











Today we are introducing the new Knowledge Pipeline, a visual pipeline that turns messy enterprise data into high quality context for LLMs.
In most enterprises, the bottleneck is not the model. It is context engineering on unstructured data. Critical information sits in PDFs, PPT, Excel, images, HTML, and more. The challenge is to convert scattered, heterogeneous, and constantly changing internal data into reliable context that LLMs can consume. This is not simple import work. It is an engineered process that needs design, tuning, and observability.
Traditional RAG often struggles on enterprise data due to three issues:
- Fragmented sources. Data lives across ERP, wikis, email, and drives, each with its own auth and format, making point by point integration costly.
- Parsing loss. After parsing, documents become unstructured text with charts and formulas dropped, and when naive chunking further breaks document logic, LLMs end up answering from incomplete fragments.
- Black box processing. Little visibility into each step makes it hard to tell whether failures come from parsing, chunking, or embedding, and reproducing errors is painful.
Knowledge Pipeline provides the missing data infrastructure for context engineering. With a visual pipeline, teams control the entire path from raw sources to trustworthy context.
Visual and orchestrated Knowledge Pipeline
Knowledge Pipeline inherits Dify Workflow’s canvas experience and makes the RAG ETL path visible. Each step is a node. From source connection and document parsing to chunking strategies, you choose the right plugin for text, images, tables, and scans. Backed by the Dify Marketplace, teams assemble document processing lines like building blocks and tailor flows by industry and data type.
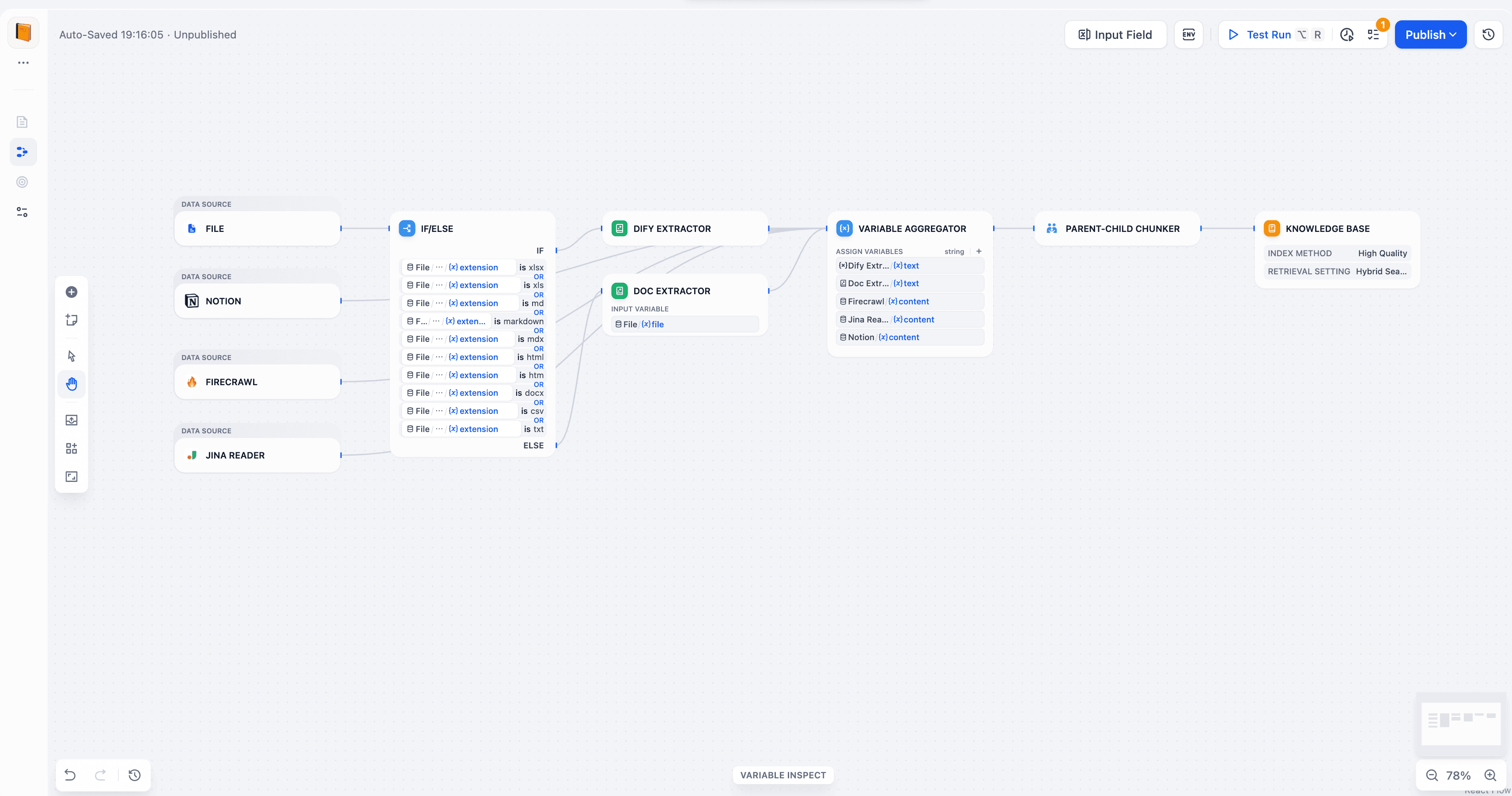
When needed, you can embed Workflow nodes such as If-else, Code, and LLM into the pipeline. Use a model for content enrichment and code for rule based cleaning to achieve true flexibility.
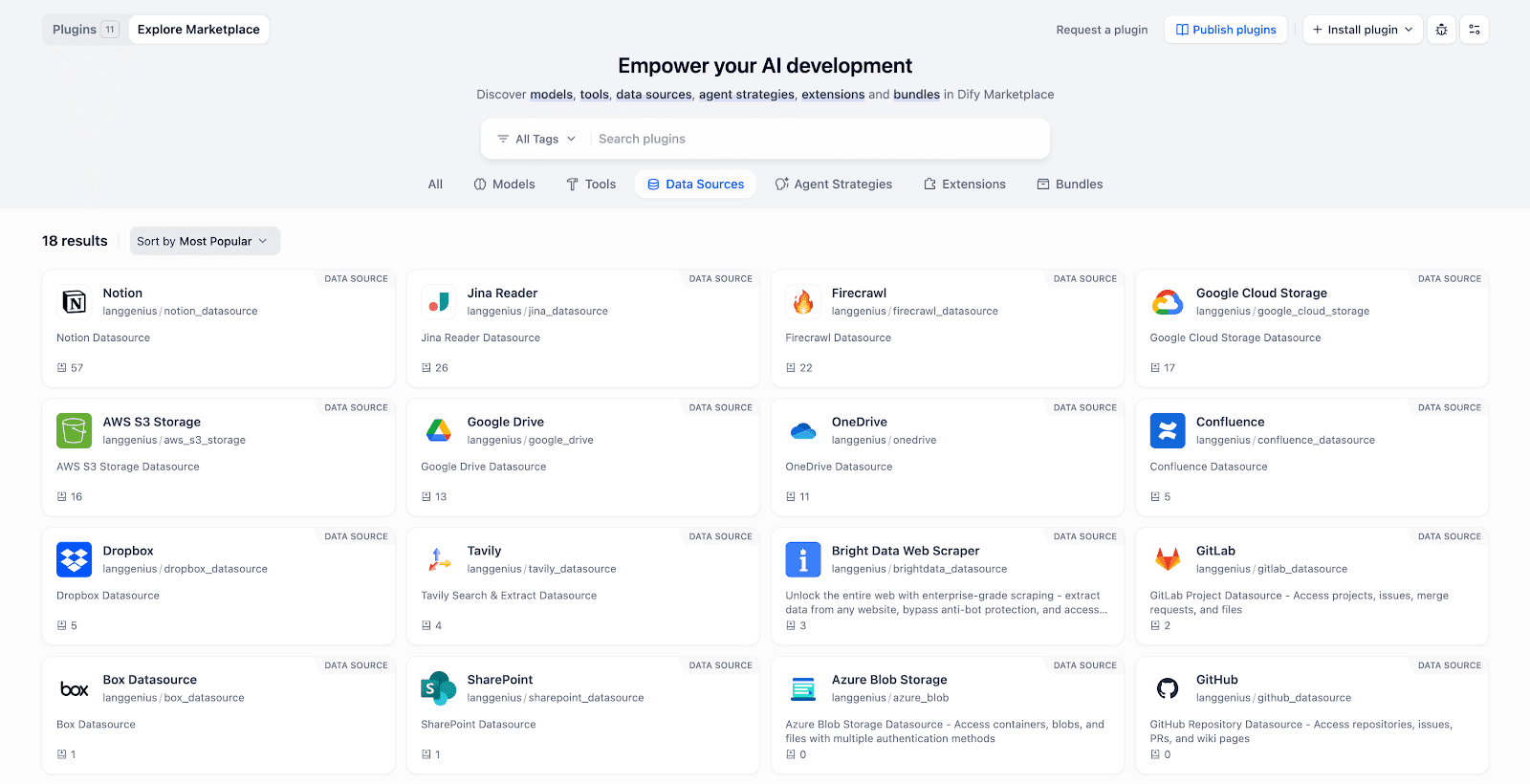
1. Enterprise grade data source integrations
Knowledge Pipeline brings Data Source as a new plugin type, letting each knowledge base connect to multiple unstructured sources without custom adapters or auth code. Grab what you need from the Marketplace, or use the standard interfaces to build connectors for your own systems.
Covered sources include:
- Local files: 30 plus formats such as PDF, Word, Excel, PPT, Markdown
- Cloud storage: Google Drive, AWS S3, Azure Blob, Box, OneDrive, Dropbox
- Online docs: Notion, Confluence, SharePoint, GitLab, GitHub
- Web crawling: Firecrawl, Jina, Bright Data, Tavily
2. Pluggable data processing pipeline
We've broken processing into standard nodes to make the pipeline predictable and extensible. You can swap plugins based on your scenario.
- Extract
Ingestion from many sources. The next steps adapt to the upstream output type, whether file objects or page content, including text and images.
- Transform
The core of the pipeline, composed of four stages:
- Parse: Choose the optimal parser per file type, extract text and structured metadata. For scans, tables, or PPT text box ordering, run multiple parsers in parallel to avoid loss.
- Enrich: Use LLM and Code nodes for entity extraction, summarization, classification, redaction, and more.
- Chunk: Three strategies are available: General, Parent-Child, and Q&A, covering common documents, long technical files, and structured table queries.
- Embed: Choose embeddings by cost, language, and dimension from different providers.
- Load
Write vectors and metadata into the knowledge base and build efficient indexes. Support high quality vector indexes and cost efficient inverted indexes. Configure metadata tags for precise filtering and access control.
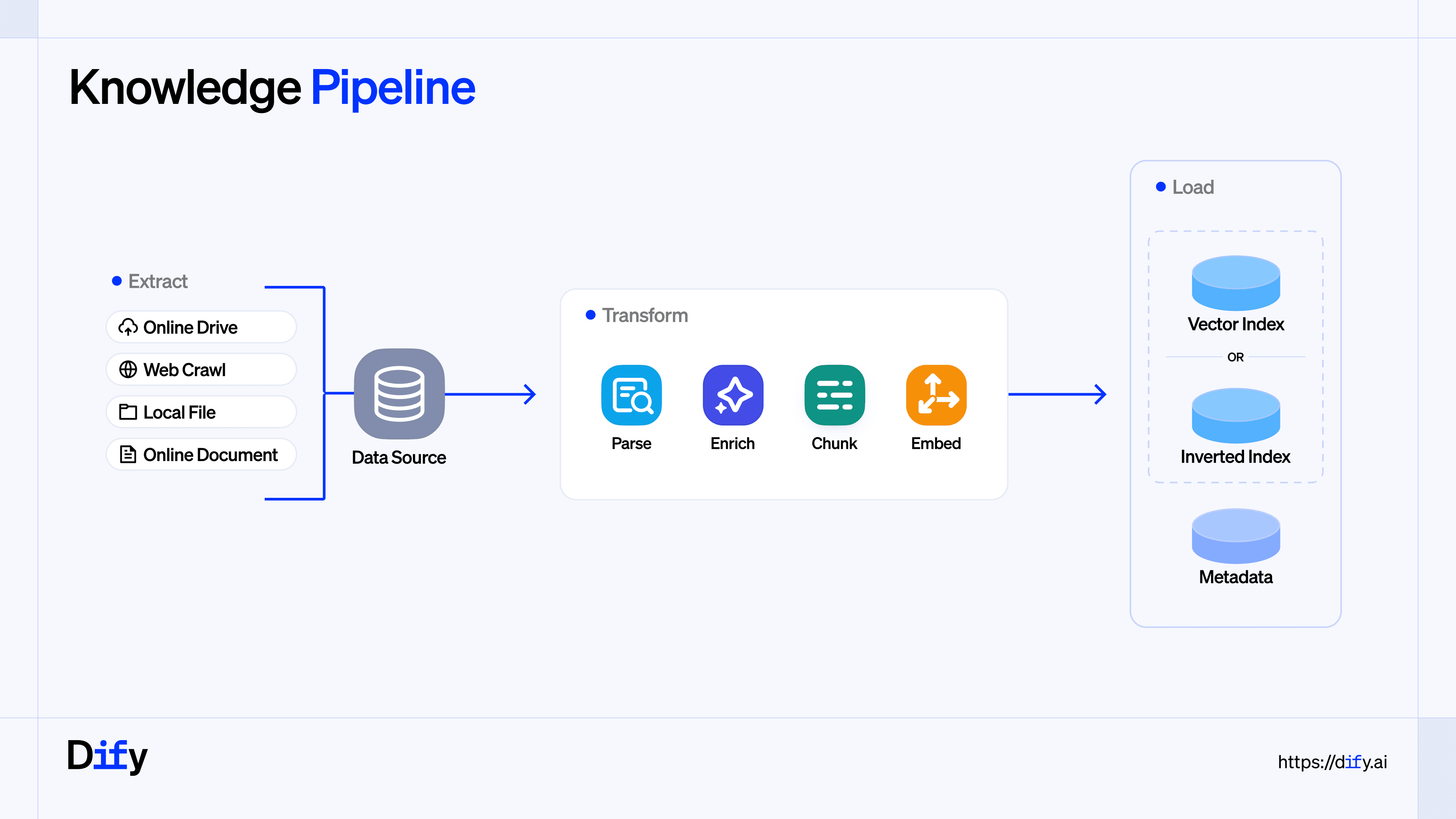
After processing, retrieval supports vector, full text, or hybrid strategies. Use metadata filters and reranking to return precise results with original citations, and an LLM organizes the final answer with mixed text and images for better accuracy and experience.
3. Observable debugging
Legacy pipelines behave like a black box. With Knowledge Pipeline you can Test Run the entire flow step by step and inspect inputs and outputs at each node. The Variable Inspect panel shows intermediate variables and context in real time, so you can quickly locate parsing errors, chunking issues, or missing metadata.
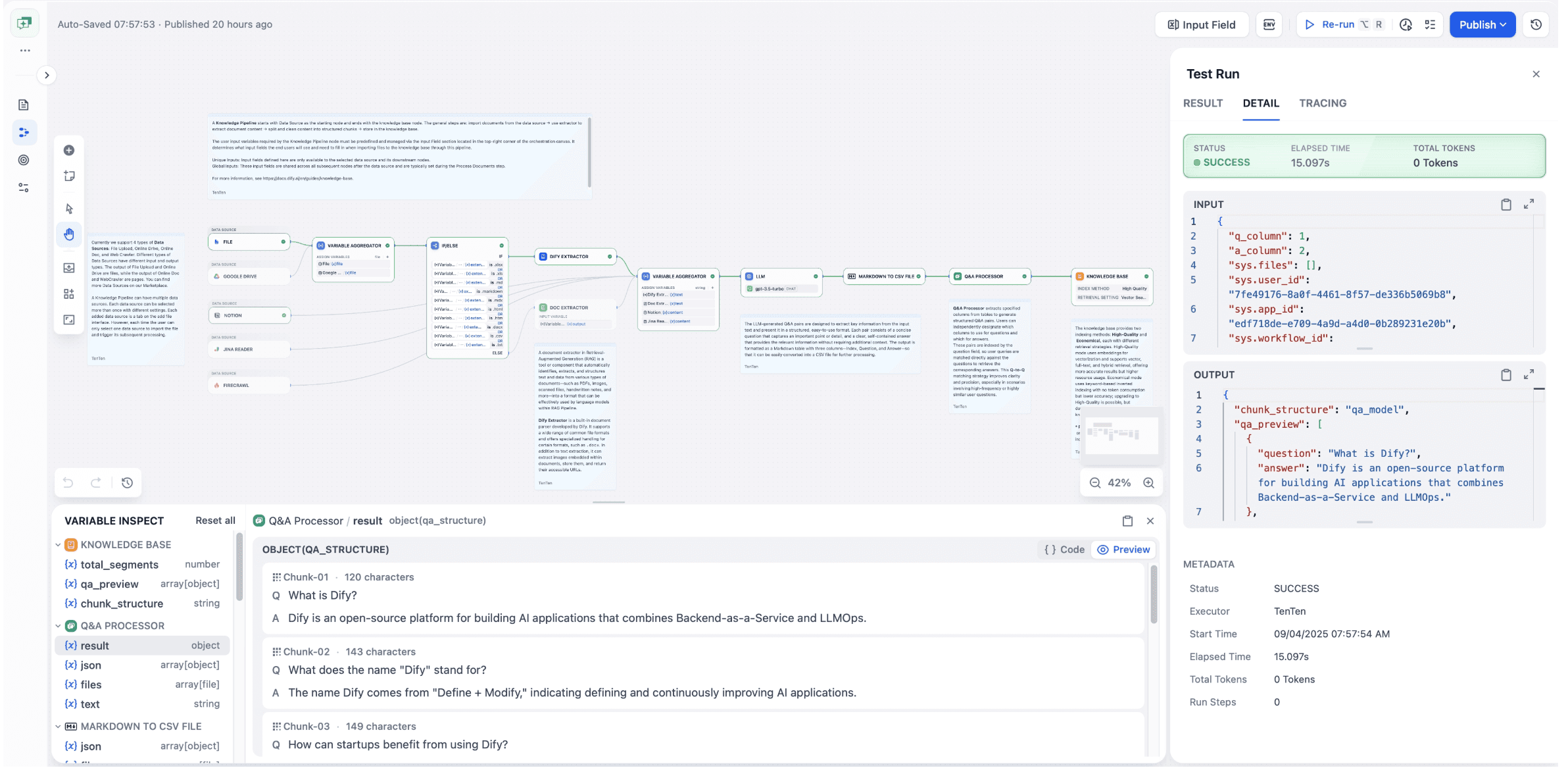
Once validation is complete, publish the pipeline and move into standardized processing.
See the docs for detailed guidance.
4. Templates for common scenarios
Seven built in templates help you start fast:
- General document processing - General Mode (ECO)
Split into general paragraph chunks with economical indexing. Good for large batches. - Long document processing - Parent‑Child (HQ)
Hierarchical parent‑child chunking that preserves local precision and global context. Ideal for long technical docs and reports. - Table data extraction - Simple Q&A
Extract selected columns from tables and build structured question answer pairs for natural language queries. - Complex PDF parsing - Complex PDF with Images & Tables
Targeted extraction of images and tables from PDFs for downstream multimodal search. - Multimodal enrichment - Contextual Enrichment Using LLM
Let an LLM describe images and tables to improve retrieval. - Document format conversion - Convert to Markdown
Convert Office formats to Markdown for speed and compatibility. - Intelligent Q&A generation - LLM Generated Q&A
Produce key question answer sets from long documents to create precise knowledge points
RAG plugin ecosystem
Dify provides an open plugin ecosystem built by the team, partners, and community. With a plugin based architecture, enterprises select tools that fit their needs.
- Connector: Google Drive, Notion, Confluence, and many more
- Ingestion: LlamaParse, Unstructured, OCR tools
- Storage: Qdrant, Weaviate, Milvus, Oracle and other leading vector databases, customizable for enterprise and open-source deployments

Why Knowledge Pipeline
Knowledge Pipeline operationalizes context engineering. It converts unstructured enterprise data into high quality context that powers retrieval, reasoning, and applications.
Three core benefits
Bridge business and data engineering
- Visual orchestration and real time debugging let business teams participate directly. They can see how data is processed and help troubleshoot retrieval, while engineering focuses on growth critical work.
Lower build and maintenance cost
- Many RAG projects are one off builds. Knowledge Pipeline turns processing into reusable assets. Contracts review, support knowledge bases, and technical docs become templates that teams can copy and adapt, reducing rebuilds and ongoing effort.
Adopt best-of-breed vendors
- No need to choose between full in house or a single vendor. Swap OCR, parsing, structured extraction, vector stores, and rerankers at any time while keeping the overall architecture stable.
What’s next
In the latest version, we rebuilt the Workflow engine around a queued graph execution model. The new engine removes limits in complex parallel scenarios and enables more flexible node wiring and control. Pipelines can start from any node, pause and resume in the middle, and lay the groundwork for breakpoints, human-in-the-loop, and trigger based execution.
Start orchestrating enterprise-grade Knowledge Pipelines.
Related articles
- Product
Now on Dify Marketplace: Qubrid AI Brings Multi-Model Access to Every Dify Workflow
Install the Qubrid AI plugin on Dify to unlock unified access to DeepSeek, Kimi, Qwen, MiniMax, GLM, and more, all through one API key.

 Qubrid AI & Dify
Qubrid AI & Dify - Product
Grounding Dify Agents in Real Data: MongoDB Atlas and Voyage AI Are Now Native to Dify RAG Workflows
Dify and MongoDB make it easier to build grounded AI agents that retrieve, reason over, and act on real business data, without stitching together custom RAG infrastructure from scratch.
 MongoDB & Dify
MongoDB & Dify - Product
Dify Creator Center & Template Marketplace: Share Your Workflows
Dify’s new Creator Center and Template Marketplace let creators publish workflow templates and users discover and one-click adopt them, with optional PartnerStack affiliate linking to earn recurring commissions from subscriptions driven by template links.
Dify - Product
Try OpenAI, Claude, Gemini & Grok Free on Dify Cloud
Supports OpenAI, Claude, Gemini, and Grok. Try curated templates with zero configuration.
Dify