











Hi, it’s Yeuoly! I’m the backend engineer at Dify.AI and the creator of DifySandbox.
For our community users, the DifySandbox service should be familiar. It's a docker service running in the background of Dify. We've received a lot of feedback about it, but most users are unfamiliar with the DifySandbox itself and unclear about its internal details. This blog will gradually help you understand what's happening inside DifySandbox.
DifySandbox for Code Execution and Security
In Dify, Workflow is a crucial feature that allows users to orchestrate a logic flow through drag-and-drop, enabling relatively complex business logic. During the process of orchestrating logic, data processing is essential. Specifically, we may encounter the following scenarios:
- We often find ourselves needing to process JSON text created by LLMs to extract structured data from it. Additionally, we have to handle XML or JSON text received from HTTP requests, parsing it into structured data and extracting information from it.
- In some cases, we may need to combine the output content from two knowledge retrieval nodes or merge the results from both the google search node and the knowledge retrieval node.
- In more situations, individuals with basic programming skills may want to utilize template syntaxes such as Jinja2 and Liquid to achieve more adaptable prompt orchestration.
Even though these scenarios are diverse, they all involve data processing and require a unified solution. Naturally, the first thing that comes to mind is writing code to implement this, as it's more versatile compared to highly customized data processing nodes. No one wants a specific node to be responsible for parsing JSON text. So, why not provide users with a code editing box where they can write their own code to implement data processing logic? We could even wrap the LLM node with a template formatted based so that we can achieve a more flexible way to orchestrate prompts. All of the above issues can be easily resolved in this manner.
As we need to execute user-written code in Dify, we must address security issues. When dealing with malicious users, code execution becomes a vulnerability instead of a normal feature.
Typically, the majority of requests made to Dify are not intended to cause harm. Whether it involves running code or accessing workspace information, all requests must be routed through Dify. When it comes to code execution, this involves initiating a new Python or Node.js process on the server and sending the user's code to this process for execution.
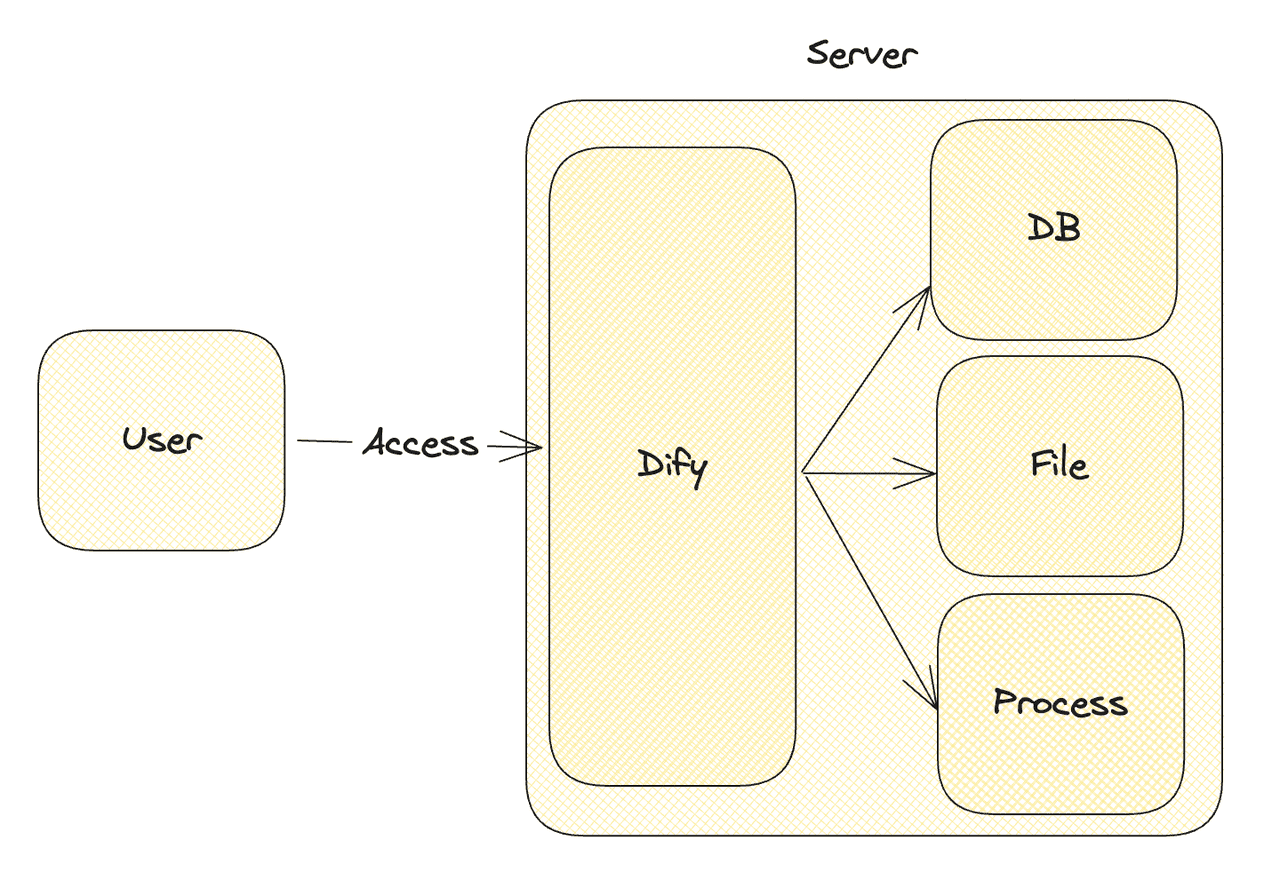
When Process falls into the hands of malicious users, it becomes problematic. Since Process runs directly on the server, it has access to both the file system and database. Code written by malicious users could potentially read any file on the server or even gain access to and manipulate the entire Dify database.
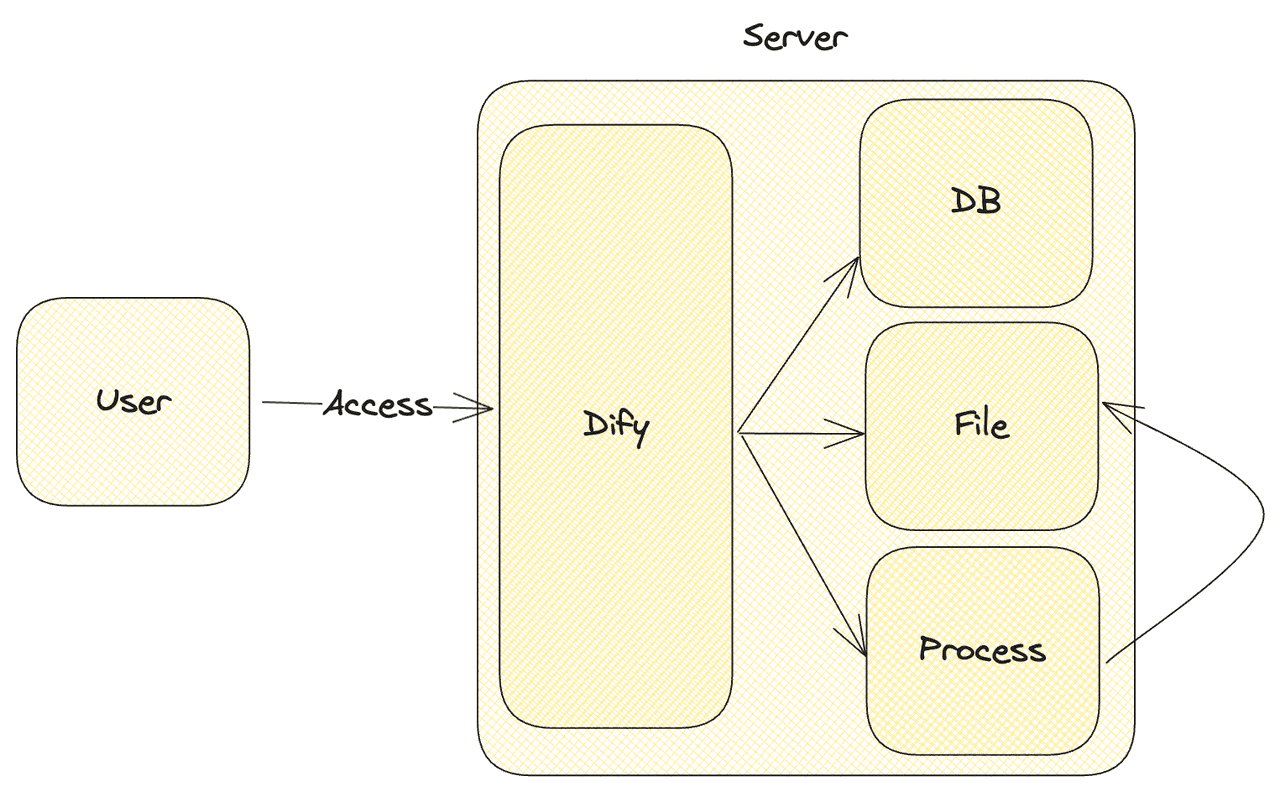
To address this, we have developed Difysandbox, a code sandbox solution that effectively blocks malicious code while allowing normal business operations to continue. In the following sections, we will provide a detailed overview of DifySandbox.
Design and Implementation of DifySandbox
Before we began the design process, we carefully considered several security requirements for the sandbox.
- We considered that developers around the world have different coding preferences. In the realm of LLMs, Python and Node.js are clearly the top two choices. However, we don't want to limit users to only using Python or Node.js, so we aim to provide both options. As a result, the technical solution for the Sandbox should not be tied to a specific language but should offer a comprehensive system-level solution.
- Is it possible to bypass the Sandbox? It is certainly impossible to prevent this entirely, as no system is absolutely secure. Therefore, we cannot solely rely on the sandbox itself for security. Instead, we should ensure that even if vulnerabilities exist in the Sandbox, hackers cannot access core resources.
- The network is a major concern with far-reaching consequences.
- Many sandbox bypasses in production environments occur due to network vulnerabilities, such as in VMWare, where numerous vulnerabilities are exploited through the network.
- Even with code-level and system-level protections in place, it's still challenging to prevent malicious code from sniffing internal networks and illegally accessing internal resources. Therefore, the sandbox must also consider how to isolate the network.
At the same time, we also examined existing sandbox solutions globally. Here's an overview of their pros and cons:
- WebAssembly: This a popular sandbox solution that compiles Python or Node.js interpreters into a WebAssembly runtime. This enables Python code to run in Node.js or web browsers. When used correctly, WebAssembly provides strong security at the system level. However, it has limitations. For example, installing third-party dependencies can cause problems such as architecture incompatibility. Furthermore, Python and Node.js require different handling, which makes WebAssembly less versatile.
- Docker: Some providers generate a new Docker container for each code execution request. While this approach offers great flexibility, it results in extremely slow execution speeds, taking 1+ seconds per run. In a workflow with 10 code nodes, this could accumulate to 10+ seconds, which is a significant performance drawback. Furthermore, this method entails managing containers and mounting the
docker daemon'ssockto Dify'sapicontainers, leading to significant security risks. Alternatively, usingdocker-in-dockeris even slower, making neither option ideal. - Language-specific sandbox packages: These include vm2 for Node.js and PyPy for Python. However, these packages are limited to specific languages and come with their own limitations. They are not universal solutions and require adherence to language-specific standards when managing dependencies. For example, PyPy has strict Python version limitations, and managing dependencies is not easy. While there are libraries like Pyodide, the main challenge is that Node.js and Python solutions are not interchangeable, which makes maintenance difficult.
- Kernel extensions: They are utilized by some well-established sandbox solutions to limit process behavior. However, they often come with complex configuration documentation and startup processes. Examples of such solutions include Sandboxie and judge0. Although these are kernel-level solutions, Judge0 has experienced a severe CVE in the past due to configuration issues. These solutions require privileged containers for kernel extensions, which means that if their restrictions are bypassed, Docker's limitations also become ineffective.
It appears that the existing solutions do not entirely meet our business requirements. They have shortcomings in various areas, such as slow execution speed, incompatible language features, or possible security risks. Therefore, we have made the decision to create our own solution with the following key features:
- Multi-layer isolation: We implement multi-layer isolation using Docker containers but with a unique approach. Instead of creating a new Docker container for each task, we only launch a single sandbox container during the startup phase. This container runs an internal
httpservice that receives code execution requests from our system. It's important to note that this approach restricts the system from running on Linux, while Windows and Mac platforms require tools like Docker Desktop or Orbstack. - System-level isolation: On Linux, Docker is a common system sandbox solution. However, since we've already implemented one layer of Docker, we need to leverage Docker's underlying technology: Seccomp (Secure Computing Mode).
Seccompacts as a filter for all attempts to access the system. It intercepts and controls various operations, including, but not limited to, file read/write operations, system configuration modifications, network access, and even standard input/output. This works because these operations are essentiallysystem calls(syscalls), and eachsyscallrepresents an attempt to access the system. The flow of these operations is listed below.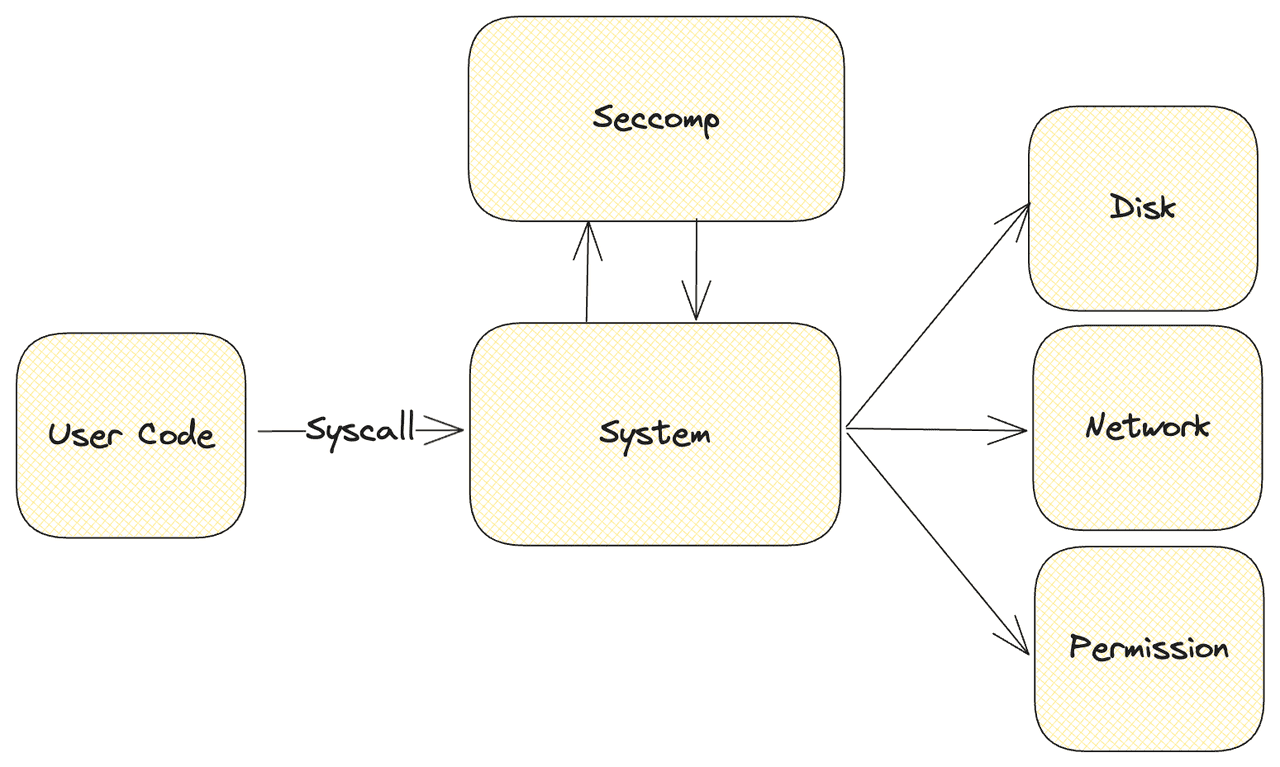
By implementingSeccomp, we can capture any attempts made by a process to execute unauthorizedsyscalls. This typically includes capturing file access, process creation, disk mounting, and system modifications.
However, each chip architecture has its own unique syscall system with a large number of syscalls. For instance, the syscall number for writing a file is 2 on amd64 but 64 on arm64. AMD64 has over 300 syscalls, while arm64 has more than 400. Using a blacklist strategy could unintentionally allow certain syscalls, posing significant security risks. Therefore, DifySandbox uses a whitelist strategy, permitting only necessary permissions while intercepting all non-essential ones.
- At the file system level, we need to create a virtualized file system for the child processes of the sandbox. This separation isolates the file system of the sandbox host container from the file system of the processes running user code within the sandbox. The main reason for this is that
Seccompcan only allow or deny access to all files. To have more precise control, we need certain files to be accessible as usual, such as Python's third-party dependencies, while others like sensitive files such as/etc/passwd, should be inaccessible. Taking these factors into account, we need to isolate a separate file system, which is where Linux'schroot(change root) comes in. It allows us to change a process's root directory to a temporary directory. For example, after executingchroot("/tmp")in a Python process, when that Python process runsls /, it will only see the files that were originally under/tmp. This effectively isolates the file system. As shown in the diagram below, each sandbox folder ultimately becomes the root directory for a specific sandbox process.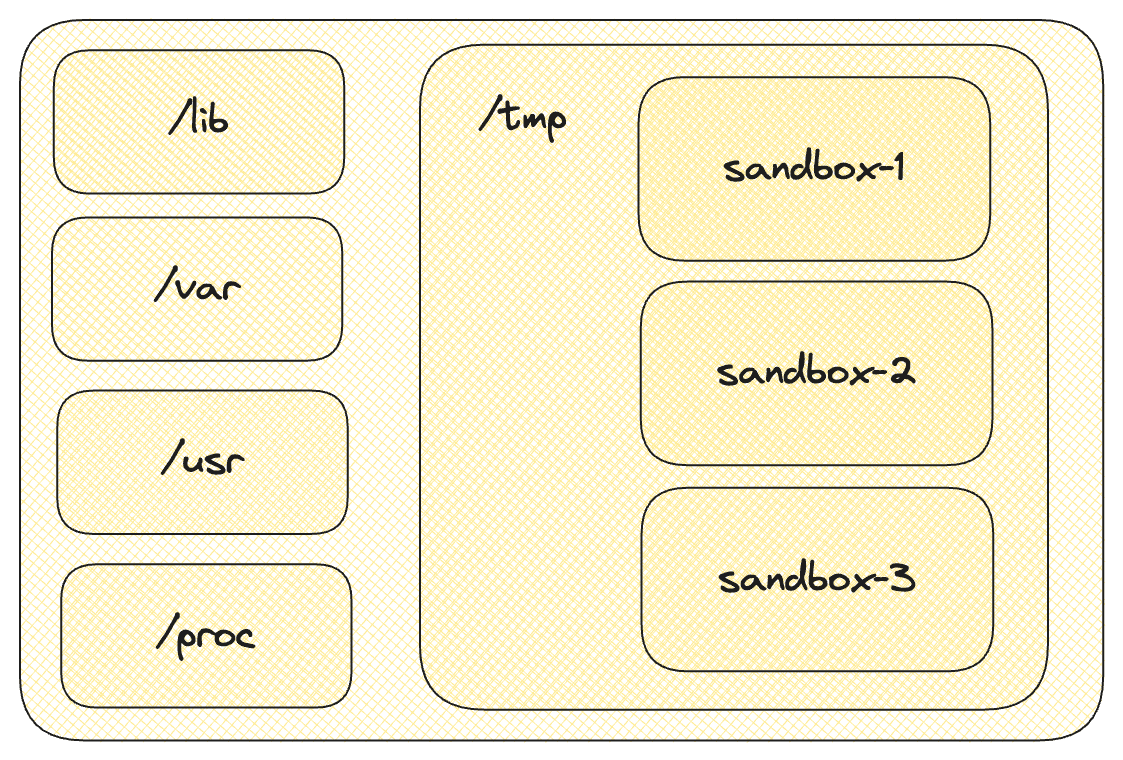
However,chroothas some bypass vulnerabilities. Ifchrootis applied again to a subdirectory, it becomes possible to use "cd .." to access directories outside the chroot environment that should be inaccessible. Sincechrootrequires root privileges, we need to change the process privileges before entering user-written code logic, transferring the current user/group of the process to a non-root user/group. There are also some system calls likeopenatthat can potentially bypass chroot restrictions, but these issues can be addressed through detailed protective measures, which we won't elaborate on here. - It's not a good idea to handle everything directly within the Docker sandbox from a networking perspective. Firstly, Docker's limitations on
iptablesmake it difficult to configure system-level network policies without a Kubernetes environment. Secondly, network configuration is a complex task that requires a flexible approach, as there is no one-size-fits-all strategy. Moreover, network isolation policies differ significantly betweenk8sanddocker-compose. Therefore, our plan is to develop separate solutions fork8sanddocker-compose. - In
docker-compose, we create aninternalnetwork for the sandbox and then introduce aproxycontainer to connect to the external network. Thisproxycontainer serves as the intermediary for the sandbox. By configuringproxyrules on the proxy container, we can achieve flexible configuration using proxy services like Squid.
The network structure is as follows: The Sandbox is located within theSSRF_PROXY_NET, which is an internal network that cannot access external resources. Theproxycontainer is also within this network and theDEFAULTnetwork. This setup allows theproxyto act as an intermediary for accessing external networks and enables the configuration of highly flexible networkproxyrules to ensure intranet security.
It's worth noting that Dify itself also utilizes aproxycontainer, which can be reused there. This is because certain features, such as HTTP nodes, may pose security risks. Therefore, all such connections are uniformly managed through theproxy's rules configuration.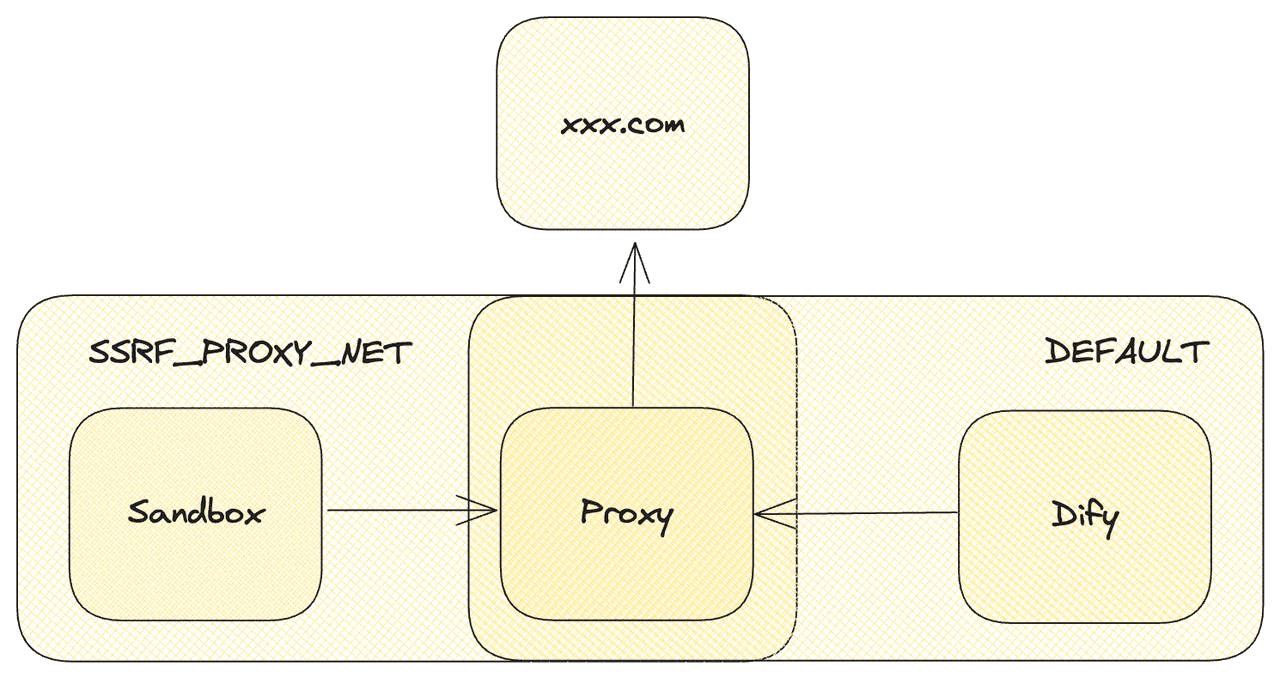
- When using
k8s, everything becomes easier. Configuring egress rules is all you need to do.
- In
Conclusion
DifySandbox is a sandbox runtime designed to utilize Linux's native capabilities without being dependent on specific programming languages. Its main goal is to provide Dify with a secure environment for executing code, ensuring that user code can run safely while offering enhanced functionality. To ensure security, we have implemented comprehensive isolation strategies across various aspects, including system, disk, file system, network, and permissions. We have also employed multi-layered isolation to avoid the use of privileged operations.
However, there are still some limitations to address. For example, managing dependencies for Python and Node.js remains challenging. Despite implementing measures for Python dependencies, certain issues persist. Additionally, our whitelist approach may inadvertently block legitimate behaviors in Python and Node.js. We are committed to further optimizing the sandbox to enhance the user experience.
We're excited to announce that DifySandbox is now open-source! This move aligns with our commitment to open-source principles and aims to expand the possibilities for DifySandbox. We welcome everyone to join us in shaping the future of the sandbox, including potential improvements like image processing, flexible data analysis, and creating images and videos.
Related articles
- Product
Now on Dify Marketplace: Qubrid AI Brings Multi-Model Access to Every Dify Workflow
Install the Qubrid AI plugin on Dify to unlock unified access to DeepSeek, Kimi, Qwen, MiniMax, GLM, and more, all through one API key.

 Qubrid AI & Dify
Qubrid AI & Dify - Product
Grounding Dify Agents in Real Data: MongoDB Atlas and Voyage AI Are Now Native to Dify RAG Workflows
Dify and MongoDB make it easier to build grounded AI agents that retrieve, reason over, and act on real business data, without stitching together custom RAG infrastructure from scratch.
 MongoDB & Dify
MongoDB & Dify - Product
Dify Creator Center & Template Marketplace: Share Your Workflows
Dify’s new Creator Center and Template Marketplace let creators publish workflow templates and users discover and one-click adopt them, with optional PartnerStack affiliate linking to earn recurring commissions from subscriptions driven by template links.
Dify - Product
Try OpenAI, Claude, Gemini & Grok Free on Dify Cloud
Supports OpenAI, Claude, Gemini, and Grok. Try curated templates with zero configuration.
Dify