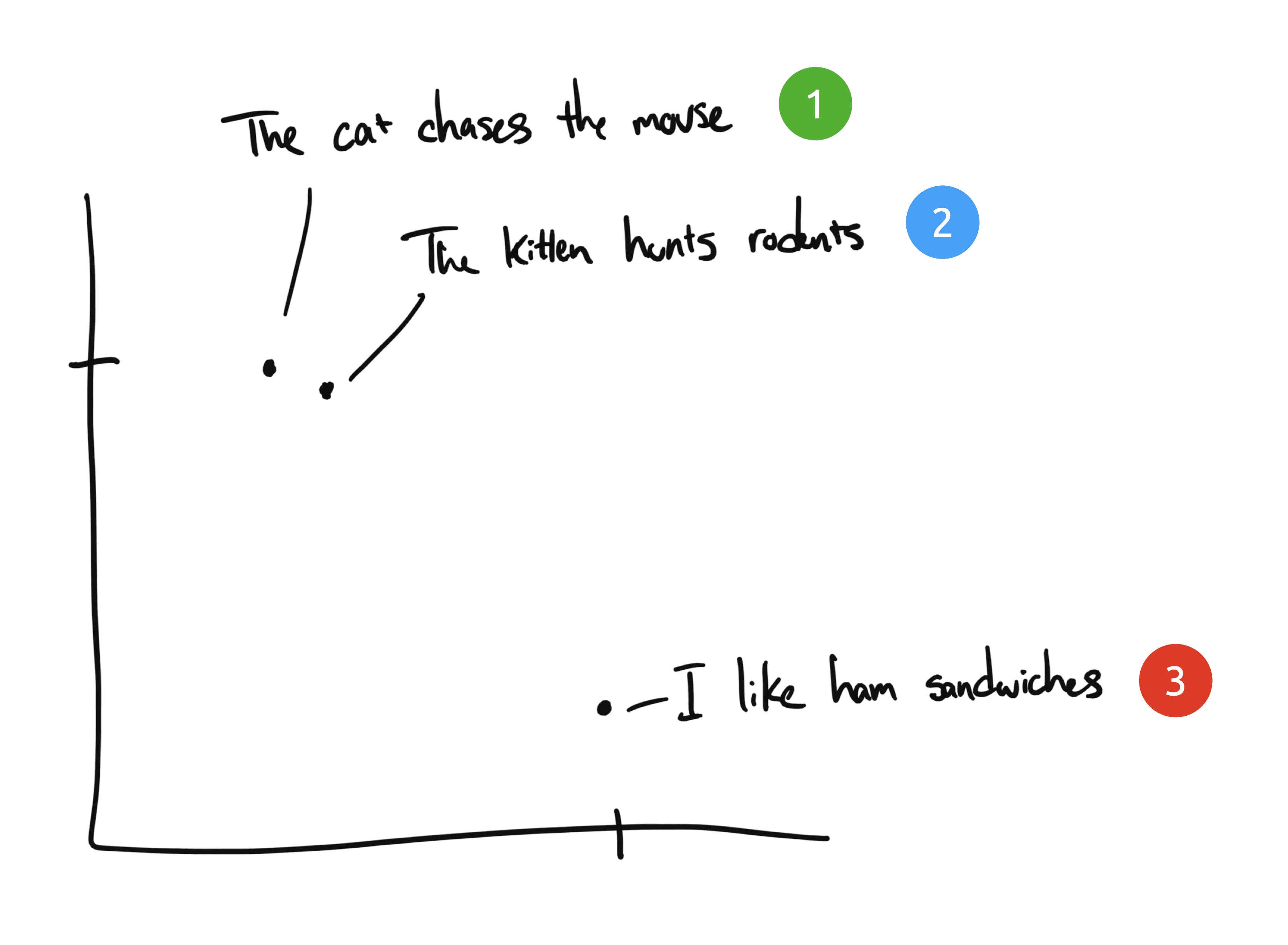
After compressing the text with Embedding into a multi-dimensional vector space that computers can understand, sentences 1 and 2 appear close to each other because of their similar meanings. Sentence 3 is farther away as it is unrelated to them. If we introduce a fourth phrase, "Sally eats Swiss cheese," it might exist somewhere between sentence 3 (cheese can be put in sandwiches) and sentence 1 (mice like Swiss cheese).
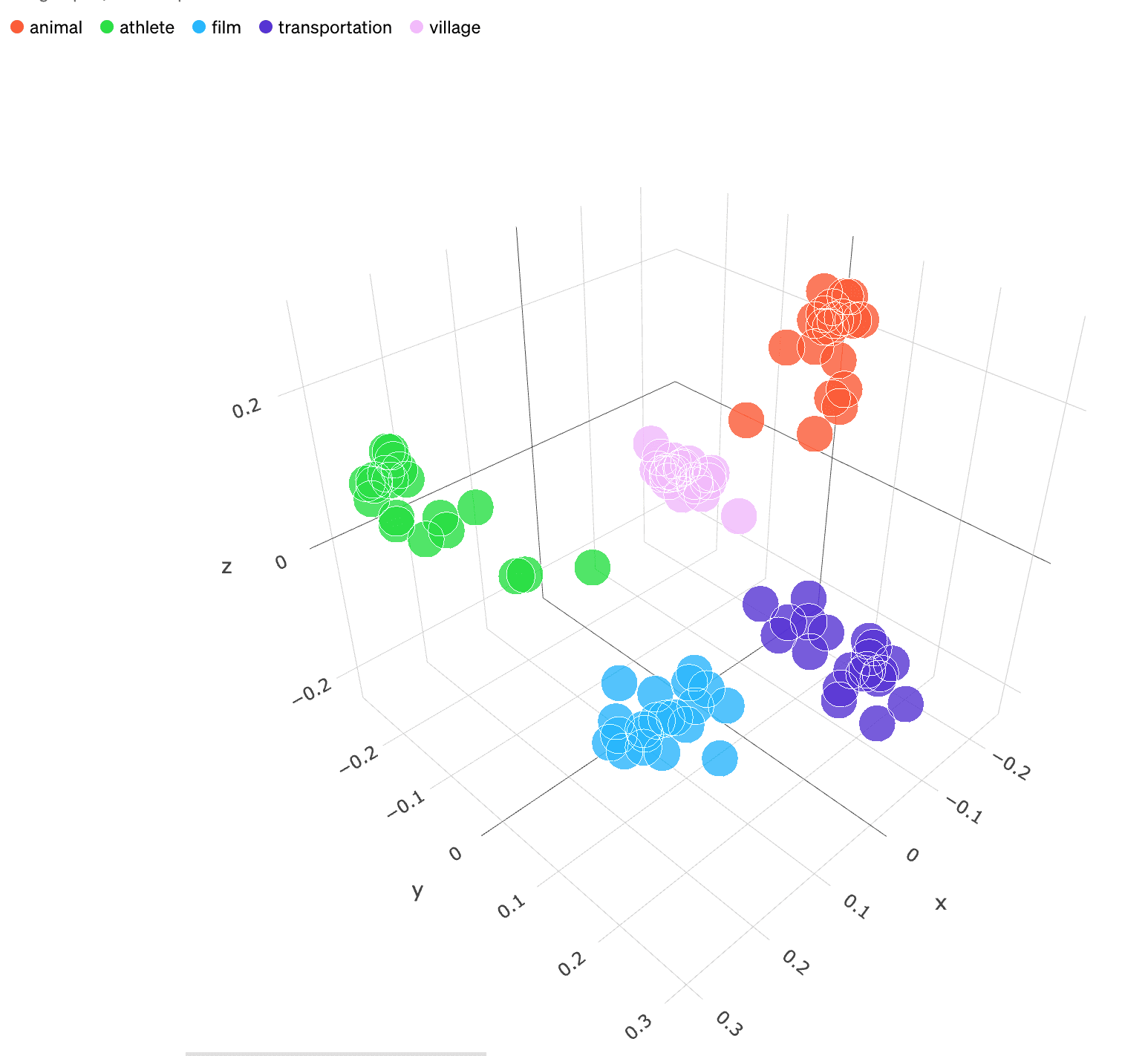
In this example, we only have two dimensions: the X-axis and Y-axis. In reality, Embedding models provide more dimensions to represent the complexity of human language. For instance, OpenAI's Embedding model "text-embedding-ada-002" outputs 1536 dimensions. This is enough for computers to understand subtle semantic differences in text. For classifying similar texts, the three-dimensional space might look like this (see the image below), where texts about animals, athletes, movies, vehicles, and villages are closer together.
What are the Advantages of Embedding?
Although ChatGPT is adept at answering questions, its range is limited to the data it memorized during training. GPT performs poorly in answering questions beyond its training data, specific domain knowledge (e.g., medicine, law, finance), or non-public data within organizations.
GPT has two ways to learn new knowledge:
- Model weights (fine-tuning on the training set).
- Model inputs (using knowledge as a few-shot prompt).
While fine-tuning may feel more natural since it allows the model to learn all knowledge from data, it is not reliable in factual recall. To draw an analogy, think of the large model as a student taking an exam. Model weights are like long-term memory; when you fine-tune the model, it's like preparing for the exam a week in advance. When the exam comes, the model might miss previously learned knowledge or incorrectly answer questions it was never taught.
On the other hand, using Embedding is like the student going into the exam without preparation but carrying a cheat sheet. When faced with a question, the student simply looks at the cheat sheet to answer accurately. Moreover, after the exam, the cheat sheet is discarded without occupying any memory. The process is straightforward and efficient (similarly for technical implementation).
However, this "cheat sheet" approach also has limitations. Each time the student takes an exam, they can only bring a few pages of notes, unable to carry all the study materials. This limitation is due to the large model's single-word input size (max tokens). GPT-3.5 has a token limit of 4K (equivalent to 5 pages), while GPT-4, released later, increases this limit eightfold, supporting up to 32K tokens (equivalent to 40 pages).
So, what happens when dealing with datasets much larger than this token limit? This is where the strategy of semantic retrieval based on Embedding + context injection comes into play.
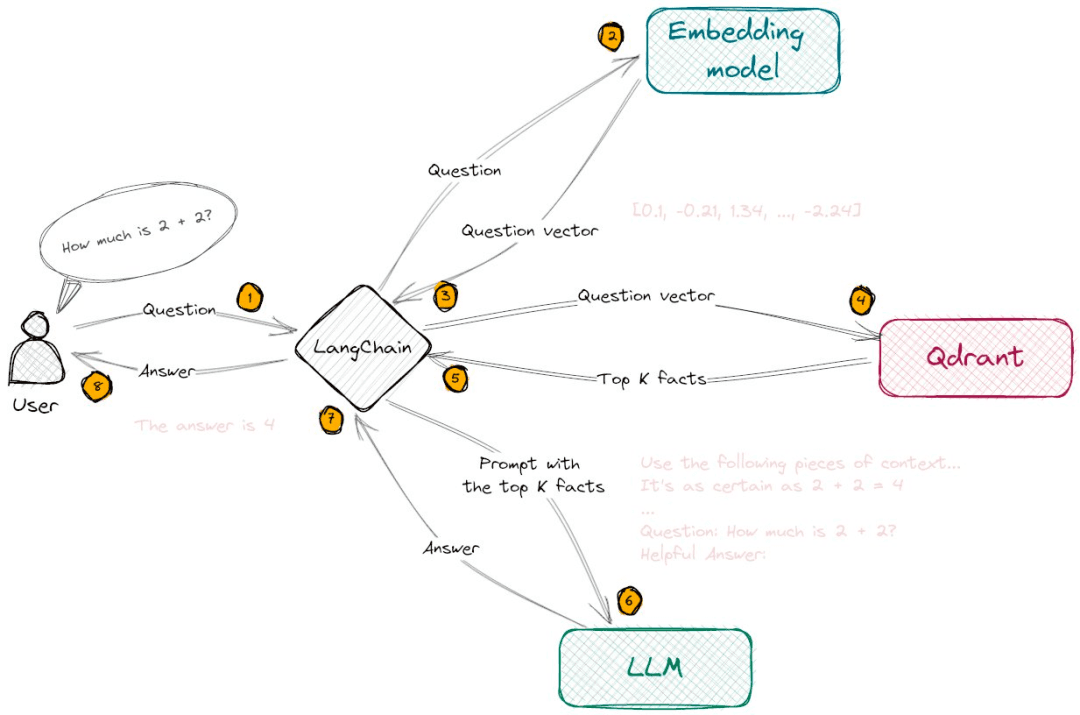
In my previous article, "Why the integration of GPT-4 in Microsoft's new Bing isn't as effective as expected?" I briefly explained the application of Embedding in search engines. Next, let's take an example of how to build a local knowledge question-answering system based on Embedding, which has similar principles. In simple terms, it involves three steps:
Step 1: Data Preparation
- Collection: Prepare a local knowledge base and provide the required text, such as articles, reports, diaries, blog posts, web pages, research papers, etc.
- Chunking: Divide the entire document into smaller text fragments (chunks).
- Embedding: Use the OpenAI API or local Embedding model to vectorize the text fragments into multi-dimensional arrays.
- Storage: For large datasets, store the vector arrays for future retrieval. For smaller datasets, temporary storage can be chosen.
Step 2: Semantic Retrieval
- Vectorize the user's question using the OpenAI Embedding API or local Embedding model.
- Use similarity measures (e.g., cosine similarity or Euclidean distance algorithm) to query the most similar text fragments to the question.
Step 3: Text Injection and Answering
- Inject the user's question and the retrieved most similar text fragments (TopK) as contextual prompts into the LLM.
- The LLM answers the question based on the user's question and the injected few-shot prompt.
The following is a flowchart illustrating the implementation process:
Advantages of Embedding-based Semantic Retrieval compared to Keyword-based Retrieval:
- Semantic Understanding: Embedding-based retrieval captures semantic relationships between words, enabling the model to grasp the semantic connections between vocabulary. Keyword-based retrieval often focuses on literal matching, potentially overlooking semantic relationships between words.
- Robustness: Embedding-based methods handle spelling errors, synonyms, and near-synonyms better due to their ability to comprehend word relationships. Keyword-based retrieval methods may be weaker in dealing with such cases.
- Multilingual Support: Many Embedding methods can support multiple languages, facilitating cross-language text retrieval. For example, you can use Chinese input to query English text content, which is challenging for keyword-based retrieval methods.
- Contextual Understanding: Embedding-based methods have an advantage when dealing with polysemy (one word having multiple meanings) since they can assign different vector representations to words based on context. Keyword-based retrieval methods may struggle to differentiate the meaning of the same word in different contexts.
Regarding contextual understanding, humans use words and symbols to communicate language, but isolated words often lack meaning. We need to draw from shared knowledge and experience to understand them. For example, the sentence "You should Google it" only makes sense if you know that "Google" is a search engine and people commonly use it as a verb. Similarly, effective natural language models must be able to understand the possible meanings of each word, phrase, sentence, or paragraph in different contexts.
Limitations of Embedding Retrieval:
- Input Token Limit: Even with the Embedding-based approach, there remains the challenge of input token limits. When retrieval involves a significant amount of text, to restrict the number of tokens for context injection, the "K" value in the TopK retrieval is often limited, resulting in information loss.
- Text-only Data: Currently, GPT-3.5 and many large models lack image recognition capabilities. However, many knowledge retrieval tasks require combining textual information with image understanding, such as illustrations in academic papers or financial reports.
- Potential for Fiction: When retrieved relevant document content is insufficient to support the large model in answering questions, the model might resort to some "creative writing" to attempt an answer.
Nevertheless, there are corresponding solutions to address these issues:
- Token Limit: The "Scaling Transformer to 1M tokens and beyond with RMT" paper discusses the use of recurrent memory techniques to effectively extend the model's context length to 2 million tokens while maintaining high accuracy. Additionally, applications like LangChain implement engineering solutions to bypass token limits effectively.

- Multi-modal Understanding: Apart from the image understanding of GPT-4, there are open-source projects like Mini-GPT4 that, when combined with BLIP-2, enable basic image understanding. This issue will likely be resolved in the near future.
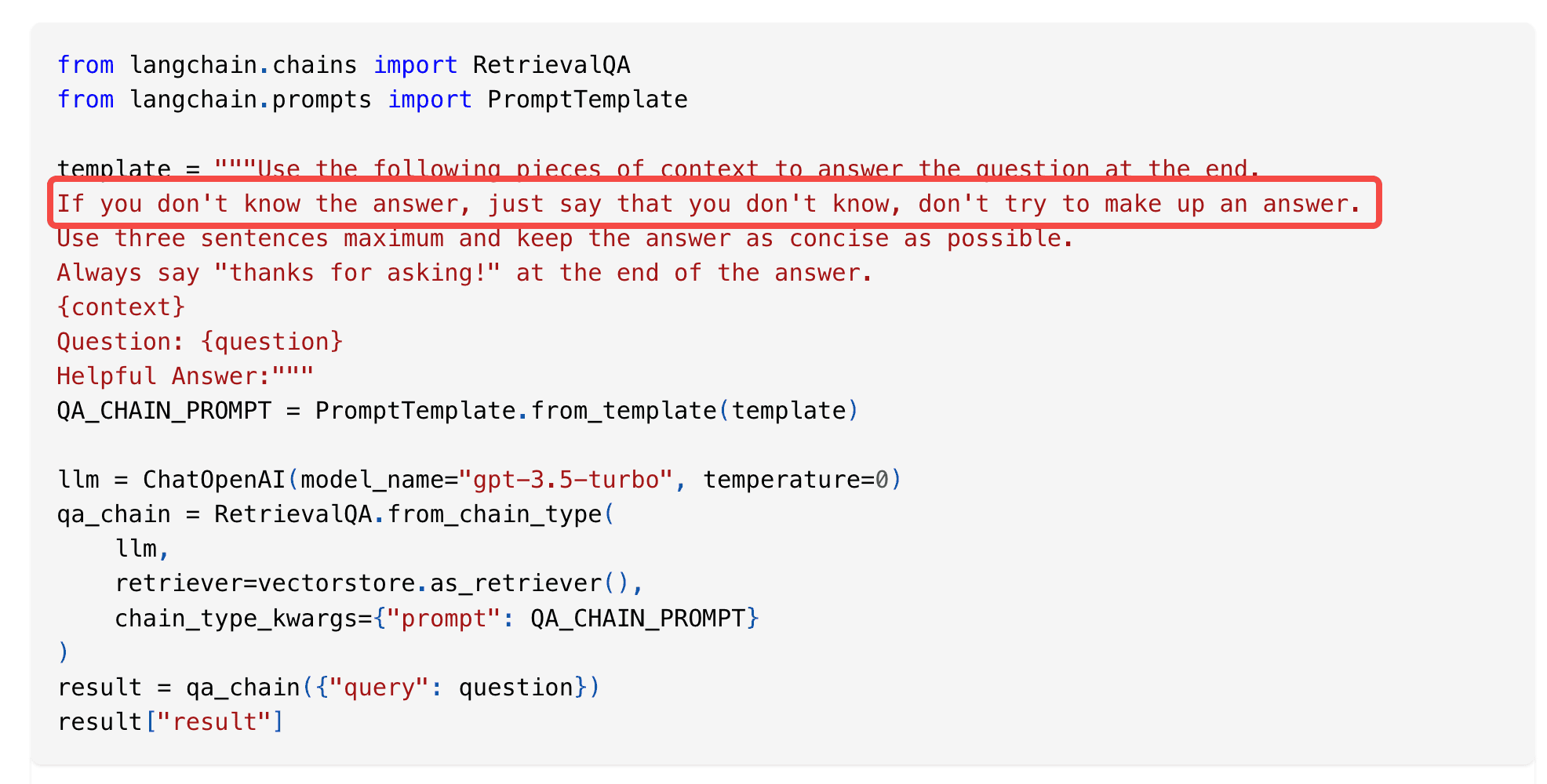
- Fiction Problem: This problem can be addressed at the prompt level. For instance, adding a line like "If you don't know the answer, just say that you don't know, don't try to make up an answer."
In practical application development and implementation, there are still numerous challenges to be addressed:
- The issue of information loss due to summarization in the question phase.
- The choice of similarity algorithms for different application scenarios.
- The scoring strategy for the credibility of transmitted documents.
- Engineering considerations for different models in the Prompt template layer.
- The impact of document segmentation on question-answering after context injection, and more.
Below are some resources related to Embedding:
Vector Databases: To facilitate rapid searching of many vectors, we recommend using vector databases. You can find examples of working with vector databases alongside the OpenAI API in GitHub Cookbook.
Available vector database options include:
- Pinecone, a fully managed vector database.
- PGVector, a free-to-use vector database.
- Weaviate, an open-source vector search engine.
- Qdrant, a vector search engine.
- Milvus, a vector database designed for scalable similarity search.
- Chroma, an open-source embedding repository.
- Typesense, a fast, open-source vector search engine.
- Zilliz, data infrastructure supported by Milvus.
Text Vectorization Tools: Text2vec
Text Similarity Comparison Algorithms:
- Cosine Distance
- L2-Squared Distance
- Dot Product Distance
- Hamming Distance
via @Vince
Image sources:
Related articles
- Developer
Deploying Private AI Agents with Dify on NVIDIA DGX Spark
This solution provides a complete hardware-to-application stack for building enterprise-grade private AI agents locally.
 Dify
Dify - Developer
How to run open source model Gemma on Dify?
Explore how to leverage Google's Gemma, an open-source LLM, for integration with Dify. Discover tips for enhancing AI applications responsibly.
 Xiaoyi
Xiaoyi - Developer
Dify.AI: Open-source Assistants API based on any LLM
OpenAI's Assistants API marks a shift in application engineering towards advanced AI use, emphasizing orchestration services. Dify, an open-source leader in this field, offers self-hosting for data security, multi-model support, and a flexible RAG engine. It enables privacy, compliance, customizable data processing, and team collaboration, enhancing AI application development and integration.
Dify - Developer
Introducing Hybrid Search and Rerank to Improve the Retrieval Accuracy of the RAG System
This article discusses enhancing RAG systems with Hybrid Search and Rerank technologies, focusing on improving retrieval accuracy and efficiency using LLMs for more comprehensive and precise search results.
 Vince
Vince