











Introduction
On February 21, Google launched a series of lightweight open-source large language models:
- Gemma-2b,
- Gemma-7b,
- Gemma-2b-it,
- and Gemma-7b-it.
According to Google's blog, Gemma uses the same research and technology as the Gemini series of models, but specifically designed for responsible artificial intelligence development.
After the model was released, the CEO of Google DeepMind also congratulated on the release of Gemma, "We have a long history of supporting responsible open source & science, which can drive rapid research progress, so we’re proud to release Gemma: a set of lightweight open models, best-in-class for their size, inspired by the same tech used for Gemini. "
Overview of Gemma
The Gemma model series includes Gemma 2B and Gemma 7B, both supporting pre-training and instruction tuning (Instruct Version). These models inherit Google's innovative genes in technologies such as Transformer, TensorFlow, BERT, and T5, providing developers with powerful tools in natural language processing, machine learning, data analysis, and other fields. Google aims to promote developer innovation, collaboration, and guide the responsible use of AI technology by open-sourcing the Gemma model.
In Gemma's blog and its technical report, Google mentioned some key details:
- We’re releasing model weights in two sizes: Gemma 2B and Gemma 7B. Each size is released with pre-trained and instruction-tuned variants.
- A new Responsible Generative AI Toolkit provides guidance and essential tools for creating safer AI applications with Gemma.
- We’re providing toolchains for inference and supervised fine-tuning (SFT) across all major frameworks: JAX, PyTorch, and TensorFlow through native Keras 3.0.
- Ready-to-use Colab and Kaggle notebooks, alongside integration with popular tools such as Hugging Face, MaxText, NVIDIA NeMo and TensorRT-LLM, make it easy to get started with Gemma.
- Pre-trained and instruction-tuned Gemma models can run on your laptop, workstation, or Google Cloud with easy deployment on Vertex AI and Google Kubernetes Engine (GKE).
- Optimization across multiple AI hardware platforms ensures industry-leading performance, including NVIDIA GPUs and Google Cloud TPUs.
- Terms of use permit responsible commercial usage and distribution for all organizations, regardless of size.
How to Use Gemma in Dify?
Dify supports Text-Generation models and Embeddings models on Hugging Face. The specific steps to use Gemma on Dify are as follows:
- You need to have a Hugging Face account (https://huggingface.co/join).
- Set up Hugging Face's API key (https://huggingface.co/settings/tokens).
- Go to the Gemma model detail page (https://huggingface.co/google/gemma-7b), copy the model name or Endpoint URL.
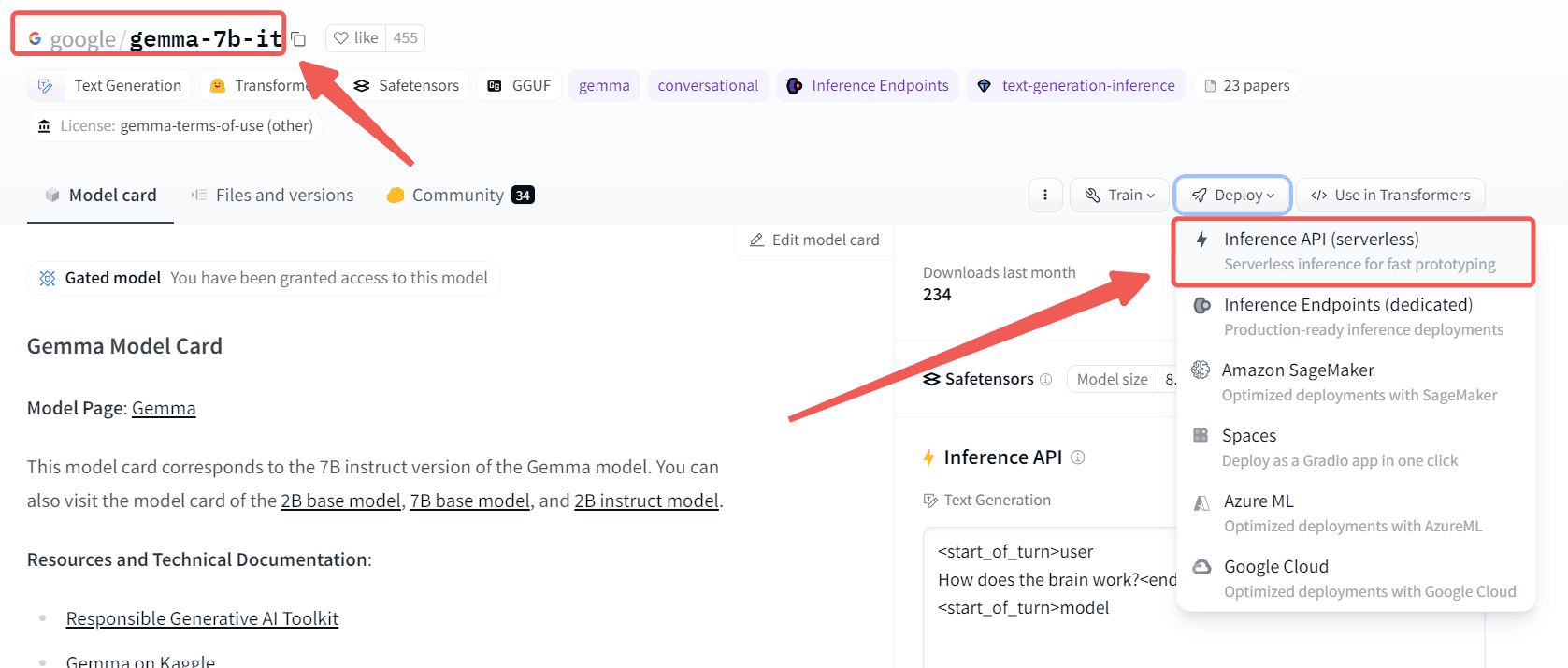
Dify supports accessing models on Hugging Face in two ways:
- Hosted Inference API. This method uses the model deployed by Hugging Face officially. It is free of charge. However, the downside is that only a few models support this method.
- Inference Endpoint. This method uses resources such as AWS accessed by Hugging Face to deploy the model, which requires payment.
Method 1: Accessing the Hosted Inference API model
1 Choose the model
The model detail page on the right side contains the area that supports Hosted Inference API. Currently, Gemma supports Hosted Inference API. Then, on the model detail page, get the model name: google/gemma-6b-it or google/gemma-6b. If you want to try the base model, use gemma-6b; if you want to use the instruction-tuned version (which can answer questions normally), use gemma-6b-it.
2 Use the model in Dify
In Settings > Model Provider > Hugging Face > Model Type, select Hosted Inference API as the Endpoint Type, as shown in the following figure:
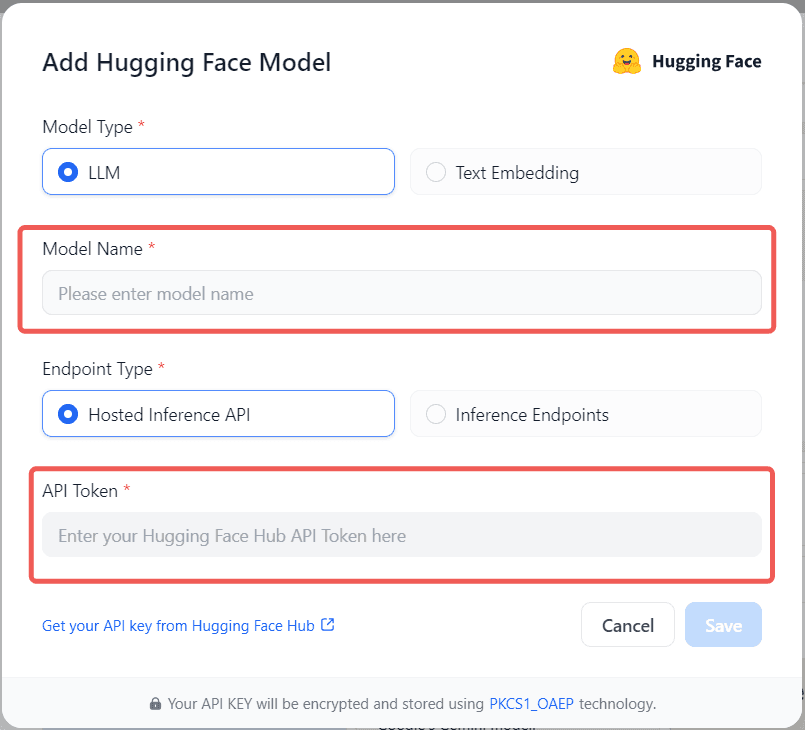
The API Token is the API Key set at the beginning of the article. The model name is the model name obtained in the previous step.
Method 2: Inference Endpoint
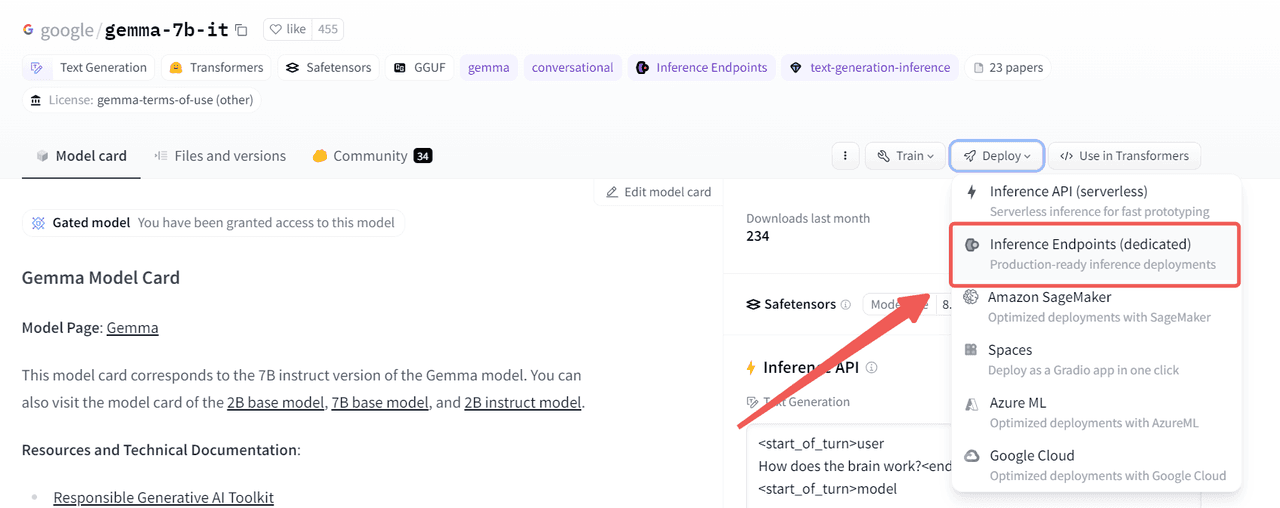
1 Choose the model to deploy
The model detail page on the right side under the Deploy button has the Inference Endpoints option for models that support Inference Endpoint - Gemma is supported. As shown in the following figure:
2 Deploy the model
Click the deploy button, select the Inference Endpoint option. If you haven't a valid credit card before, you will need to add one to your account. After validating your credit card, just click the Create Endpoint button at the bottom left to create the Inference Endpoint.
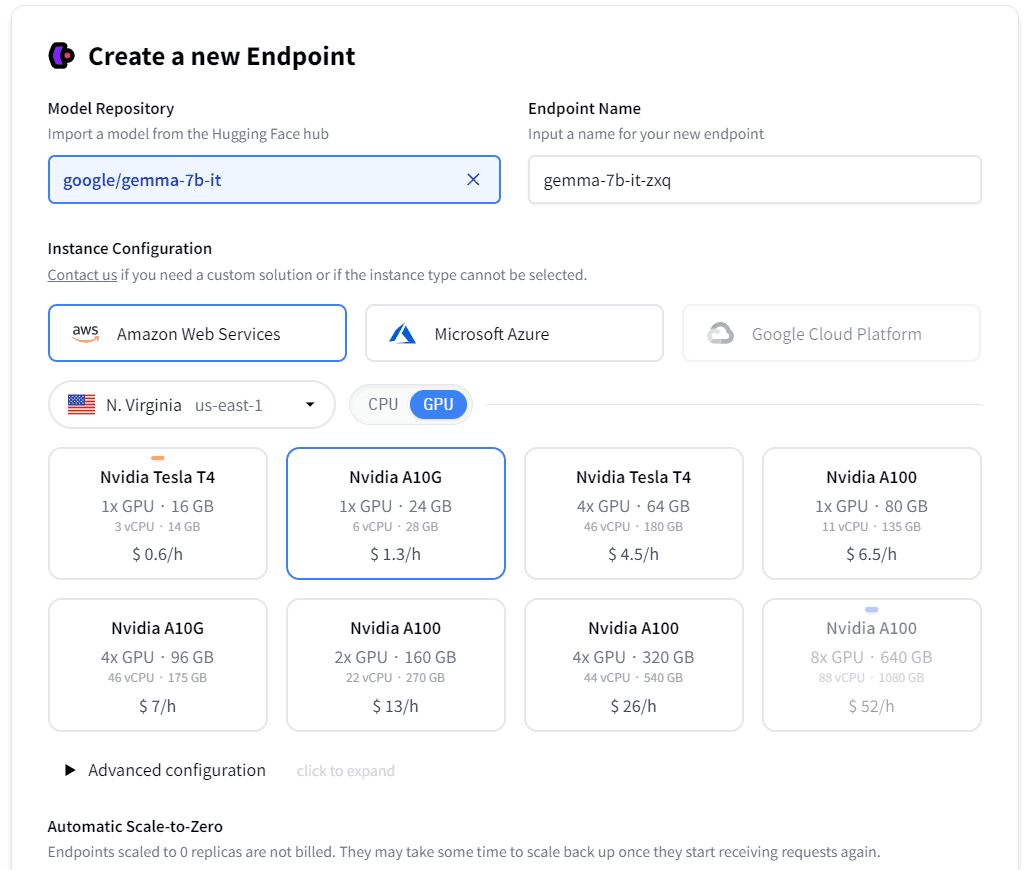
It will take you about 10 minutes to initialize the model and create an endpoint. After the model is deployed, you will be able to see the Endpoint URL.
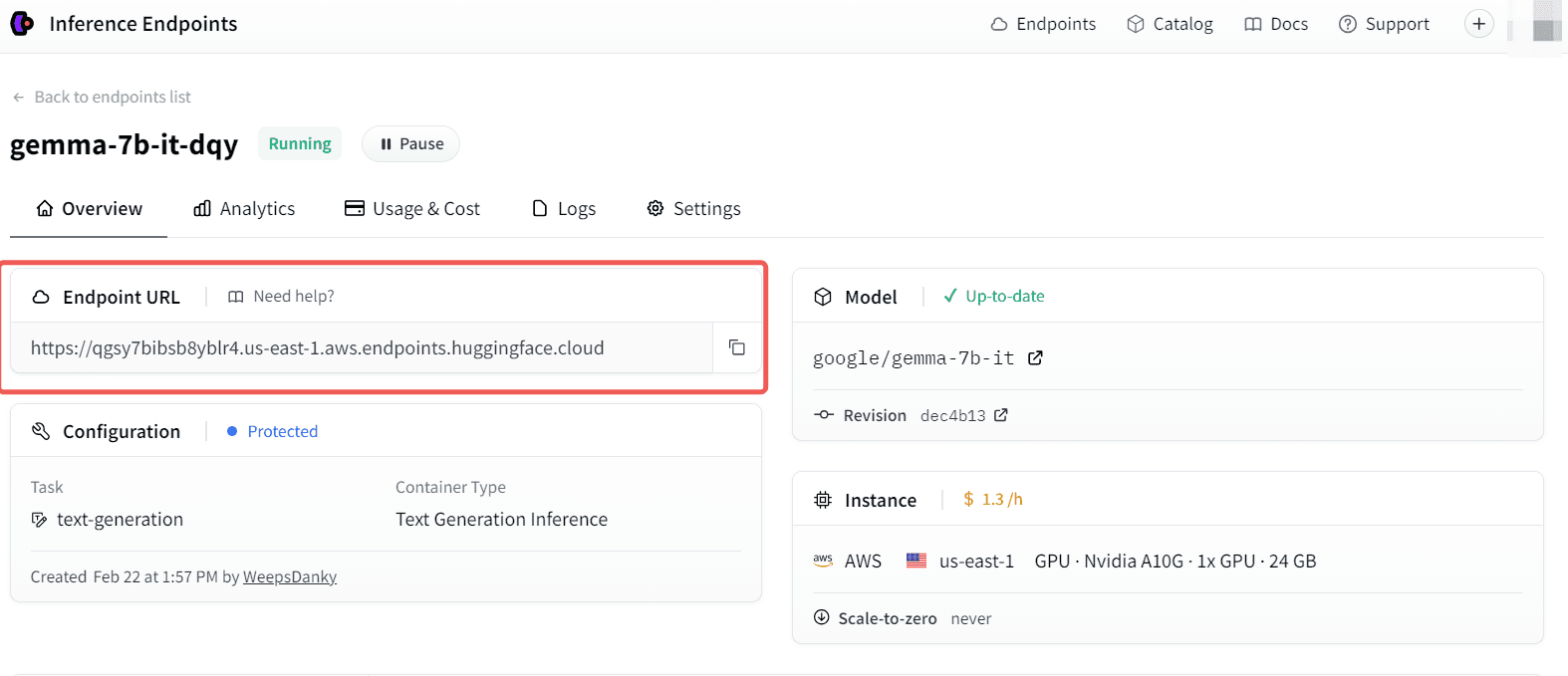
3 Use Gemma in Dify
In Settings > Model Provider > Hugging Face > Model Type, select Inference Endpoints as the Endpoint Type, as shown in the following figure:
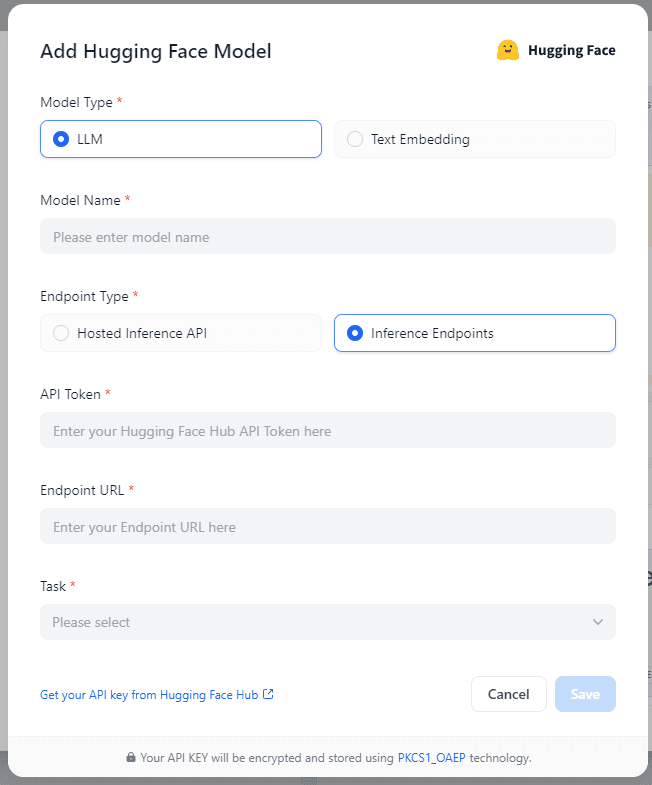
The API Token is the API Key set at the beginning of the article. The Text-Generation model name can be arbitrary, and the Embeddings model name needs to be consistent with Hugging Face. The Endpoint URL is the URL obtained after the model is successfully deployed in the previous step.
Note: For Embeddings, the "Username / Organization Name" needs to be filled in according to the deployment method of your Inference Endpoints on Hugging Face.
Dify Supports All Open Source Models on the Market
Dify now provides support for well-known text generation open-source models such as Gemma, LLaMA 2, Mistral, Baichuan, Yi, etc. This means that developers and researchers can now easily access and deploy these advanced models to accelerate their research and development process.
For users who want to access models through cloud services, Dify offers the ability to directly connect to Hugging Face's Inference API (Serverless). This feature allows users to seamlessly access and deploy the latest models, enjoying the convenience and flexibility of cloud computing. Dify supports Text-Generation and Embeddings, corresponding to the following Hugging Face model types:
- Text-Generation: text-generation, text2text-generation,
- Embeddings: feature-extraction.
In terms of local deployment, Dify has supported various inference frameworks, providing users with a wide range of choices. In addition to using Hugging Face's Inference API in the cloud, developers can also deploy these well-known open-source models locally on services such as Replicate, Xinference, OpenLLM, LocalAI, and Ollama. These services enable users to easily deploy and run models in a local environment, ensuring data privacy and security while also providing better performance and response speed.
Dify also includes a visual operation interface, allowing users to quickly experience and test models in an intuitive way. Even if you are not from a technical background, you can easily get started.
- How to customize? How to deploy locally? Check out our documentation!
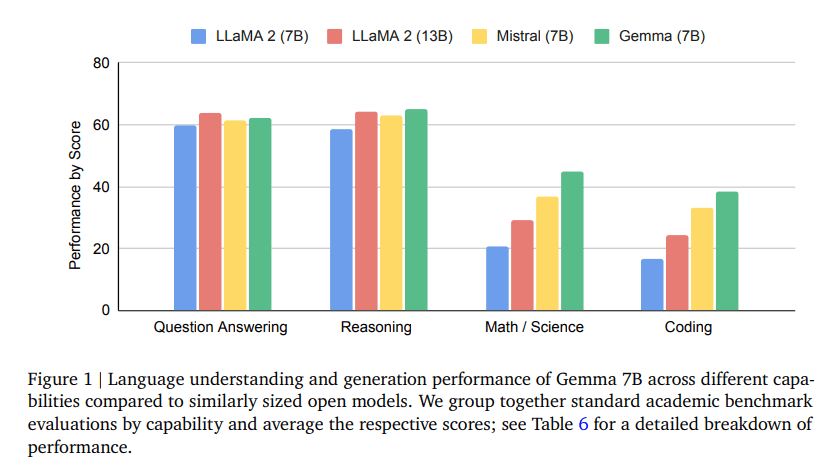
Performance Comparison of Gemma with LLaMA 2 (13B), Mistral (7B)
The Technical Report also mentioned how Gemma actually performs. Compared with other existing open-source models of similar size, such as LLaMA 2 (7B), LLaMA 2 (13B), and Mistral (7B), Gemma 2B and 7B have industry-leading performance. Gemma itself significantly surpasses Llama-2 in key indicators, achieving better indicators with a smaller number of parameters.
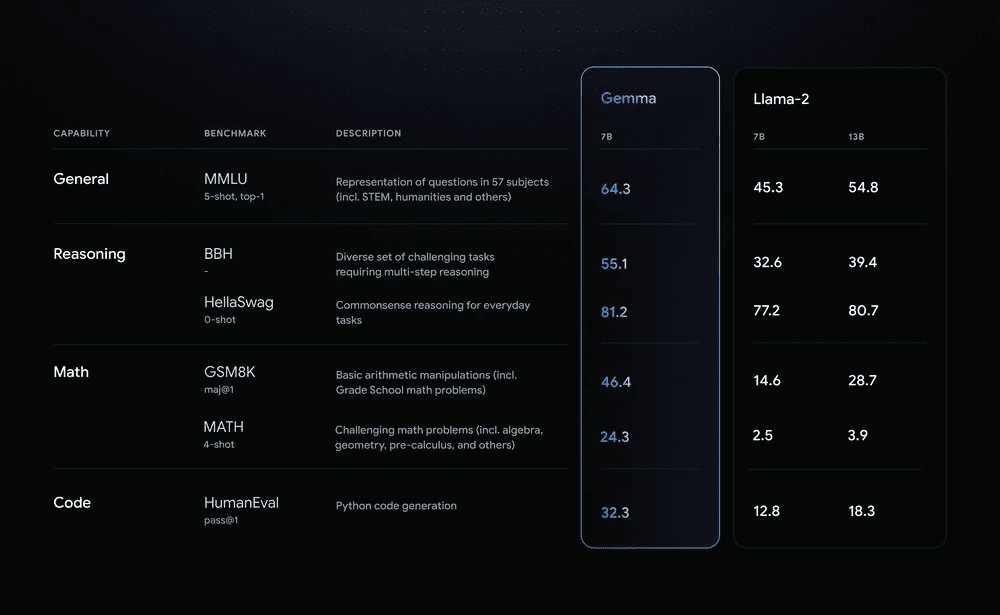
As can be seen, whether it is in answering questions, inference ability, mathematics/science, or code generation, the Gemma model is in a leading position in the industry, surpassing or on par with the other two major open-source models LLaMA 2 and Mistral. In mathematics/science and coding tasks, Gemma 7B even surpasses the performance of Mistral 7B.
Experience Open Source Models on Dify
Now log in to https://dify.ai/ to quickly experience the strongest open-source large model Gemma!
After reading this article, you should also be able to try experiencing various open-source models on Dify, just by accessing the HuggingFace API. As an open-source LLM application development platform, Dify will actively adapt to and embrace the open-source ecosystem, supporting global developers and organizations in responsible AI development.
Still have some details unclear? First, take a look at our documentation on configuring models.
We welcome you to use Dify to turn your unique ideas into reality. We can't wait to see you use open-source models on Dify, transforming your creativity into productivity and making it a reality.
You are welcome to join our Discord (https://discord.com/invite/FngNHpbcY7) to discuss any insights and questions you have.
References
[1] Google. (2024). Gemma: Introducing new state-of-the-art open models. [online] Available at: https://blog.google/technology/developers/gemma-open-models/.
[2] Google DeepMind. (2024). Gemma: Open Models Based on Gemini Research and Technology. [online] Available at: https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
[3] Demis Hasssabis. (2024). [Online] Available at: https://twitter.com/demishassabis/status/1760292935470403656
Related articles
- Developer
Deploying Private AI Agents with Dify on NVIDIA DGX Spark
This solution provides a complete hardware-to-application stack for building enterprise-grade private AI agents locally.
 Dify
Dify - Developer
Dify.AI: Open-source Assistants API based on any LLM
OpenAI's Assistants API marks a shift in application engineering towards advanced AI use, emphasizing orchestration services. Dify, an open-source leader in this field, offers self-hosting for data security, multi-model support, and a flexible RAG engine. It enables privacy, compliance, customizable data processing, and team collaboration, enhancing AI application development and integration.
Dify - Developer
Introducing Hybrid Search and Rerank to Improve the Retrieval Accuracy of the RAG System
This article discusses enhancing RAG systems with Hybrid Search and Rerank technologies, focusing on improving retrieval accuracy and efficiency using LLMs for more comprehensive and precise search results.
 Vince
Vince - Developer
Text Embedding: Basic Concepts and Implementation Principles
Embedding is a vital technique in AI applications, representing concepts as numerical sequences to enable better comprehension of relationships.
Vince