











Hi, I'm Yawen from the Dify product team. Today, we're excited to launch Dify v0.15.0 with the new Parent-child Retrieval, an advanced technique implemented in Retrieval-Augmented Generation (RAG) systems to enhance information access and contextual understanding. With this technique, Dify can now improve the quality and accuracy of AI-generated responses by providing more comprehensive and contextually relevant information.
The Dilemma of Context and Precision
When using knowledge retrieval systems, users often face a frustrating trade-off: search results are either too fragmented, lacking the necessary context to make sense of the information, or too broad, sacrificing precision for an overload of irrelevant details. This makes it harder for users to find and use the exact information they need efficiently.
The chosen chunk size significantly impacts the system's ability to generate accurate and comprehensive responses. Consequently, finding an ideal balance between precision and context is crucial for enhancing the overall performance and reliability of the knowledge retrieval process.
Child Chunks for Retrieval & Parent Chunks for Context
Parent-Child Retrieval addresses the dilemma of context and precision by leveraging a two-tier hierarchical approach that effectively balances the trade-off between accurate matching and comprehensive contextual information in RAG systems. Here is the essential mechanism of this structured, two-level information access:
- Query Matching with Child Chunks:
- Small, focused pieces of information, often as concise as a single sentence within a paragraph, are used to match the user's query.
- These child chunks enable precise and relevant initial retrieval.
- Contextual Enrichment with Parent Chunks:
- Larger, encompassing sections—such as a paragraph, a section, or even an entire document—that include the matched child chunks are then retrieved.
- These parent chunks provide comprehensive context for the Language Model (LLM).
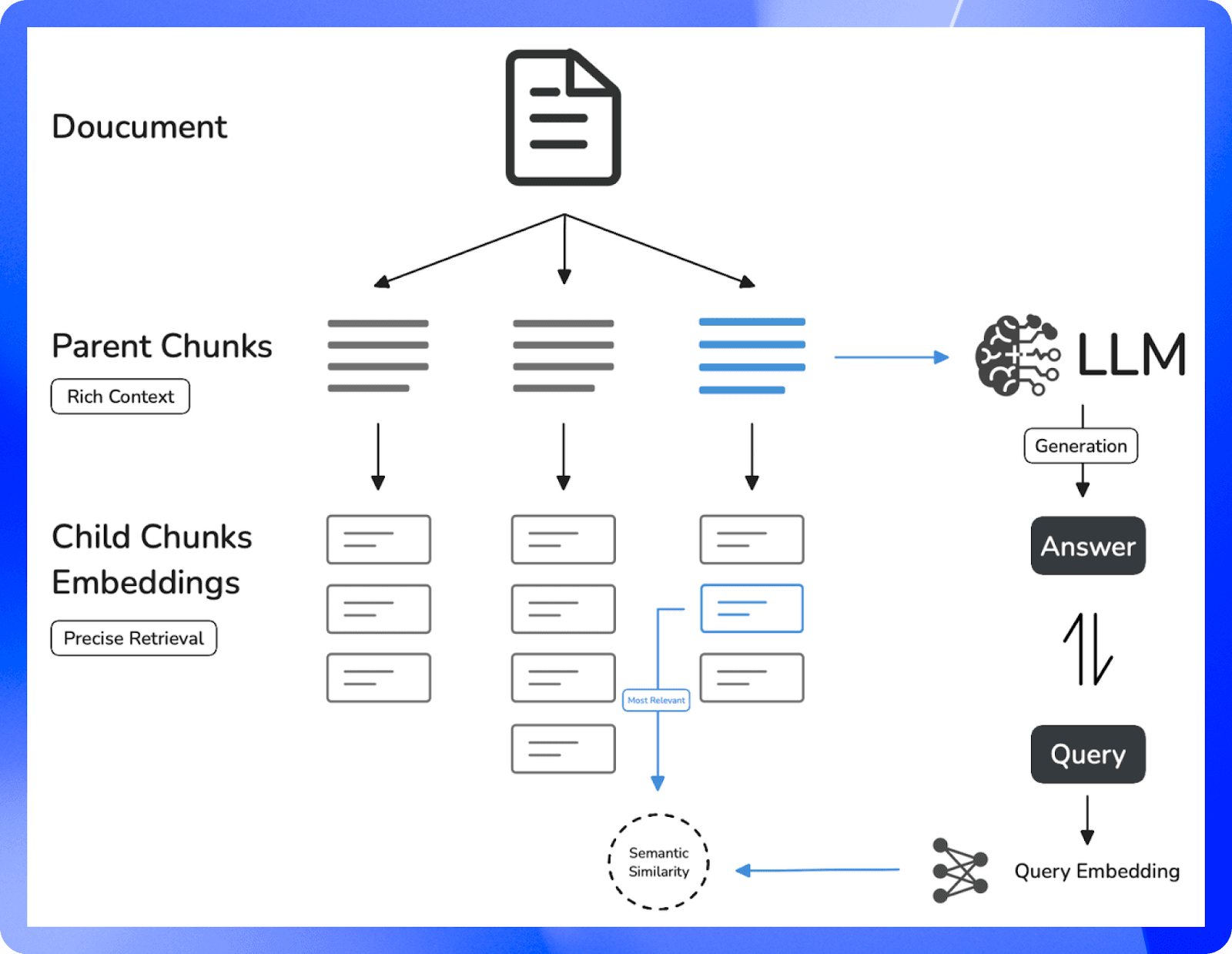
This hierarchical retrieval method preserves the wider narrative or background of retrieved information and mitigates the risk of overlooking crucial contextual details during the chunking process. For example, in customer support, it enables automated systems to deliver more detailed and contextually accurate responses by referencing comprehensive product documentation. Therefore, in content generation, it enhances the quality of outputs from language models by providing not only precise answers but also extensive supporting background information. Here is a comparison example between General Retrieval and Parent-child Retrieval using the same document.
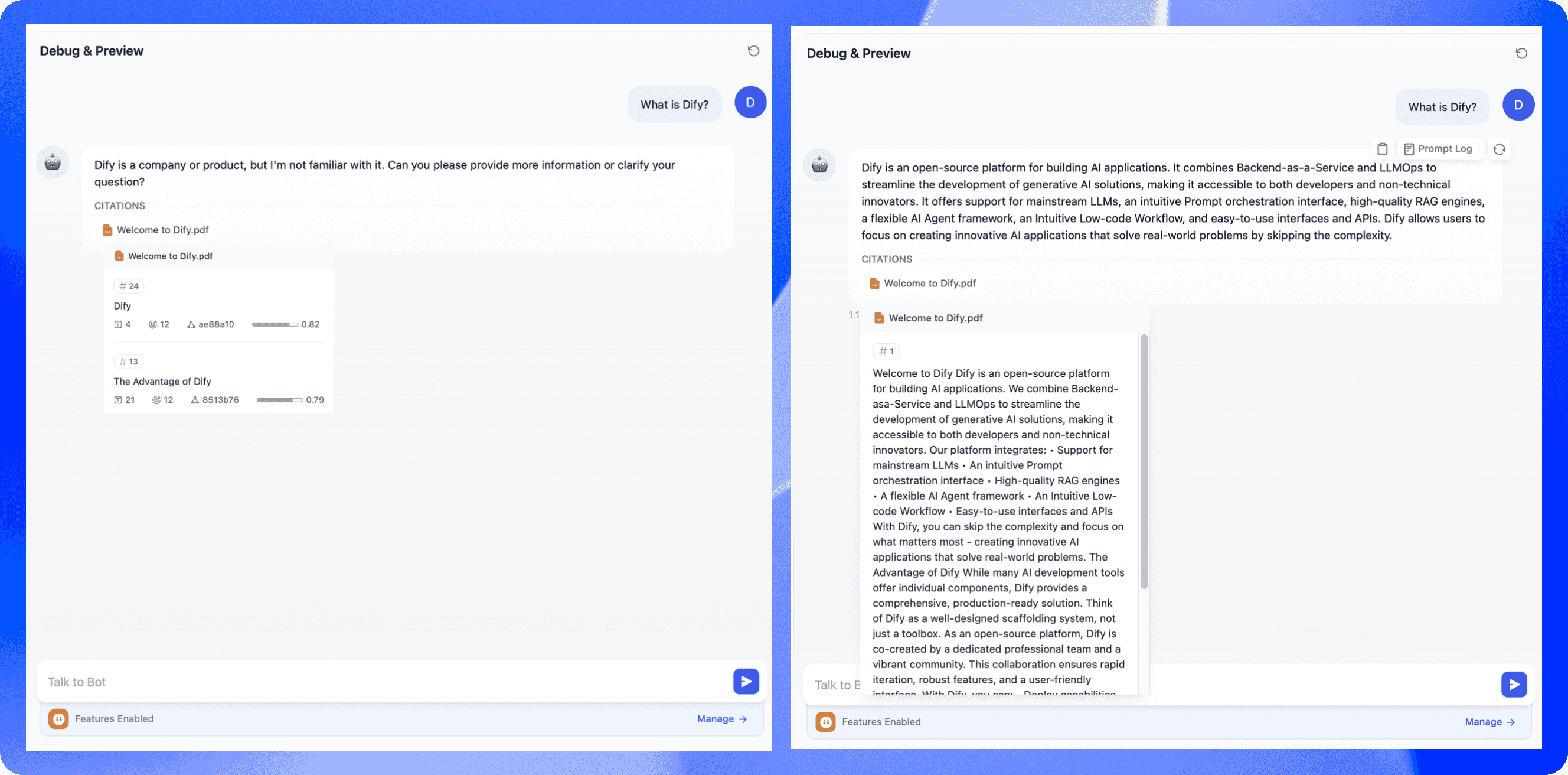
A Step-by-Step Guide to Parent-Child Retrieval
- Data source: Choose a data source and import data to be used as knowledge.
- Chunk Settings: Select General or Parent-child chunking strategy, set parameters to split and clean documents, and preview the results.
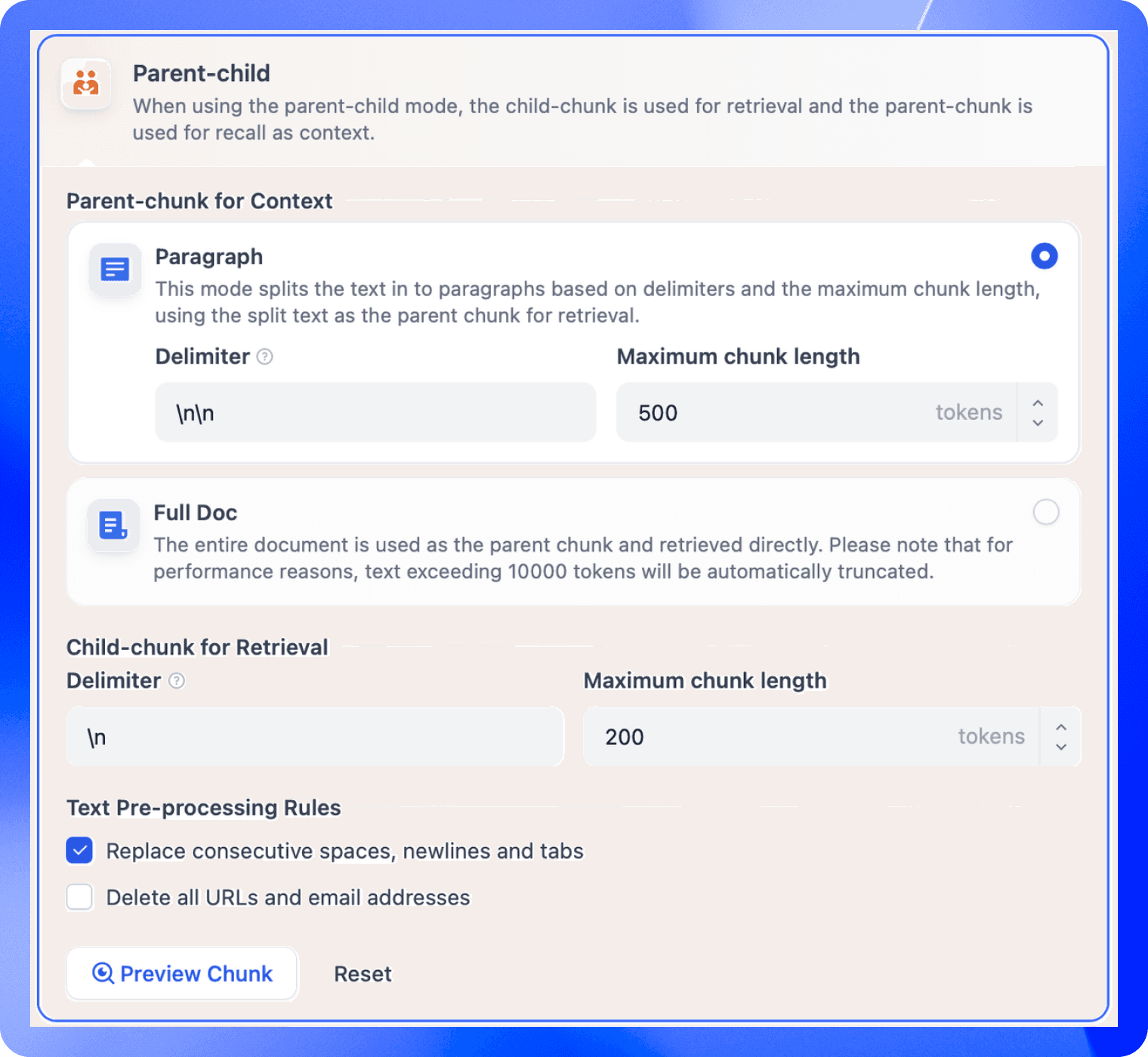
In Parent-child chunking, there are two modes to split parent chunks: Paragraph and Full Doc. - Paragraph: This mode splits the text into paragraphs based on delimiters and the maximum chunk length, using the split text as parent chunks for retrieval. It is better suited for texts with distinct and relatively independent paragraphs.
- Full Doc: The entire document is used as the parent chunk and retrieved directly. Full doc is more applicable when the entire document needs to be retrieved in a cohesive context.
In both modes, child chunks are generated by further splitting the parent chunks based on delimiters and the maximum chunk length.
- Choose and configure Index Method and Retrieval Setting.
- Wait until processing completed and go to documents.
- Edit & Save Parent or Child chunks
While allowing users to edit parent chunks and child chunks separately, we also retain the ability for parent chunks to regenerate child chunks. Its purpose is to allow users to improve retrieval efficiency by editing and adding child chunks as much as possible.
If you edit parent chunks, there are two saving options:
Editing a child chunk does not change the content of the parent chunk. In this way, it allows the user to use child chunk as a customized tag to retrieve this parent chunk.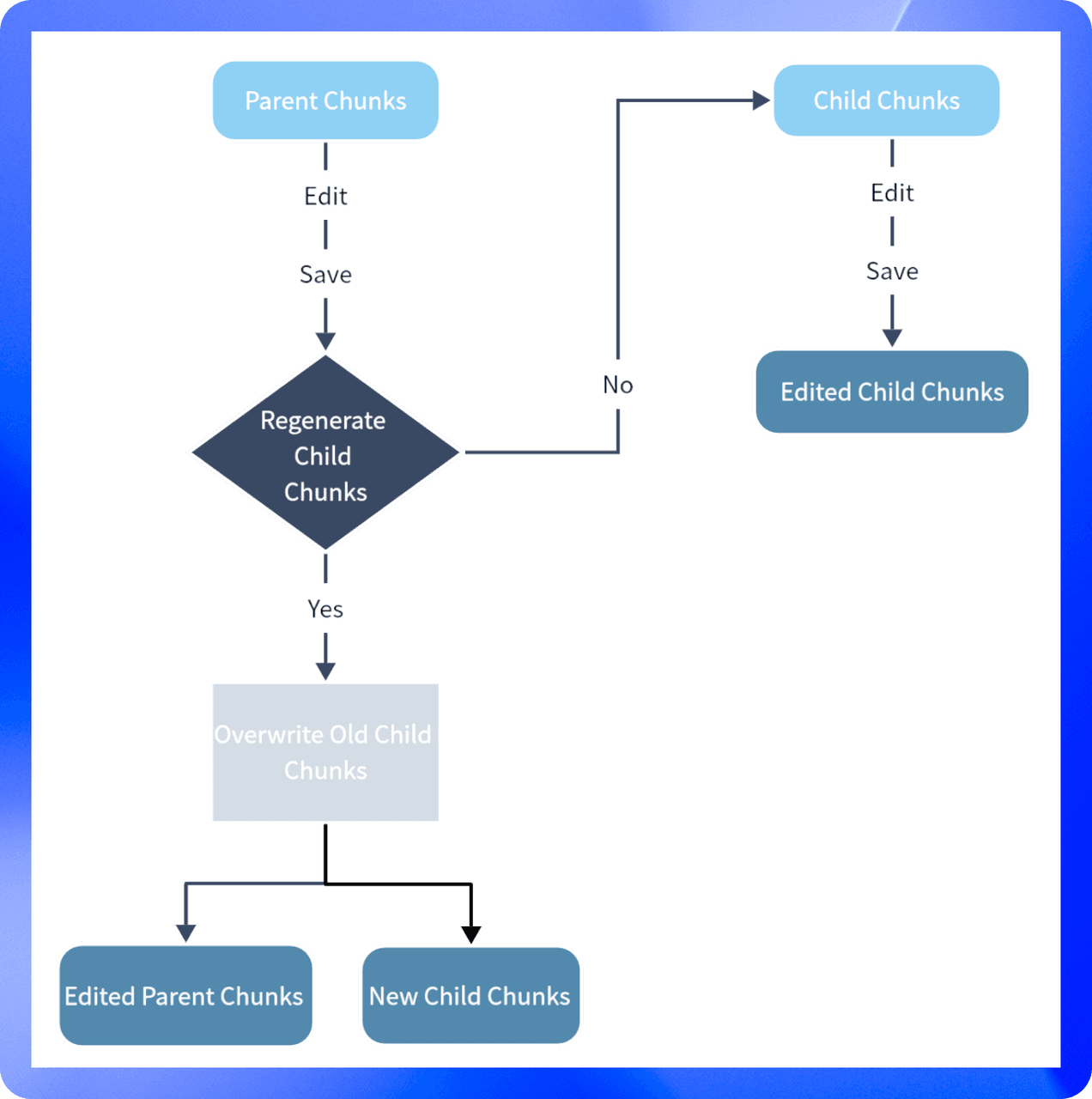
- Not regenerate the child chunks. (default)
- Save and regenerate the child chunks. (with second confirmation)
- Now you can integrate your knowledge with your applications. 🎉
Other highlights of this update
More user-friendly Display of Parent-child Chunks Relation
As a low-code platform, Dify is dedicated to enabling users without technical backgrounds to easily understand and utilize this feature. To achieve this, we have designed a new, user-friendly display for the chunk preview.
- Each parent chunk is a separate module. The child chunks are marked with a gray background color and chunk number at the beginning.
- Hover your mouse on a child chunk, it will be highlighted in blue with word count information.

For retrieval test preview, we put the parent chunk on the left side of a pop-up window with the highest score of hit child chunks. All hit child chunks are listed on the right side highlighted in blue with the corresponding scores.
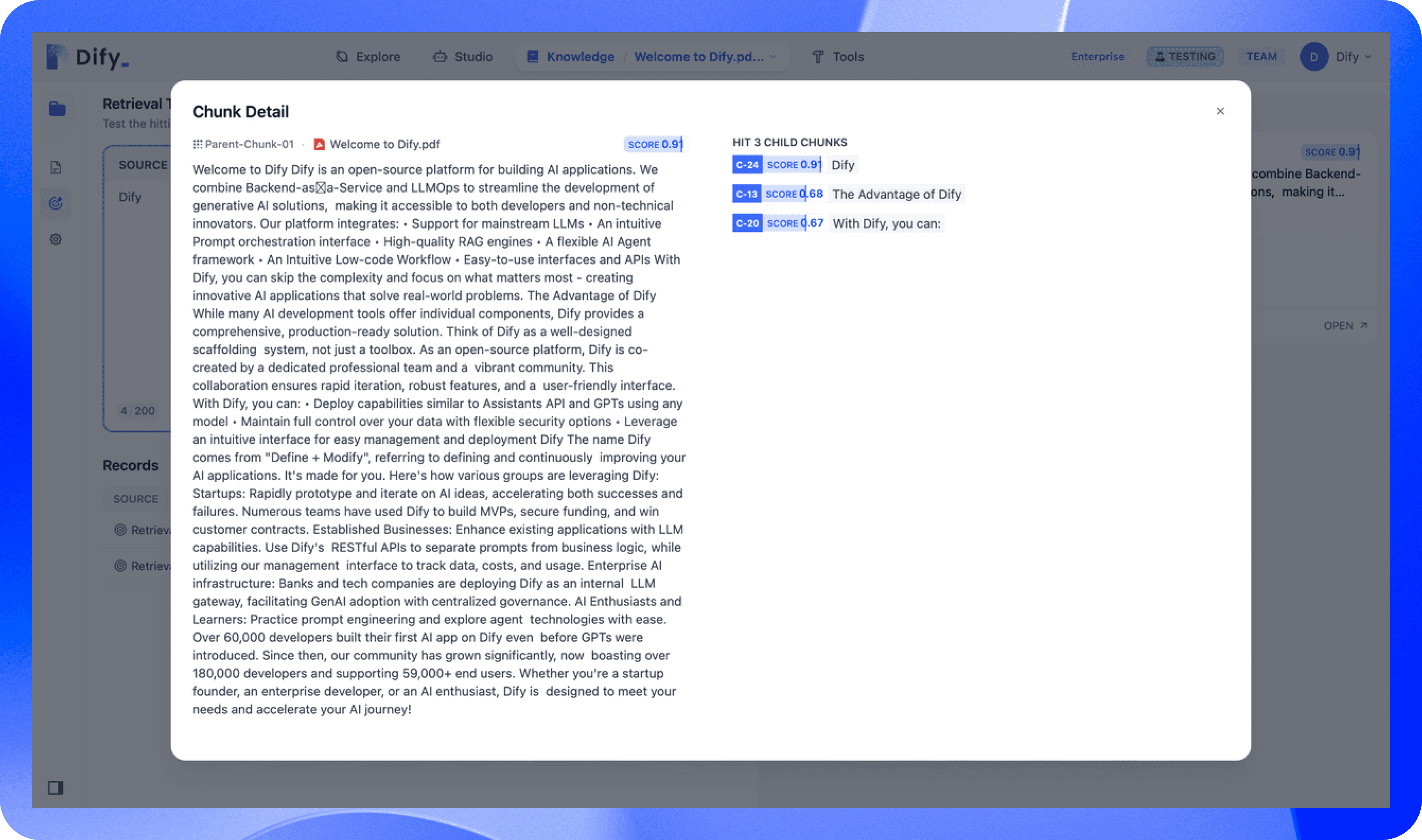
With this update, Dify's Parent-child Retrieval function provides users with more accurate and comprehensive search results, improving the efficiency and accuracy of information acquisition. If you want to know more detailed operations, please refer to the Knowledge Base|Dify documentation for detailed instructions and experience it yourself on Dify.AI!
Related articles
- Product
Now on Dify Marketplace: Qubrid AI Brings Multi-Model Access to Every Dify Workflow
Install the Qubrid AI plugin on Dify to unlock unified access to DeepSeek, Kimi, Qwen, MiniMax, GLM, and more, all through one API key.

 Qubrid AI & Dify
Qubrid AI & Dify - Product
Grounding Dify Agents in Real Data: MongoDB Atlas and Voyage AI Are Now Native to Dify RAG Workflows
Dify and MongoDB make it easier to build grounded AI agents that retrieve, reason over, and act on real business data, without stitching together custom RAG infrastructure from scratch.
 MongoDB & Dify
MongoDB & Dify - Product
Dify Creator Center & Template Marketplace: Share Your Workflows
Dify’s new Creator Center and Template Marketplace let creators publish workflow templates and users discover and one-click adopt them, with optional PartnerStack affiliate linking to earn recurring commissions from subscriptions driven by template links.
Dify - Product
Try OpenAI, Claude, Gemini & Grok Free on Dify Cloud
Supports OpenAI, Claude, Gemini, and Grok. Try curated templates with zero configuration.
Dify