











Hi, I’m Evan from the Dify product team. Today, I’ll explain how GPT-Researcher works and how to use advanced iterative features to enhance your workflow.
Introduction
GPT-Researcher is a popular research agent that automates tedious tasks by crawling, filtering, and aggregating information from over 20 web resources per assignment.
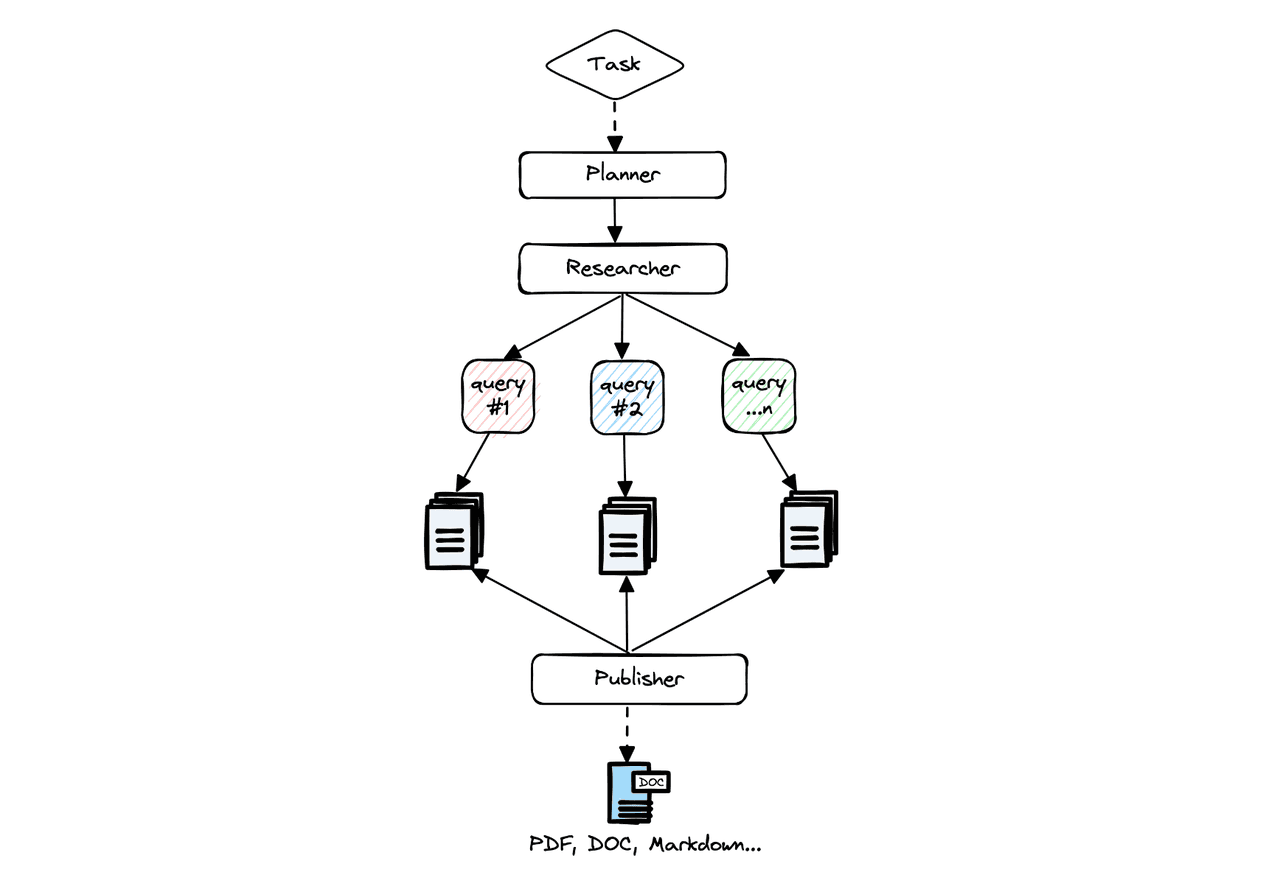
Manual research could take weeks to find the right resources and reach objective conclusions. GPT-Researcher improves speed and reliability by using parallel agents instead of synchronous operations. It runs “planner” and “execution” agents: the planner generates research questions, execution agents find relevant information, and the planner filters and aggregates the data into a report.
Using Dify Workflow, we can orchestrate a similar research framework, accelerating tasks with “parallel mode.”
Live Demo
How It Works
Because generating research tasks isn’t conversational, we’ll use the Workflow application type.
Step 1: Define the Start Form Fields
- Title: Specify the research topic.
- Language: Choose the language for the research report.
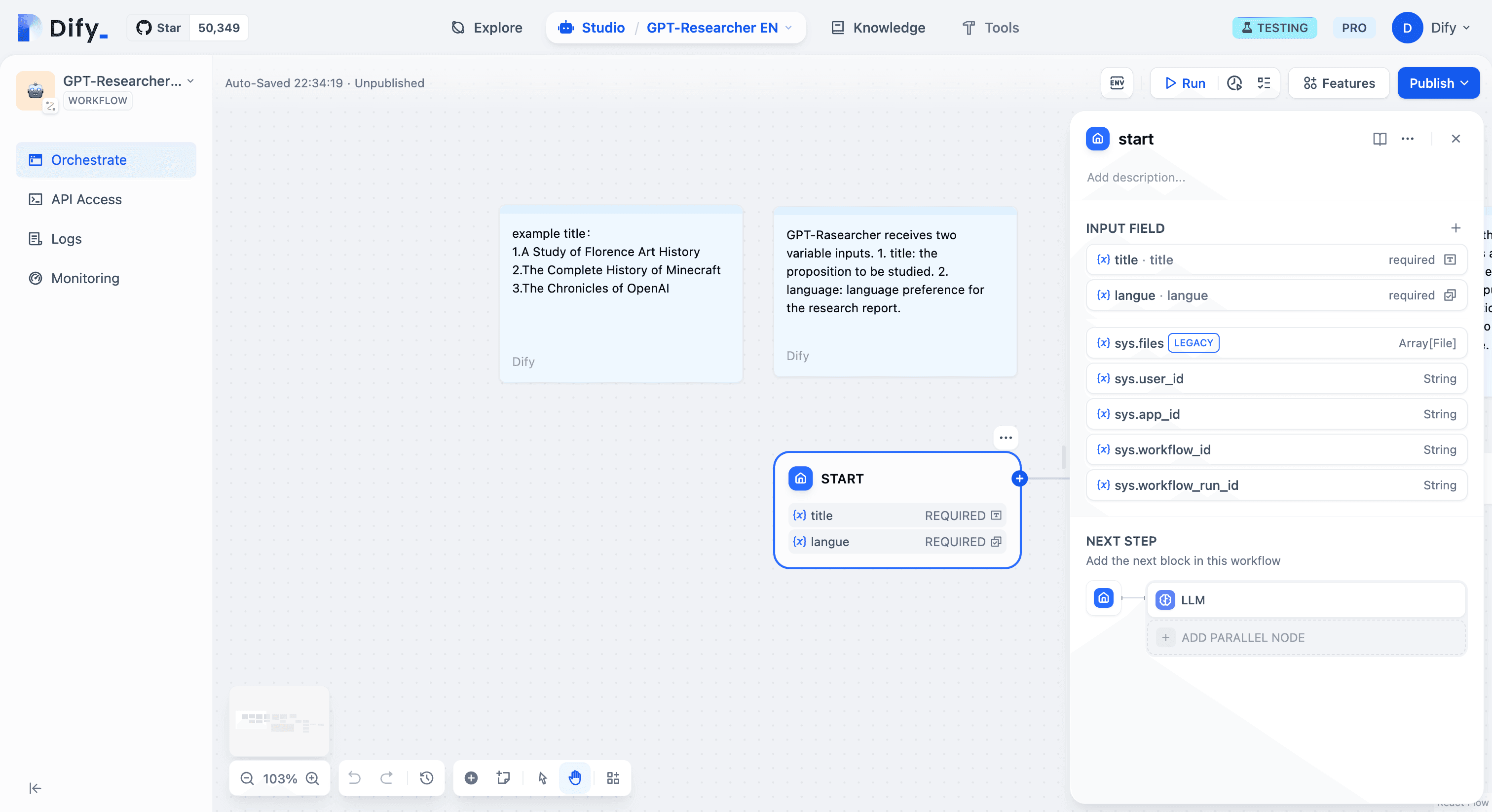
Step 2: Use LLM to Generate Sub-Queries for Problem Decomposition
We need the sub-queries to meet the specific conditions below to control the LLM’s output format, aiding in later processing with a code node. If writing prompts is challenging, you can use the system reasoning model to generate them.
- Generate appropriate search engine queries to break down the user’s problem.
- Ensure the output contains no XML tags.
- Output must be clean, following the <example> style, with no additional explanations.
- Break down into at least 4-6 sub-questions.
- Output separated only by commas.
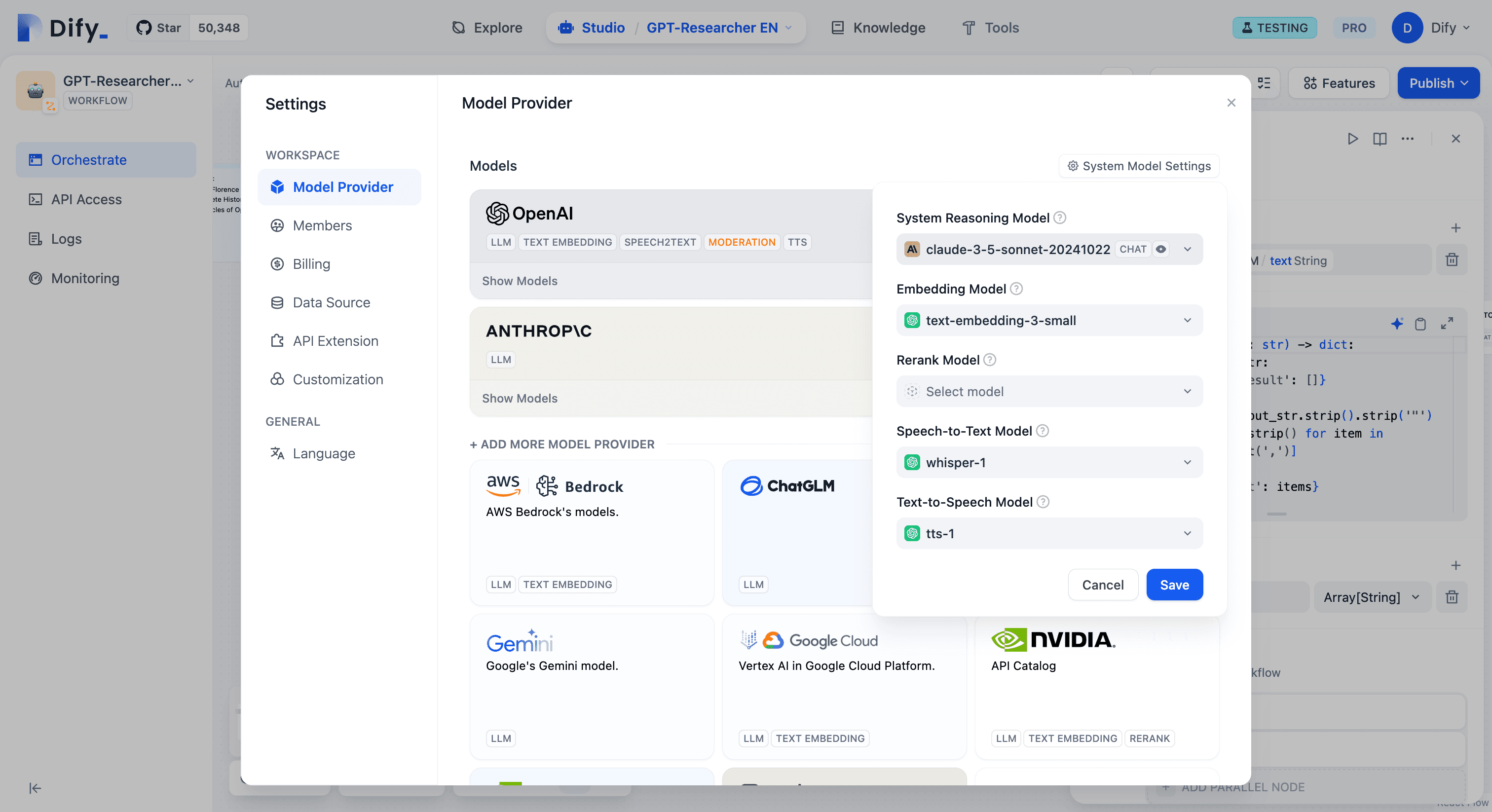
You can configure the system reasoning model in Settings -> Model Providers.
Step 3: Use a Code Node to Split the Input String
Since GPT-Researcher’s main idea is to run “planner” and “execution” agents, the planner breaks down the problem into manageable, independent sub-questions. This allows subsequent sub-question research to proceed concurrently.
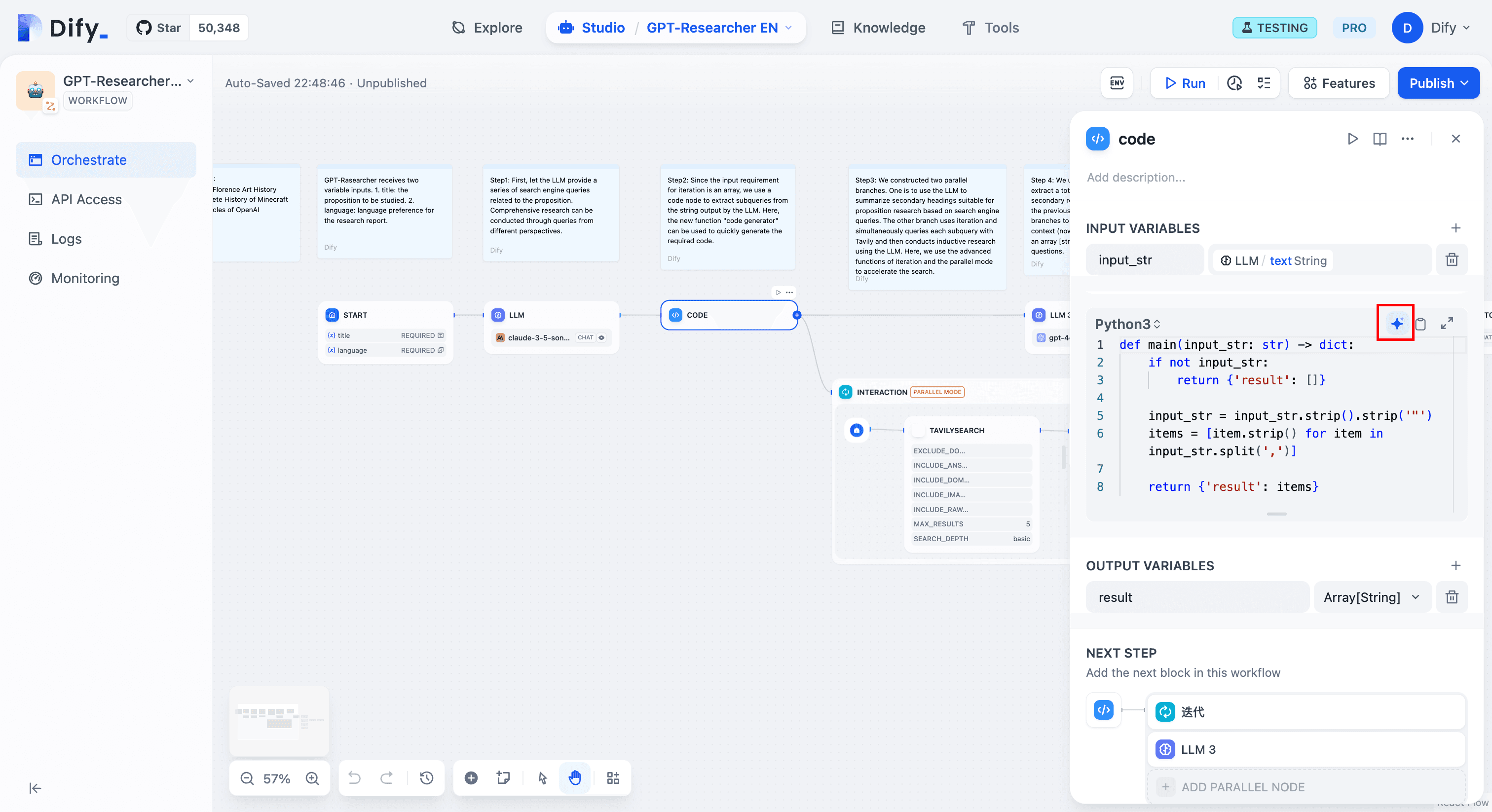
Step 4: Use Advanced Iterative Features to Accelerate the “Execution” Agent
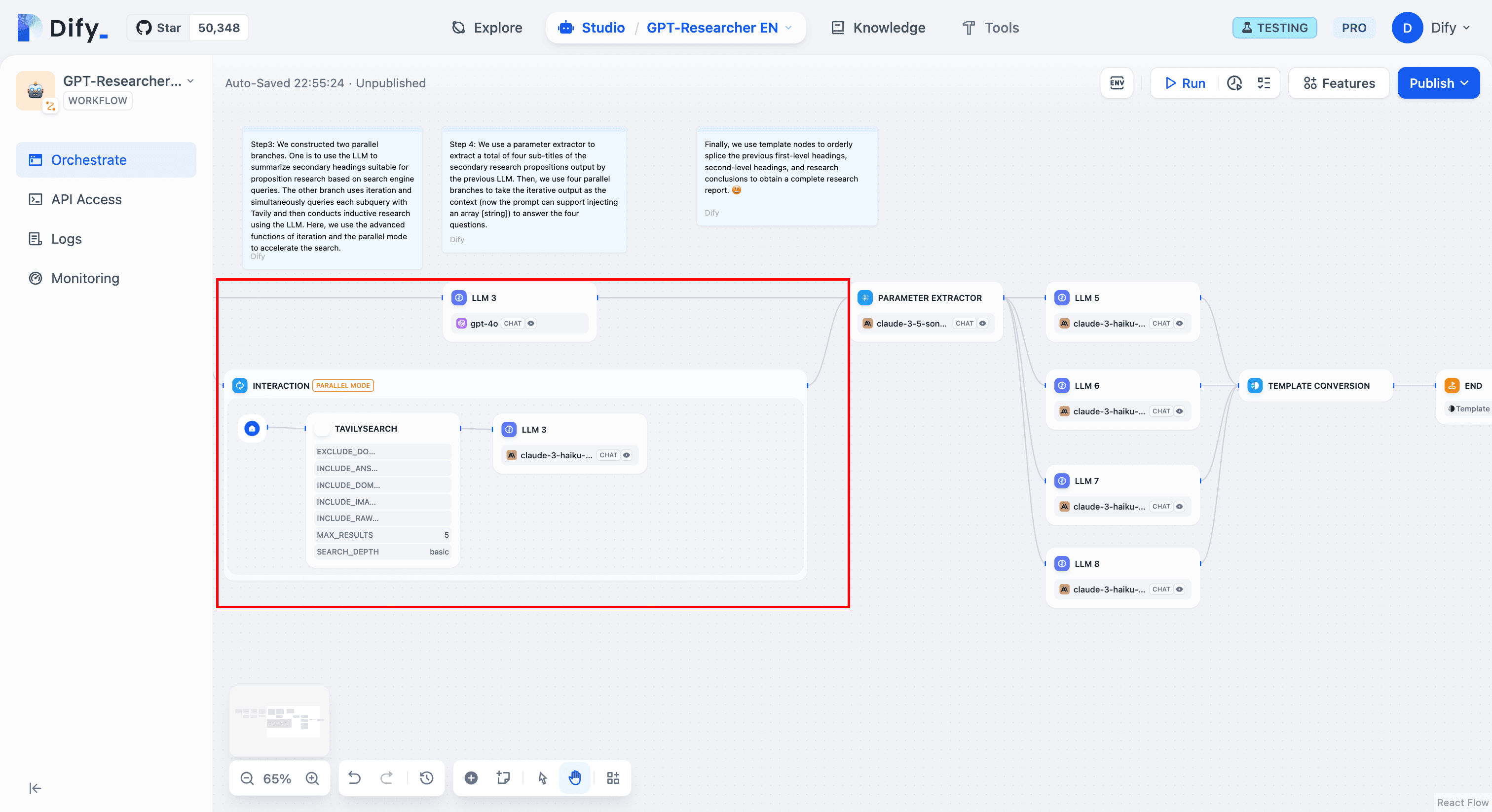
This step is crucial. While sub-queries work for search engines, they aren’t ideal as subheadings. We use the LLM to extract common themes to create secondary titles for the research. In the iterative block below, we use the Tavily API for search engine queries. Configure the number of links returned, then use the LLM to summarize and analyze the results as context.
In the iteration panel, Parallel Mode and Error Response Method are advanced features. In parallel mode, iteration tasks execute concurrently, reducing runtime (total sequential time divided by maximum parallelism). However, since tasks are unordered, using tools that require order may lead to unexpected results.
Developers can control the API request rate within the iteration block by adjusting the maximum degree of parallelism to prevent hitting limits.
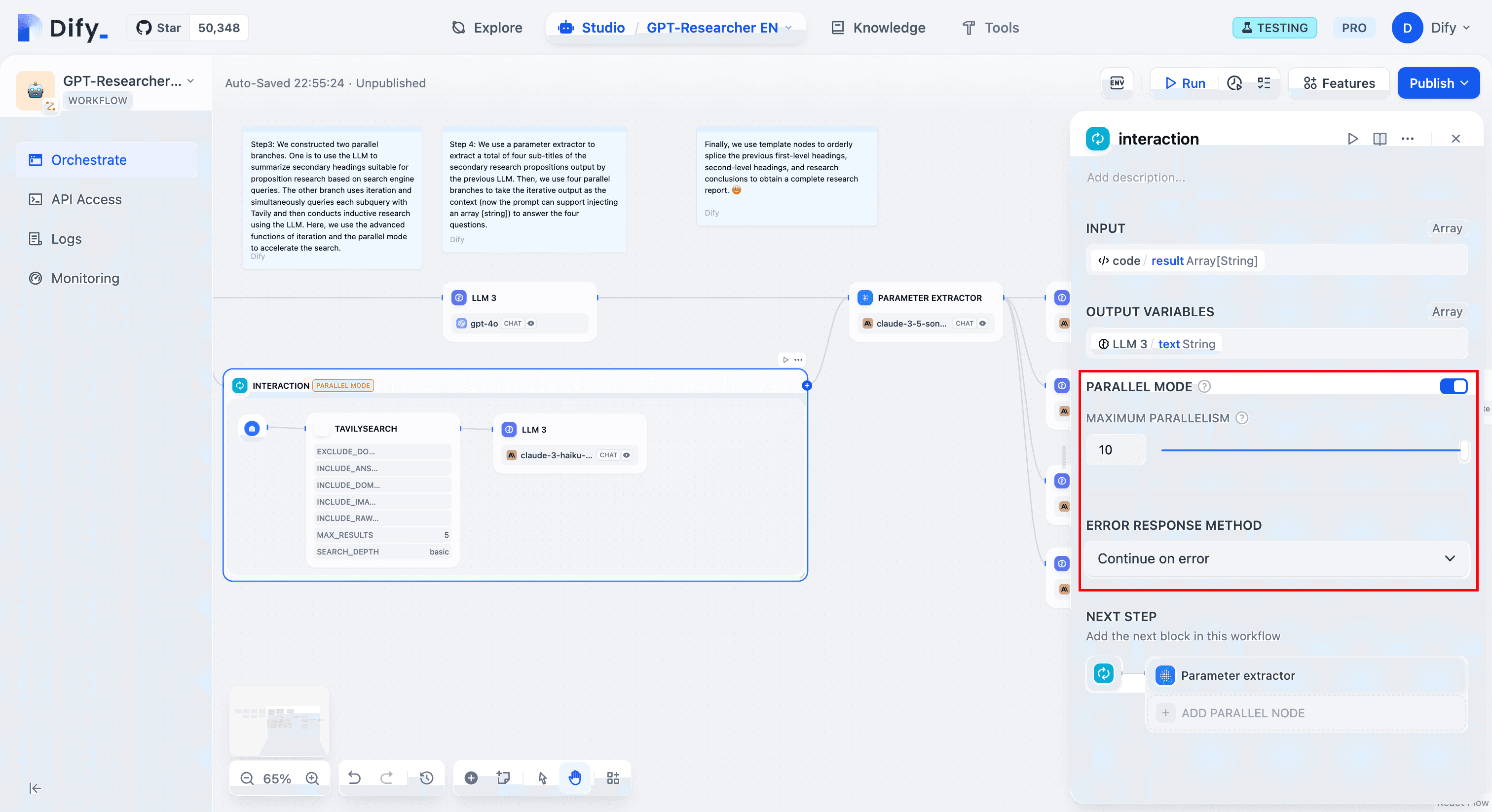
Regarding the Error Response Method:
An exception in one iteration item shouldn’t affect others. We need to isolate exceptions at the iteration item level to decide how to handle them. This allows the iteration to complete regardless of sub-task failures. Refer to the Iteration Node for more details.
Step 5: Extract Sub-Questions
We use the parameter extractor to merge the multiple sub-queries into a predefined number of subheadings. This way, we can pre-orchestrate four parallel branches to receive these parameters separately, and each LLM receives the iteration output as context for answering the sub-questions.
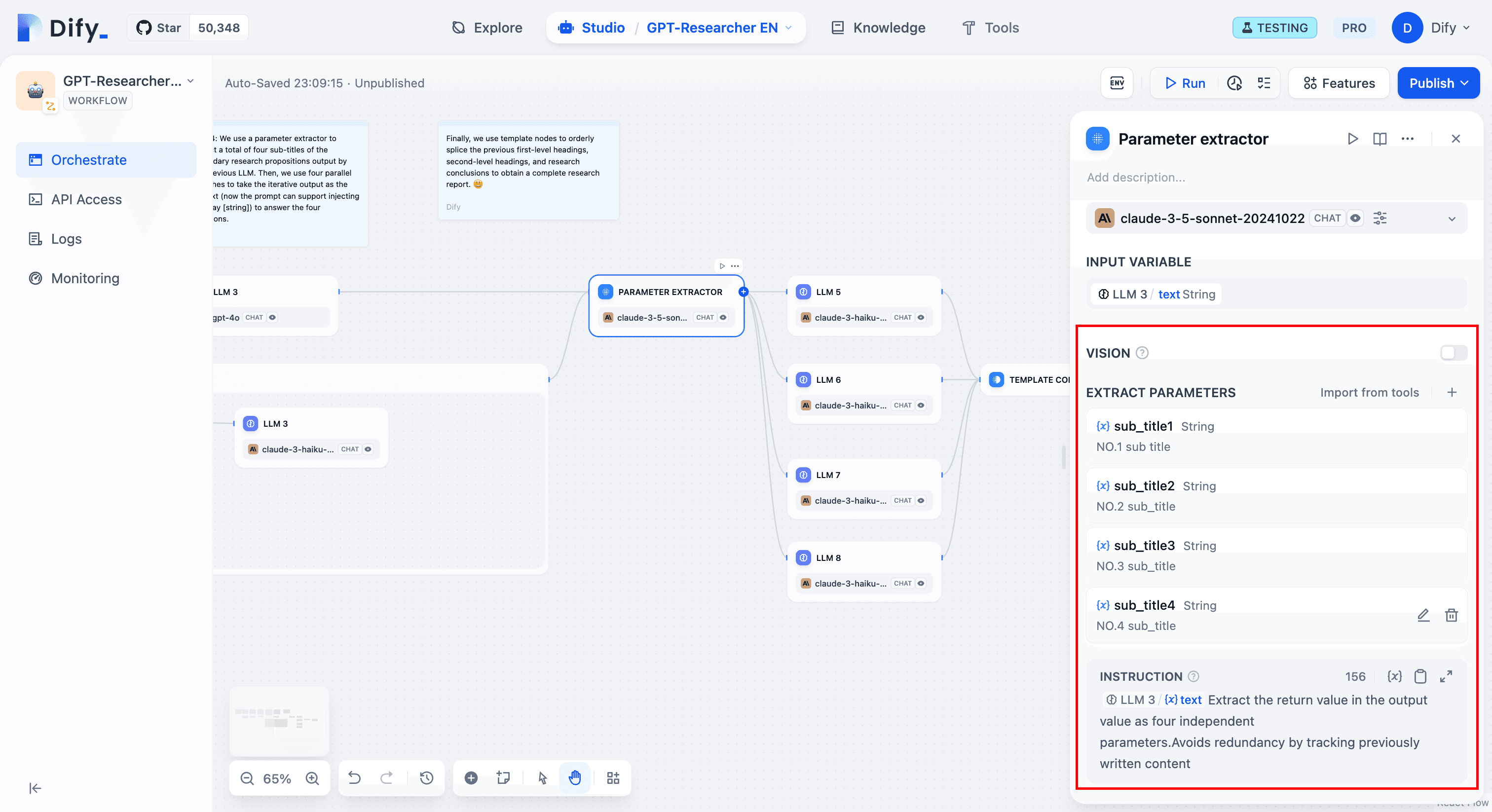
Then we use a template node to produce a formatted research report.
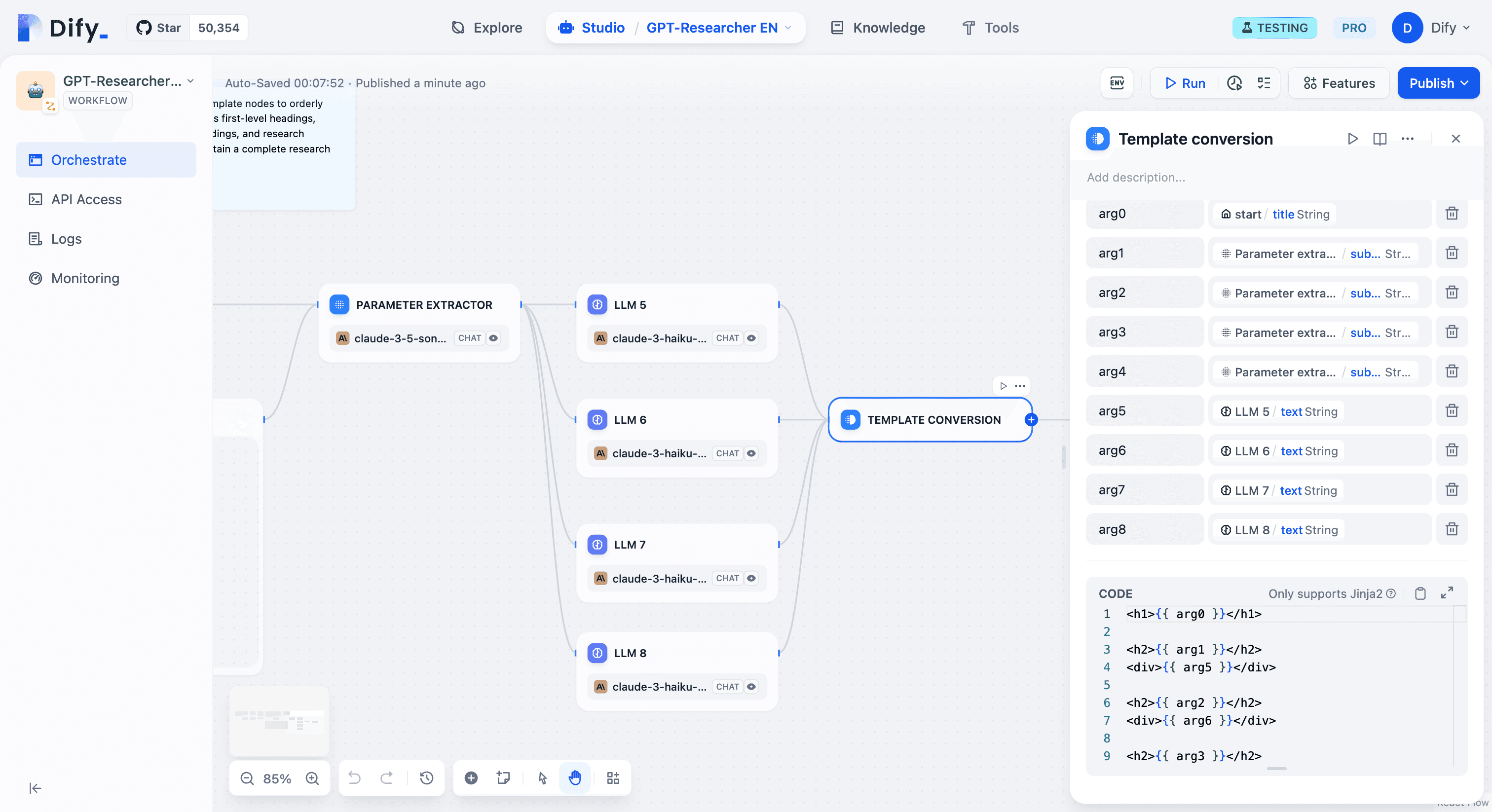
Research Report Output
Summary
Here’s how the Dify workflow orchestrates a research framework similar to GPT-Researcher:
- Creates an initial form to capture the research topic and output language preferences.
- Generates sub-queries by instructing the LLM to break down the main question into 4-6 independent, searchable components.
- For each sub-query, leverages parallel processing to simultaneously:
- Extract common themes to form research subheadings.
- Trigger the Tavily API to gather relevant search results.
- Analyze and summarize the search results using the LLM.
- Aggregates the parallel research streams into a structured final report with consistent formatting.
Key Features and Technical Considerations
- Parallel Processing Benefits
- Significantly reduces research time (total sequential time divided by maximum parallelism).
- Enables concurrent handling of multiple aspects.
- Allows flexible control over API request rates through parallelism settings.
- Error Handling
- Isolates iteration items to prevent cascading failures.
- Allows completion of parallel tasks regardless of individual sub-task failures.
- Maintains stability of the overall research process.
That concludes our presentation. For detailed explanations about advanced iterative features, check our documentation. This demo is also available on our Explore page. Give it a try!
Reference: How we built GPT Researcher
Related articles
- How to
How to Let Your Agent Call Dify Workflows Directly
Learn how to quickly invoke existing Dify apps, turning complex business workflows into a single prompt and one human approval.
 Dify
Dify - How to
How to Add an AI Support Assistant to Your Website with Dify
Step-by-step tutorial on how to build, test, and embed an AI chatbot right into your website.
Dify - How to
How Marketer Builds Reliable AI Workflows
Every marketer can write a prompt. Few have figured out how to scale them. Inside: three workflows marketing teams actually build. Got a repetitive task you wish was a template? You name it. We build it for free.
Dify - How to
Get Started with Dify
In this guide, you'll learn the core fundamentals, find the right starting point for your first AI application, and grab useful resources to hit the ground running.
Dify