










Dify x TiDB: Supercharge Your Knowledge Pipeline with Distributed Vector Storage
Dify has integrated TiDB Vector into knowledge pipeline to support distributed semantic search, accelerate knowledge retrieval speed, and provide scalable context management functions for production-level AI applications.

We’re excited to share that Dify’s Knowledge Pipeline now officially integrates with TiDB Vector, a high-performance distributed vector database, strengthening our data foundation for large-scale, intelligent retrieval.
A few weeks ago, we launched the Knowledge Pipeline to help developers build modular RAG workflows for knowledge ingestion, parsing, and embedding. With the integration of TiDB Vector, developers can seamlessly reuse the processed knowledge, such as parsed tables, extracted entities, and embedded text, across downstream AI applications like Agent Workflows or Chatflows.
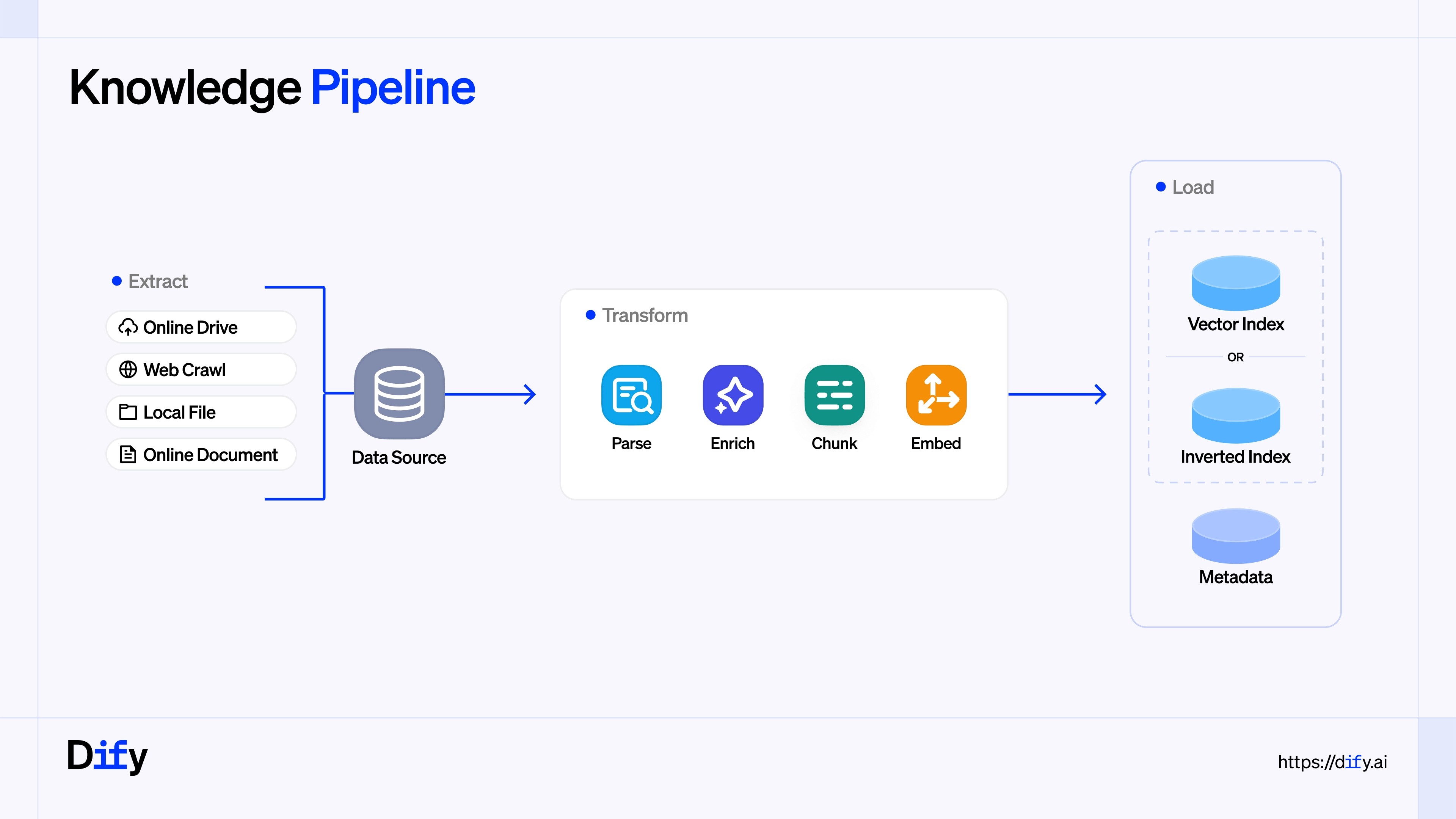
TiDB Vector provides a unified, high-performance data layer that supports hybrid SQL + vector search, enabling developers to use SQL syntax to filter structured metadata before performing semantic retrieval. This ensures precise, context-aware responses while maintaining enterprise-grade scalability and stability through TiDB’s distributed architecture.
Quick Start: Configuring TiDB Vector with Dify
Prerequisites
Make sure that you have deployed Dify locally and created a TiDB Cloud account.
I. Create a TiDB Vector cluster on TiDB Cloud:
- Create a cluster, and configure the relevant information
- Initialize a schema:
create schema dify;
- Get Cluster Properties, note: HOST, PORT=4000, USER, PASSWORD, DATABASE.
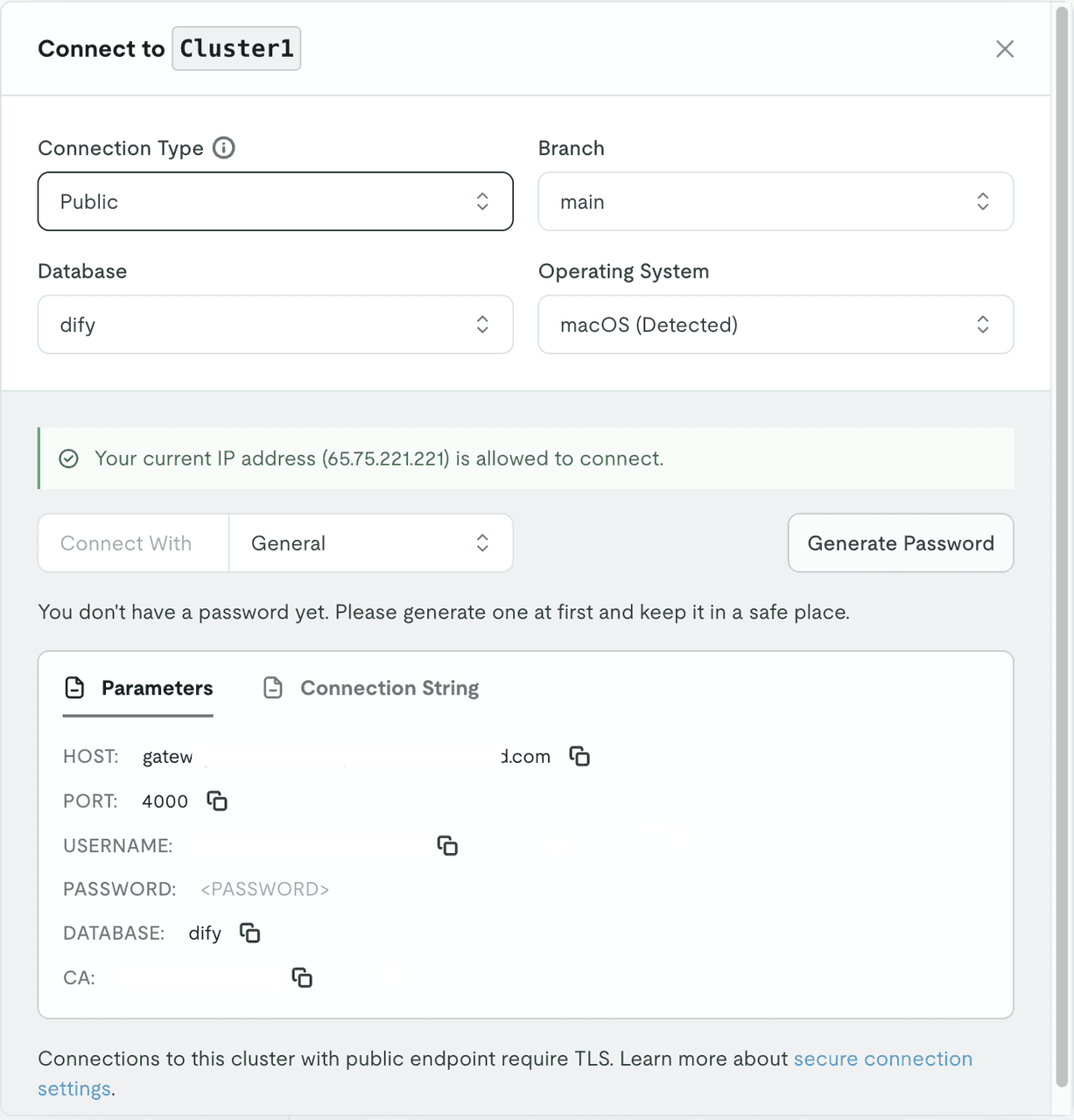
II. Set Dify environment:
In docker-compose.yaml, update both api and worker service environments using values from your TiDB cluster properties:
# Use TiDB Vector as the vector store
VECTOR_STORE: tidb_vector
# Fill in the relevant information
TIDB_VECTOR_HOST: gateway01.eu-central-1.prod.aws.tidbcloud.com
TIDB_VECTOR_PORT: 4000
TIDB_VECTOR_USER: <your_user>.root
TIDB_VECTOR_PASSWORD: <your_password>
TIDB_VECTOR_DATABASE: dify
III. Upload and Process Data in the Pipeline:
In Dify, you can create Knowledge Pipelines to process unstructured data before storing it in TiDB. The pipeline automatically handles extraction, chunking, embedding, and storage of vectors into TiDB Vector, according to your configuration.
We make setup easier with several ready-to-use processing templates. You can simply pick from several pre-built templates designed for common scenarios — for instance, efficient processing for general documents, advanced parent-child chunking for lengthy technical manuals, or structured Q&A extraction from tabular data.
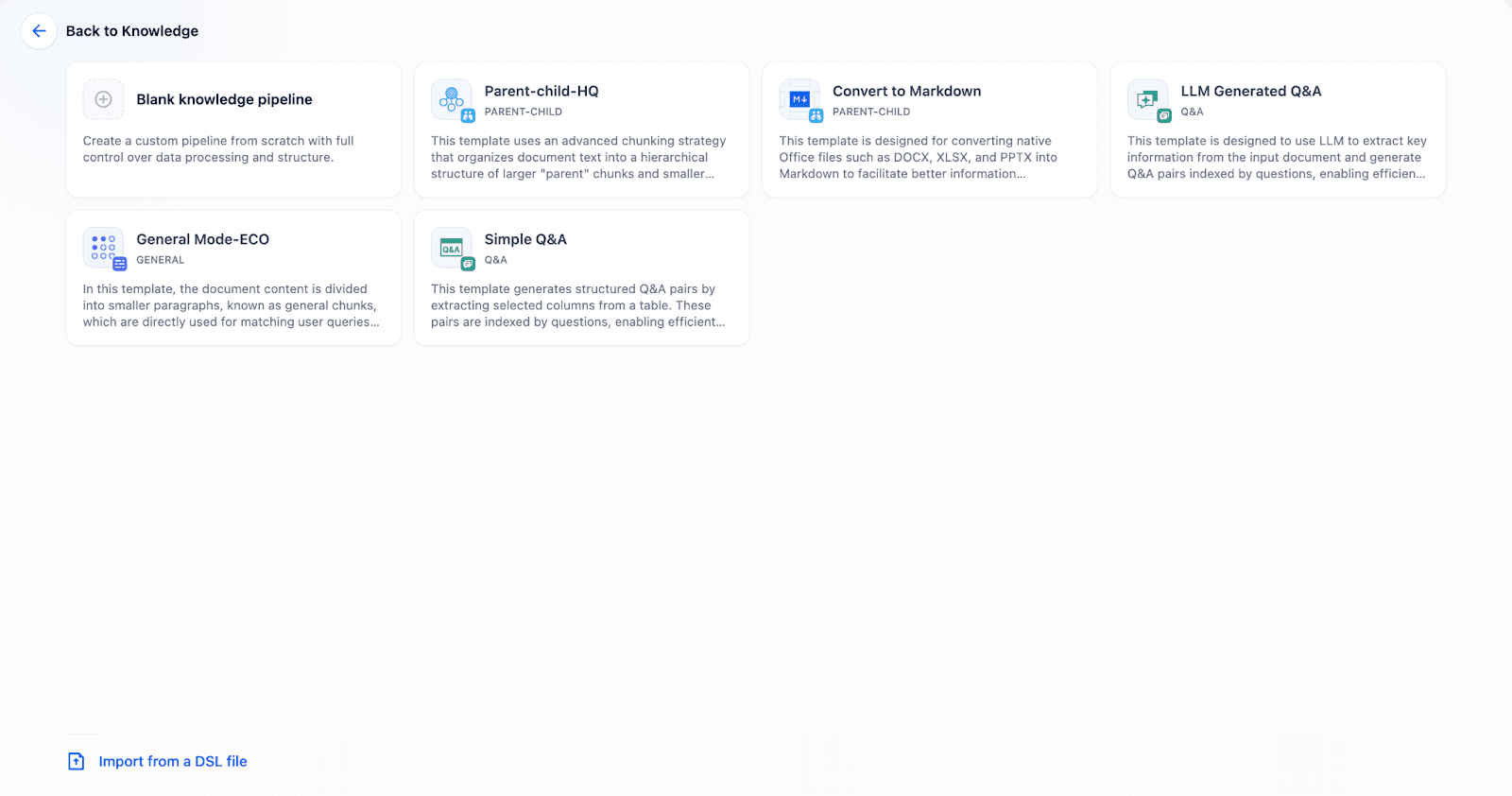
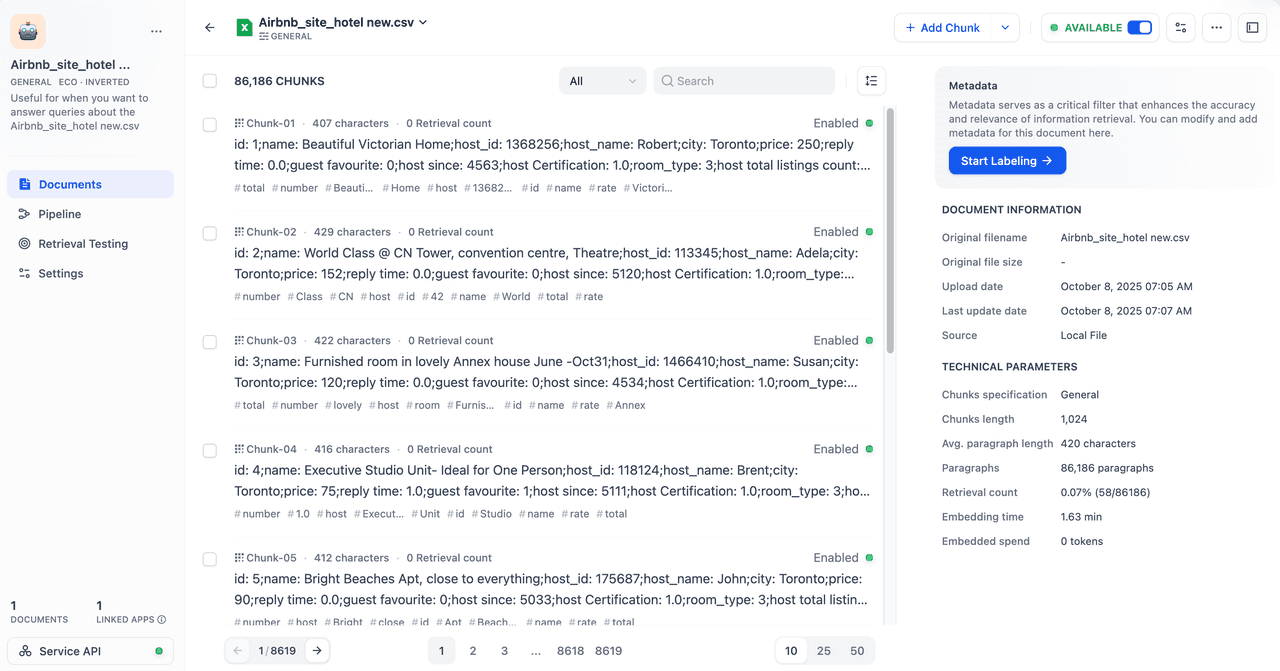
When you finish creating the knowledge base and uploading your data, the processed content, including text, metadata, and generated embeddings, is securely stored in TiDB.
Ⅳ. Build a RAG Application Workflow:
Once your knowledge base is ready, you can use it as context to build an agentic workflow. The data stored in TiDB Vector can then be retrieved through the Knowledge Node as contextual knowledge, helping LLMs reason with greater accuracy.
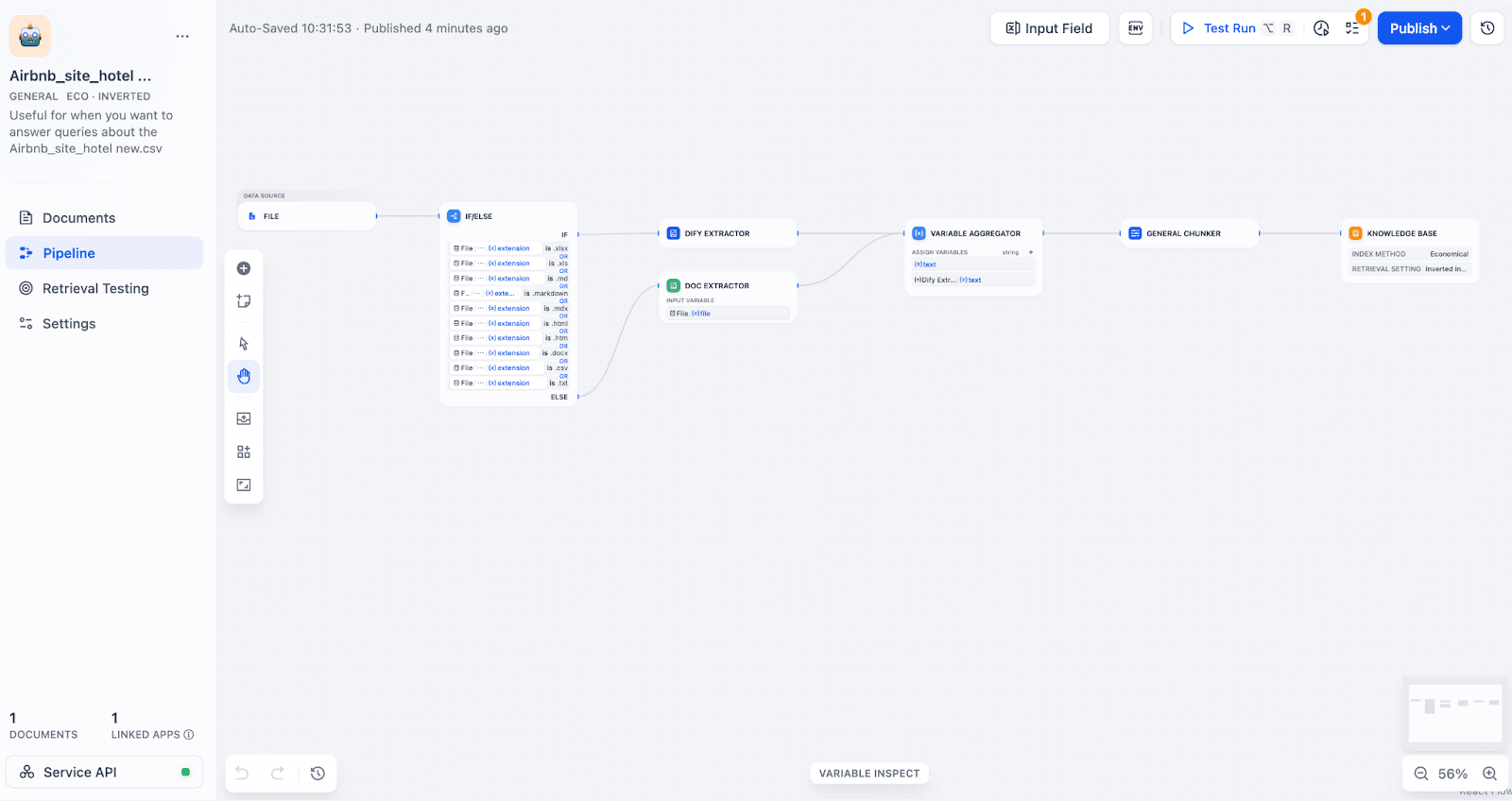
- The Knowledge Retrieval Node
Choose the knowledge base you previously created, which now uses TiDB Vector for vector storage, as the data source. When a user submits a query, this node automatically converts the question into a vector, runs a similarity search in TiDB, and retrieves the most relevant information.
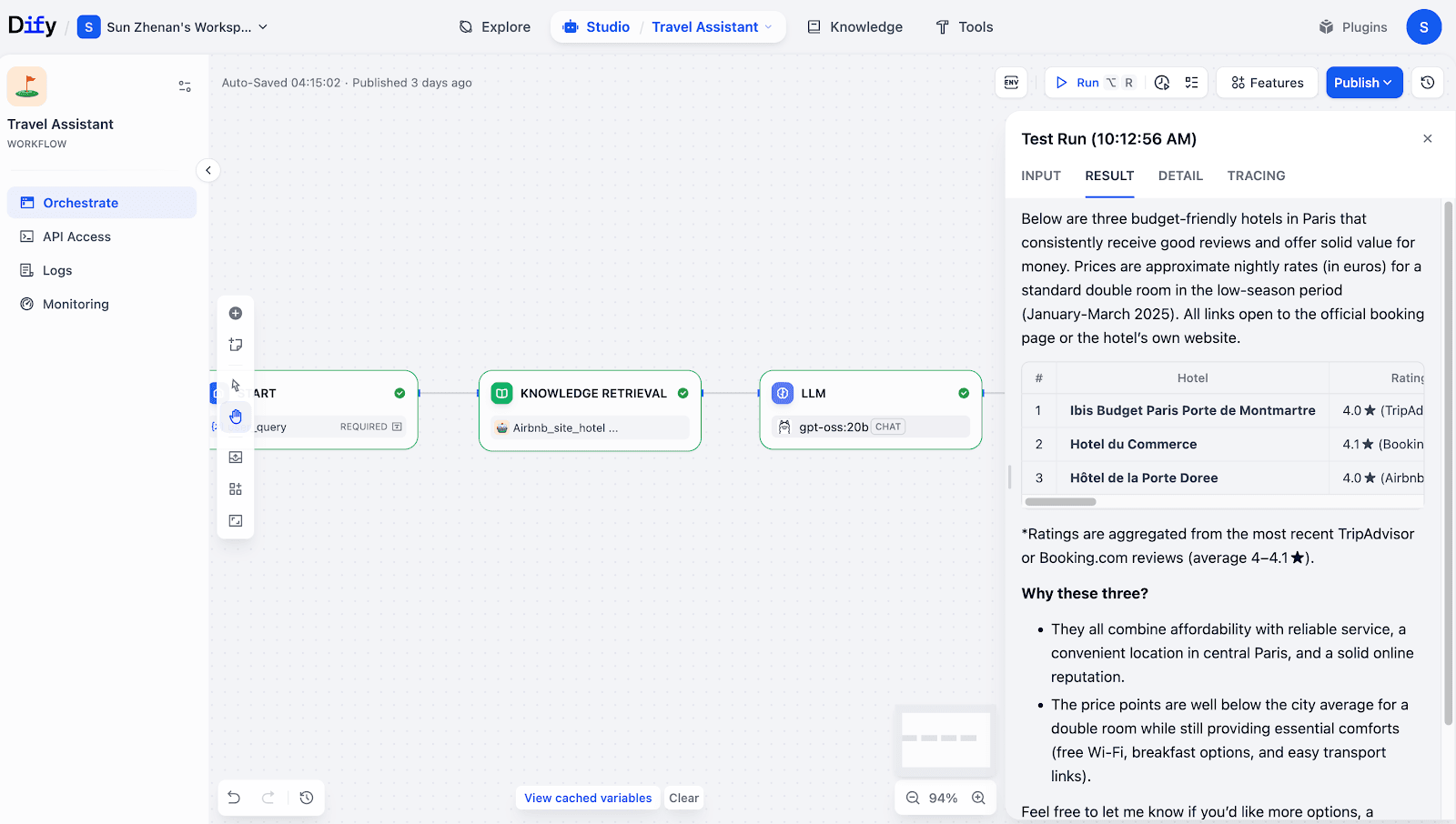
- The LLM Node
The information retrieved from TiDB is passed to the LLM node, enabling the model to generate responses that are more accurate, context-aware, and grounded in real-world data.
With Dify’s visual workflow builder and TiDB’s distributed vector storage, teams can efficiently design, deploy, and scale AI assistants, document Q&A systems, and knowledge bots.
This modular and end-to-end approach streamlines every step of RAG development, from data ingestion and retrieval to generation, within a single unified workflow.
About TiDB
TiDB is an open-source, distributed SQL database designed to drive enterprise digital transformation. Its distributed architecture offers a scalable data infrastructure that supports a variety of business workloads. Traditionally, organizations needed multiple technology stacks to address different data processing needs, but TiDB consolidates these capabilities into a unified real-time HTAP platform, supporting both transactional and analytical tasks.
About Dify
Dify is an open-source platform for developing LLM applications. Its intuitive interface combines agentic AI workflows, RAG pipelines, agent capabilities, model management, observability features, and more—allowing you to quickly move from prototype to production.
Related articles
- Product
Now on Dify Marketplace: Qubrid AI Brings Multi-Model Access to Every Dify Workflow
Install the Qubrid AI plugin on Dify to unlock unified access to DeepSeek, Kimi, Qwen, MiniMax, GLM, and more, all through one API key.

 Qubrid AI & Dify
Qubrid AI & Dify - Product
Grounding Dify Agents in Real Data: MongoDB Atlas and Voyage AI Are Now Native to Dify RAG Workflows
Dify and MongoDB make it easier to build grounded AI agents that retrieve, reason over, and act on real business data, without stitching together custom RAG infrastructure from scratch.
 MongoDB & Dify
MongoDB & Dify - Product
Dify Creator Center & Template Marketplace: Share Your Workflows
Dify’s new Creator Center and Template Marketplace let creators publish workflow templates and users discover and one-click adopt them, with optional PartnerStack affiliate linking to earn recurring commissions from subscriptions driven by template links.
Dify - Product
Try OpenAI, Claude, Gemini & Grok Free on Dify Cloud
Supports OpenAI, Claude, Gemini, and Grok. Try curated templates with zero configuration.
Dify