










Introducing Hybrid Search and Rerank to Improve the Retrieval Accuracy of the RAG System
This article discusses enhancing RAG systems with Hybrid Search and Rerank technologies, focusing on improving retrieval accuracy and efficiency using LLMs for more comprehensive and precise search results.
Currently, developers working with large models need to understand Retrieval Augmented Generation (RAG). Before writing this article, I observed that many technical pieces still narrowly define RAG as merely a blend of embedding-based vector retrieval and large model generation technologies.
However, after a year of extensive exploration and experimentation with RAG applications across various industries, it's now clear that relying solely on vector retrieval technology is inadequate for RAG application development, particularly for deployment in production environments.
In September, Microsoft Azure AI released a blog post titled "Azure Cognitive Search: Outperforming vector search with hybrid retrieval and ranking capabilities." This article offered an in-depth evaluation of experimental data on implementing Hybrid Search and re-ranking technologies in generative AI applications utilizing the RAG architecture. It quantified the notable enhancements these technologies contribute to document recall and accuracy.

This piece serves as an introduction to Hybrid Search and re-ranking technologies. It will explain the basic principles of these technologies and their role in enhancing the recall effectiveness of RAG systems. Additionally, the complexity of developing production-level RAG applications is discussed.
As an introductory technical piece, I'll first demystify what a RAG system is in simple terms.
Explanation of RAG Concept
This year, RAG architectures, which focus on vector retrieval, have become a dominant framework for large models to acquire up-to-date external knowledge and mitigate their hallucination issues, with practical implementations in numerous scenarios.
Developers can leverage this technology to build cost-effective AI solutions like customer service bots, corporate knowledge bases, and AI search engines. These systems interact using natural language inputs and various knowledge organization methods.
For example, as shown in the diagram, when a user asks, "Who is the President of the United States?", the system doesn't directly query the large model. It first conducts a vector search in a knowledge base (like Wikipedia), finds relevant information through semantic similarity (e.g., "Biden is the current 46th President of the USA..."), and then feeds the user's question and this retrieved information to the large model, enabling it to provide more accurate answers.
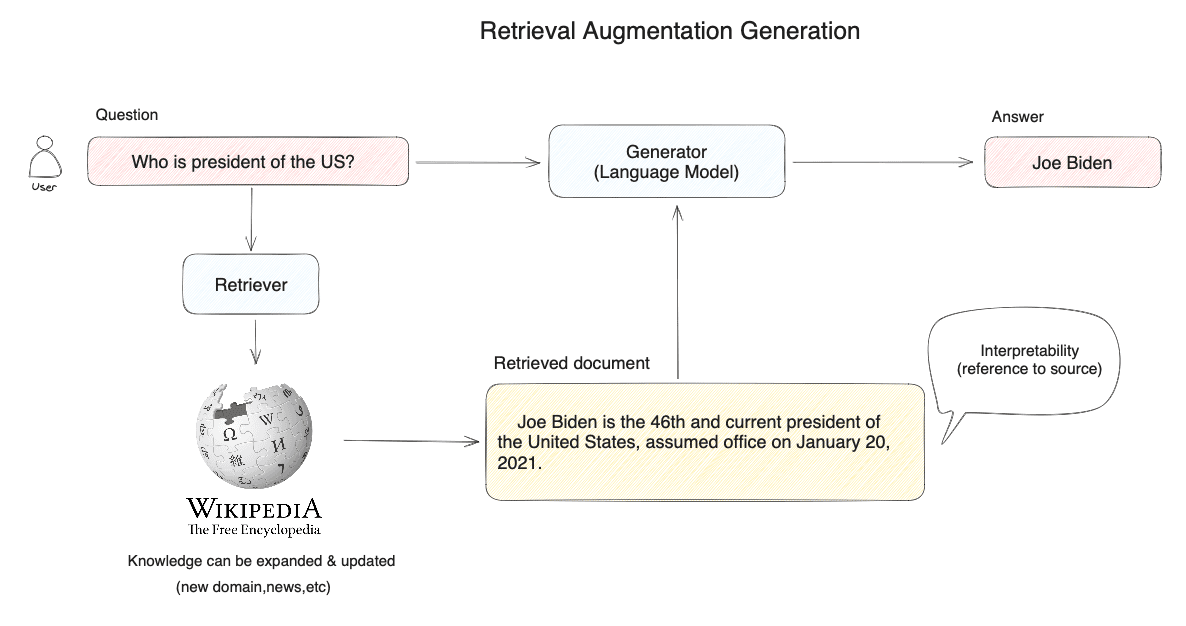
Why is This Necessary?
Think of a large model as a super expert knowledgeable in various human domains. Its limitation, however, is not knowing individual-specific information, as such data is private and not available online, meaning it cannot preemptively learn it.
For example, if you employ this super expert as your personal financial advisor, they would need to review your investment records and family expenses before they can respond to your queries. Only with this personalized information can they offer tailored professional advice.
This is precisely the function of the RAG system: it equips the large model with the external knowledge it lacks, enabling it to find answers before responding to queries.
The example clearly shows that the essence of the RAG system is in retrieving external knowledge. The ability of the expert to provide accurate financial advice hinges on their access to the necessary information. If irrelevant data, like a family weight loss plan, is retrieved instead of investment records, even the most skilled expert would be ineffective.
Why Hybrid Search is Needed
As previously mentioned, vector retrieval, focusing on semantic relevance, is the predominant method in the RAG retrieval phase. Its technical principle involves deconstructing documents from external knowledge bases into semantically complete paragraphs or sentences, then embedding them into numerical expressions (multi-dimensional vectors) understandable by computers, a process also applied to the user's query.
The computer is capable of detecting subtle semantic relations between user queries and sentences. For example, the semantic relation between "cat chases mouse" and "kitten hunts mouse" is stronger than between "cat chases mouse" and "I like to eat ham". Once it identifies the text with the highest relevance, the RAG system uses this information as context for the large model, aiding in formulating an answer to the question.
In addition to complex semantic text searches, vector retrieval offers several advantages:
- Understanding similar semantics, exemplified by mouse/mousetrap/cheese or Google/Bing/search engine comparisons.
- Providing multilingual comprehension, which enables cross-language understanding, such as matching English input with Chinese content.
- Supporting multimodal comprehension, allowing for similar matching across text, images, audio, and video.
- Offering fault tolerance, efficiently handling spelling errors and vague descriptions.
However, vector retrieval falls short in certain scenarios, such as:
- Searching for specific names of people or objects, like Elon Musk or iPhone 15.
- Searching for acronyms or short phrases, such as RAG or RLHF.
- Searching for IDs, for example, gpt-3.5-turbo or titan-xlarge-v1.01.
These limitations are where traditional keyword search excels, particularly in:
- Precise matching, including product names, personal names, and product codes.
- Matching with just a few characters, a situation where vector search struggles but is common among users.
- Matching low-frequency vocabulary, as these words often hold significant meaning; for instance, in "Would you like to have coffee with me?", words like "have" and "coffee" are more meaningful than "you" and "me".
In most text search scenarios, the main objective is ensuring the most relevant results appear in the candidate list. Both vector and keyword searches have their strengths in retrieval. Hybrid search merges these two technologies' advantages, balancing out their individual weaknesses.
In Hybrid Search, establishing vector and keyword indexes in the database beforehand is necessary. Upon entering a user query, the system retrieves the most relevant text from the documents utilizing both vector and keyword search modes.
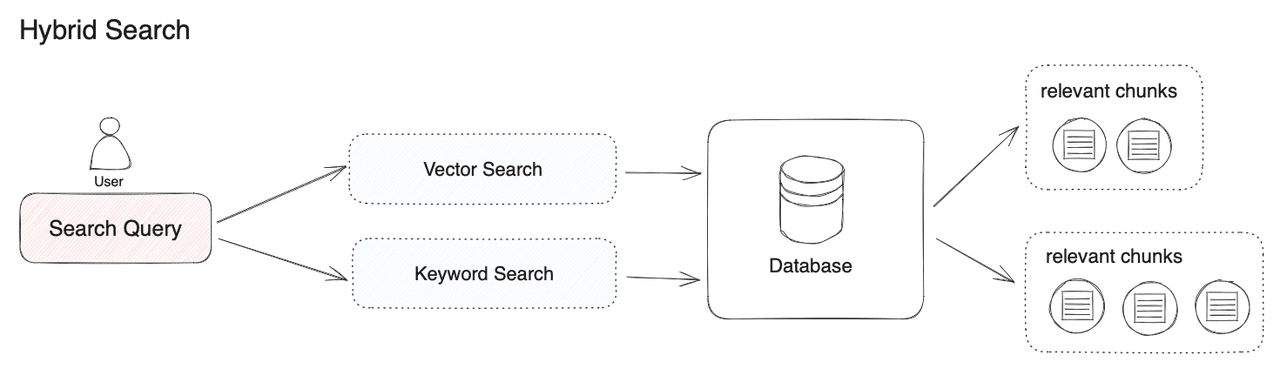
"Hybrid Search" lacks a precise definition. This article uses the integration of vector and keyword retrieval as an example. However, combining other search algorithms can also constitute "Hybrid Search." For example, merging knowledge graph technology, used for entity relationship retrieval, with vector retrieval technology, falls under this category.
Each retrieval system has its strengths in identifying various subtle connections in texts, including precise, semantic, thematic, structural, entity, temporal, and event relationships. No single retrieval mode fits all scenarios. Hybrid Search achieves a synergy of different retrieval techniques by blending multiple retrieval systems.
It's important to emphasize that the choice of retrieval technology hinges on the specific problem at hand. RAG systems fundamentally serve as open-domain, natural language-based question-answering systems. To attain high factual recall rates for open-ended user queries, generalizing and focusing application scenarios to select the suitable retrieval mode or combination is crucial.
Thus, when designing a RAG system, understanding your users and the types of questions they are most likely to ask is essential.
Why Re-ranking is Needed
While Hybrid Search effectively combines various search technologies for improved recall, it's necessary to merge and normalize query results from different search modes. This process transforms the data into a unified standard for better comparison, analysis, and processing before feeding it into the large model. This is where a scoring system, specifically the Rerank Model, becomes essential.
The rerank model enhances semantic sorting results by re-ranking the candidate documents according to their semantic alignment with the user's query. Its core principle involves calculating the relevance score between the user's question and each document, then returning a list of documents ordered by relevance, from highest to lowest. Popular rerank models include Cohere rerank, bge-reranker, among others.
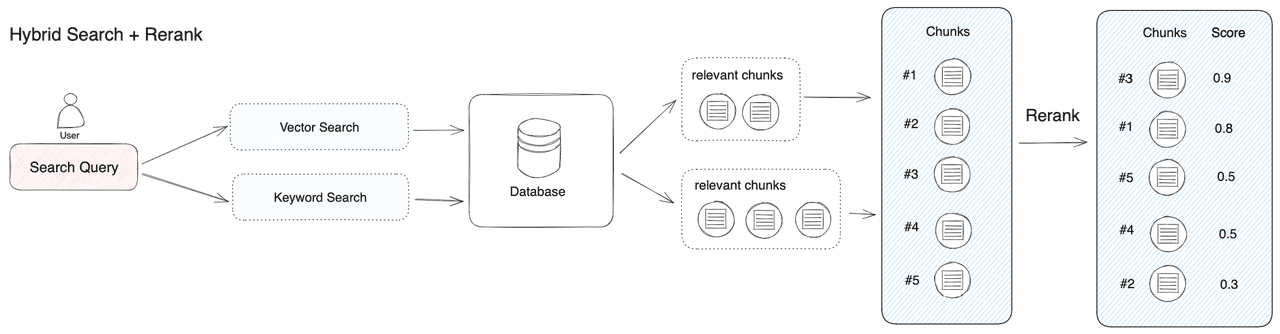
Typically, a preliminary search precedes re-ranking, as calculating relevance scores between a query and millions of documents is highly inefficient. Therefore, re-ranking is often positioned at the end of the search process, making it ideal for merging and sorting results from various search systems.
However, re-ranking is not limited to just combining results from different search systems. It's also beneficial in a single search mode. Introducing a re-ranking step, such as semantic re-ranking post keyword search, can significantly enhance document recall effectiveness.
In practical application, beyond normalizing multiple query results, the number of text segments passed to the large model is usually limited before providing them (i.e., TopK, adjustable in the rerank model parameters). This limitation is due to the input window size of the large model, which typically ranges from 4K to 128K tokens. Therefore, it's necessary to select a suitable segmentation strategy and TopK value that align with the model's input window size constraints.
It's crucial to recognize that even with a sufficiently large model's context window, an excessive number of recall segments can bring in less relevant content, diminishing the answer's quality. Hence, a larger TopK parameter in re-ranking doesn't always equate to better results.
Re-ranking should be viewed not as a replacement for search technology, but as a supplementary tool that enhances existing search systems. Its primary advantage lies in offering a straightforward, low-complexity method to refine search outcomes, enabling the integration of semantic relevance into current search systems without significant infrastructural modifications.
Take Cohere Rerank as an instance. Its integration is straightforward: users simply need to register for an account, acquire an API key, and then it takes just two lines of code to implement. Furthermore, Cohere Rerank supports multilingual models, allowing for the sorting of text queries in various languages simultaneously.
Azure AI Experiment Data Evaluation
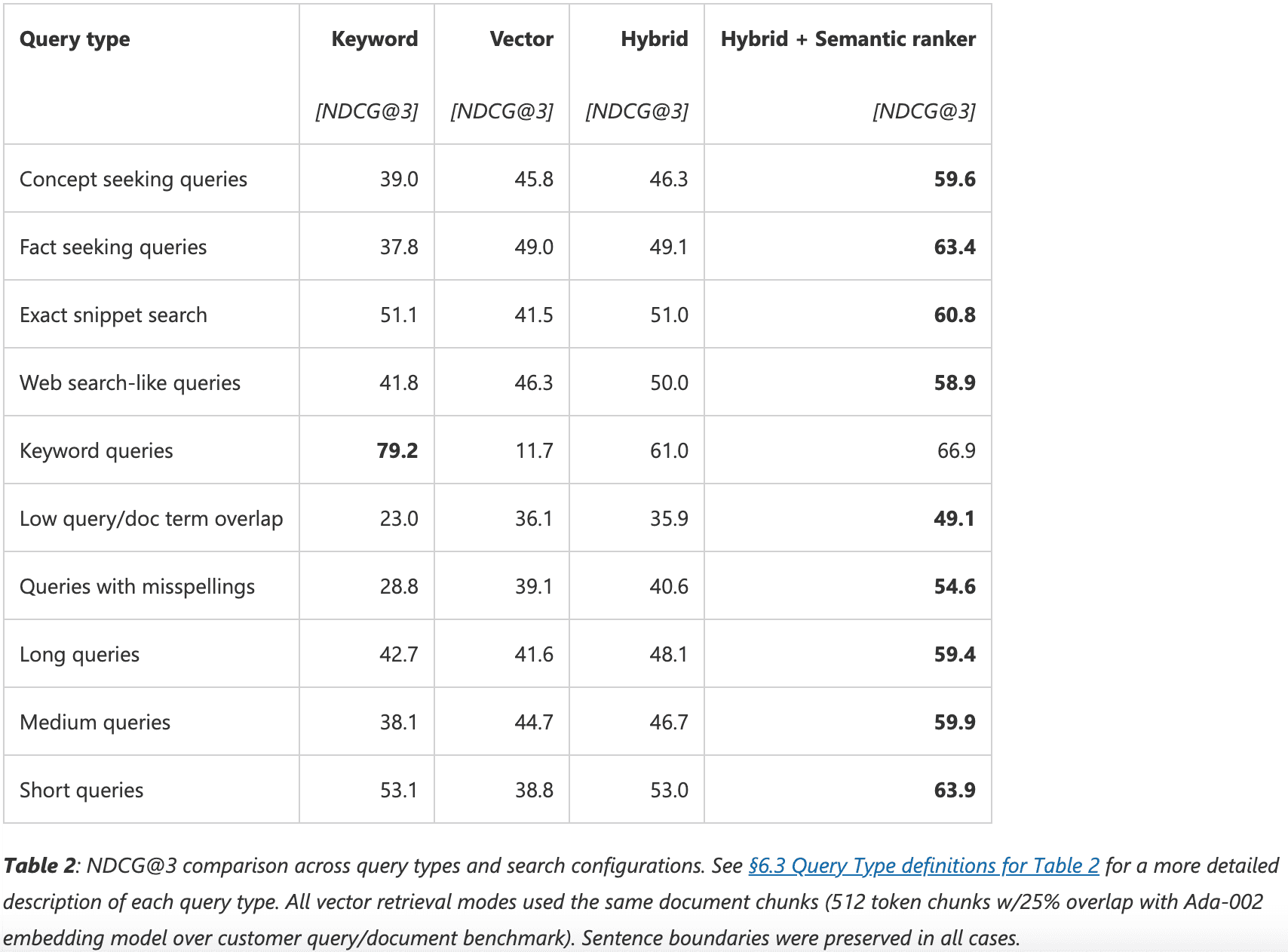
Azure AI carried out experimental data tests on various retrieval modes in the RAG system, including keyword retrieval, vector retrieval, hybrid retrieval, and hybrid retrieval plus rerank. The results indicate that hybrid retrieval combined with rerank significantly enhances document recall relevance, proving particularly effective in generative AI scenarios employing RAG architecture.
The evaluation results below detail different query scenarios, demonstrating the degrees of improvement in document recall quality across various use case scenarios with hybrid Search and rerank:
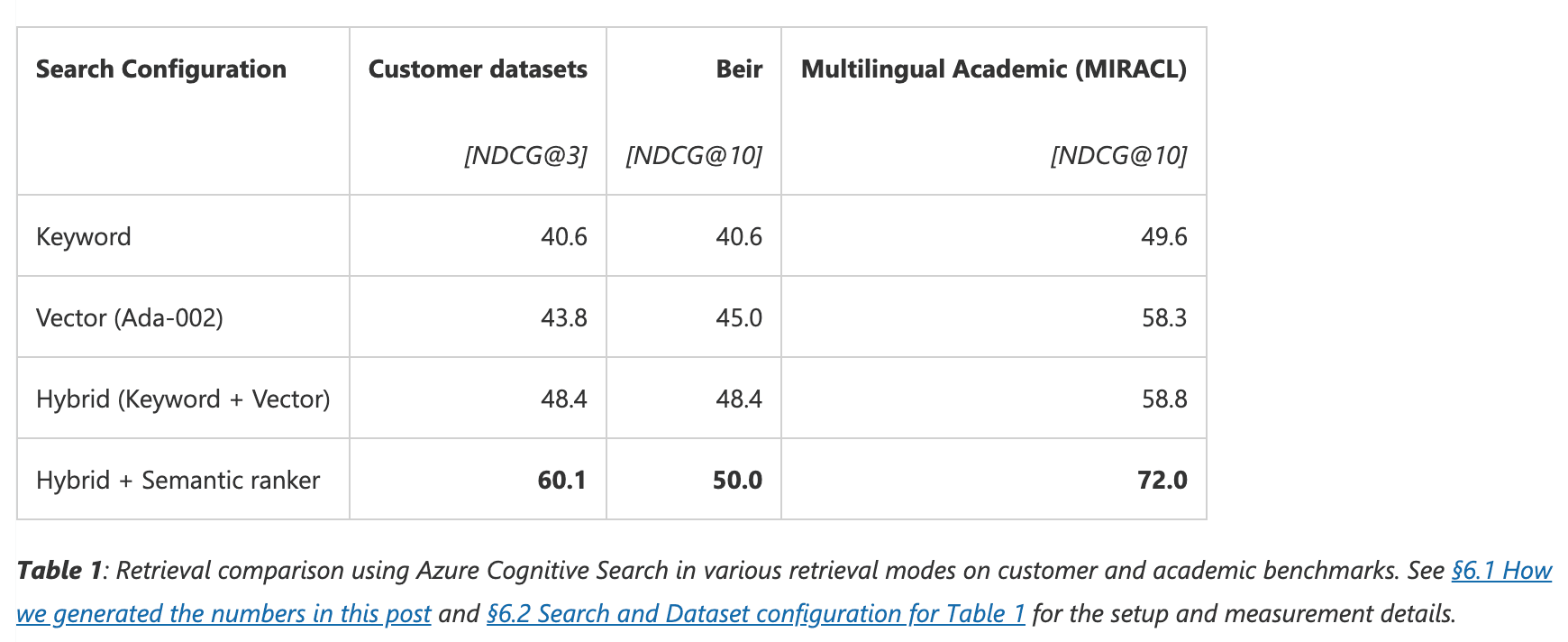
Here are the evaluation results for diverse query scenarios, illustrating that hybrid retrieval combined with re-ranking has variably enhanced the quality of document recall across different use case scenarios:
Conclusion
This discussion highlighted the principles and practicality of integrating hybrid retrieval and semantic rerank into RAG systems to boost document recall quality. However, this only represents a segment of the RAG retrieval pipeline's design.
To truly enhance RAG applications, a holistic engineering approach is essential, not just isolated optimizations. Deep understanding of user scenarios and the ability to distill complex open-domain question-answering challenges into targeted strategies are key. This understanding forms the basis for selecting an effective combination of technologies like indexing, segmenting, retrieving, and rerank.
Dify.AI has incorporated the Hybrid Search and Rerank methods mentioned in this article to enhance the recall effectiveness of its RAG system. By integrating retrieval modes with re-ranking and adding multi-path retrieval, it ensures content highly relevant to user queries is prioritized. This approach significantly improves the comprehensiveness and accuracy of search results, effectively creating an efficient question-answering system based on LLMs.
The exploration into the potential of various established and emerging technologies to augment RAG applications continues. We invite comments and discussions from those interested in this field.
Thank you for engaging with this article.
References
- Azure Cognitive Search: Outperforming vector search with hybrid retrieval and ranking capabilities
- https://txt.cohere.com/rerank/
- What is reranking and why does it matter?
- How to Implement Hybrid Search Into Your Product for Better Customer Experiences
- On Hybrid Search
- Unlocking the Power of Hybrid Search - A Deep Dive into Weaviate's Fusion Algorithms
- Rerankers and Two-Stage Retrieval
- Similarity Learning vs Search Reranking: Practical Approaches to boosting real-world search performance
- https://weaviate.io/developers/weaviate/concepts/reranking
- Patterns for Building LLM-based Systems & Products
- Vector Search Is Not All You Need
via @Vince
Related articles
- Developer
Deploying Private AI Agents with Dify on NVIDIA DGX Spark
This solution provides a complete hardware-to-application stack for building enterprise-grade private AI agents locally.
 Dify
Dify - Developer
How to run open source model Gemma on Dify?
Explore how to leverage Google's Gemma, an open-source LLM, for integration with Dify. Discover tips for enhancing AI applications responsibly.
 Xiaoyi
Xiaoyi - Developer
Dify.AI: Open-source Assistants API based on any LLM
OpenAI's Assistants API marks a shift in application engineering towards advanced AI use, emphasizing orchestration services. Dify, an open-source leader in this field, offers self-hosting for data security, multi-model support, and a flexible RAG engine. It enables privacy, compliance, customizable data processing, and team collaboration, enhancing AI application development and integration.
Dify - Developer
Text Embedding: Basic Concepts and Implementation Principles
Embedding is a vital technique in AI applications, representing concepts as numerical sequences to enable better comprehension of relationships.
 Vince
Vince