










Dify Conversation Variables: Building a Simplified OpenAI Memory
Conversation Variables are short-term memory units employed by Dify to provide temporary storage in multi-turn conversations within chatflows. These variables enable us to retain important details between chat interactions, resulting in more contextually relevant responses. In the following section, I will demonstrate how to utilize Conversation Variables to emulate OpenAI's Memory Features.

Hi there! I'm Evan from the product team at Dify, and I'm thrilled to introduce you to our game-changing feature: Conversation Variables.
Imagine giving your AI a smart, temporary notepad that remembers crucial details throughout a chat. That's exactly what our Conversation Variables do! These powerful short-term memory units are revolutionizing multi-turn conversations in chatflows, making AI interactions more natural and context-aware than ever before.
Why are they important?
- Enhanced Relevance: By storing and recalling key information, your AI can provide more contextually appropriate responses.
- Streamlined Development: Effortlessly manage complex conversation states and optimize multi-step AI workflows by reading and writing variables at any point, eliminating the need for intricate coding.
- Fine-grained Memory Control: Unlike broad conversation history, these variables allow precise management of specific information bits, enhancing AI response accuracy.
Simulating OpenAI Memory Features
In this guide, we'll explore how to leverage Dify's Conversation Variables to simulate OpenAI's advanced memory features. You'll learn to:
- Implement persistent memory in your chatbots
- Create more intelligent, context-aware AI assistants
- Elevate your conversational AI to new heights of sophistication
Ready to supercharge your chatflows? Let's dive in!
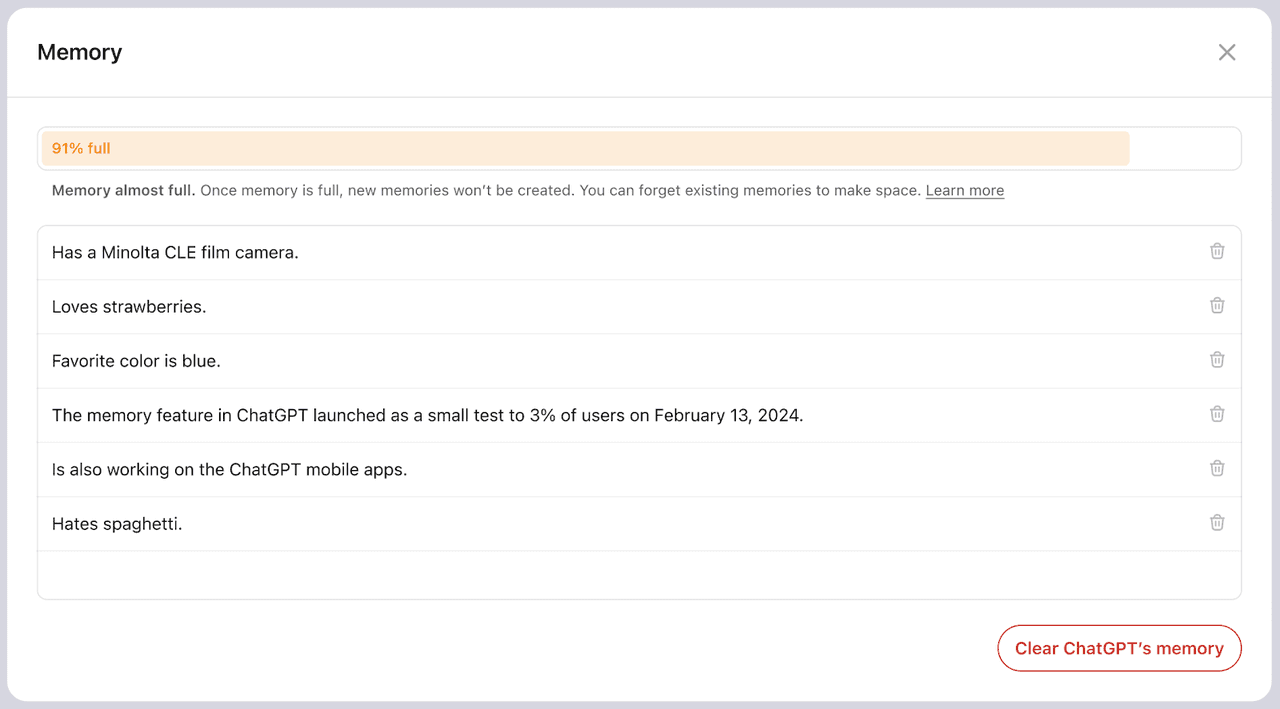
Memory works is an automated storage process that focuses on the user's queries, collecting facts and preferences from them. Ultimately, these are added to the conversation context in a way that they become part of the conversation record when generating a response.
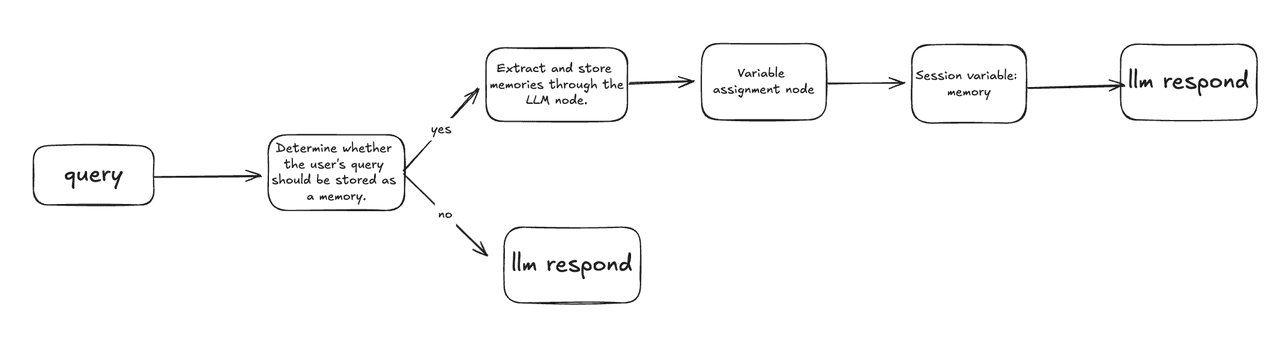
Throughout the entire process, three types of LLM nodes were used for:
- Determine whether to store as a memory node: Assessing whether the current query contains inferred facts, preferences, and user memories.
- Extract memory node: Extracting memory objects from the user's query.
- Respond node: Generating responses based on relevant memories.
The structure and definition of memory objects, including relevant prompts, come from here.
A Step-by-Step Guide
Prerequisites
- Register or deploy Dify.AI
- Apply for the API key from model providers like OpenAI
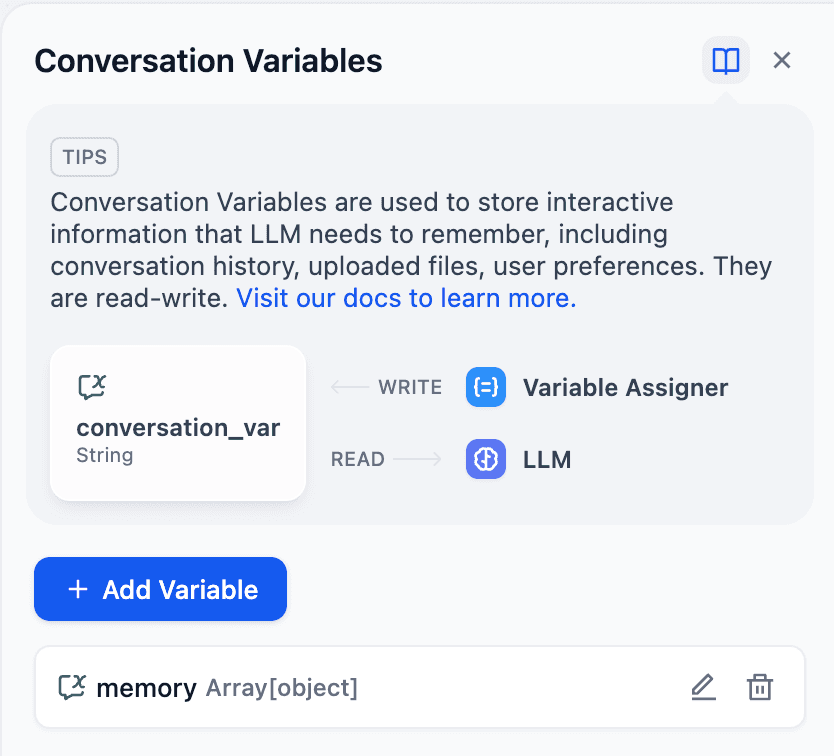
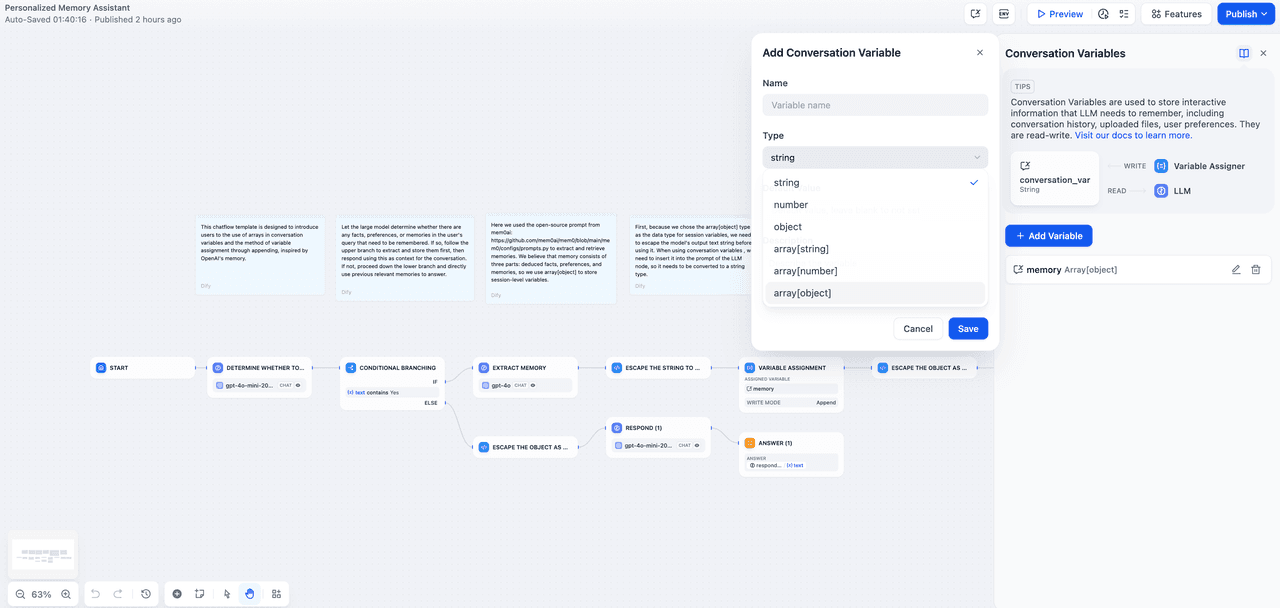
Create conversation variable
Click the button in the upper right corner to enter the management page for session variables. Here, you can add, delete, and maintain your session variables. In this example, we create a session variable of type Array[object] (because an Array[object] variable can continuously append new memories, which consist of three attributes). You can set default values for session variables to respond more flexibly to certain scenarios.
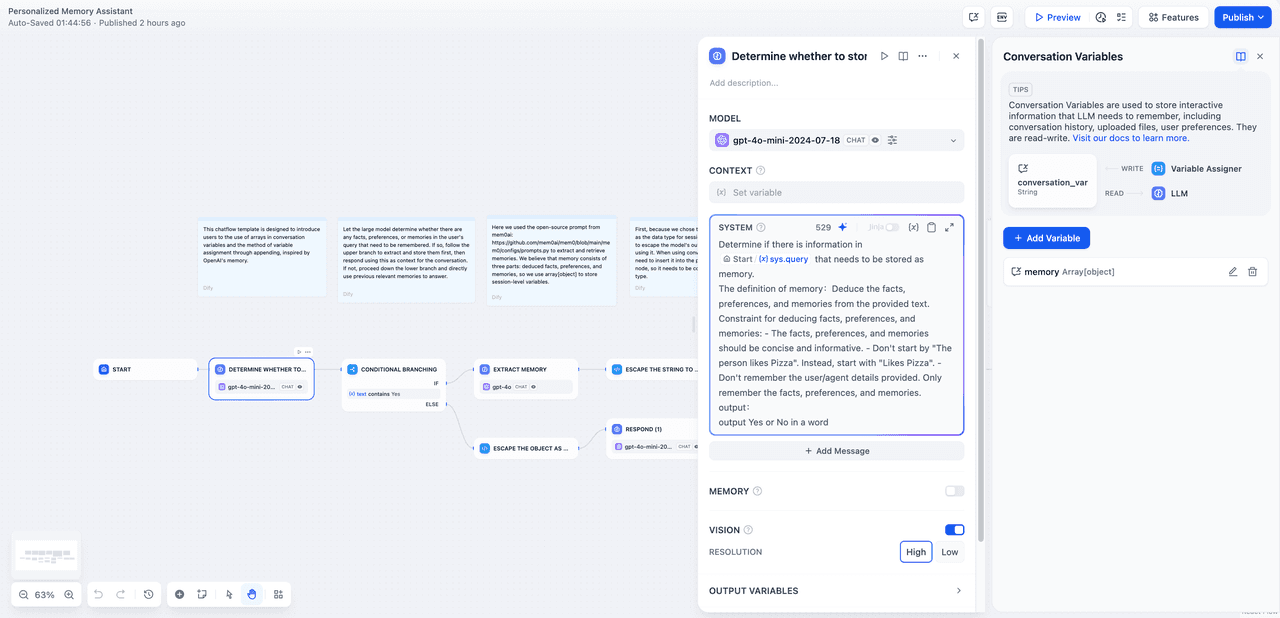
The definition of memory: deduce the facts, preferences, and memories from the provided text. Constraint for deducing facts, preferences, and memories:
- The facts, preferences, and memories should be concise and informative.
- Don't start by "The person likes Pizza". Instead, start with "Likes Pizza".
- Don't remember the user/agent details provided. Only remember the facts, preferences, and memories.
Determine whether to store as a memory node
We determine whether there are parts that meet the memory definition from sys.query and require the output to be yes or no for downstream if-else nodes to make conditional judgments. If a multimodal model is used, you can enable vision, allowing you to upload session backgrounds that need to be remembered from notebooks or other images.
Extract memory node
Constraint for deducing facts, preferences, and memories:
- The facts, preferences, and memories should be concise and informative.
- Don't start by "The person likes Pizza". Instead, start with "Likes Pizza".
- Don't remember the user/agent details provided. Only remember the facts, preferences, and memories.
This node needs to use a command-following/inference-capable model like Claude 3.5 sonnets or GPT-4o.
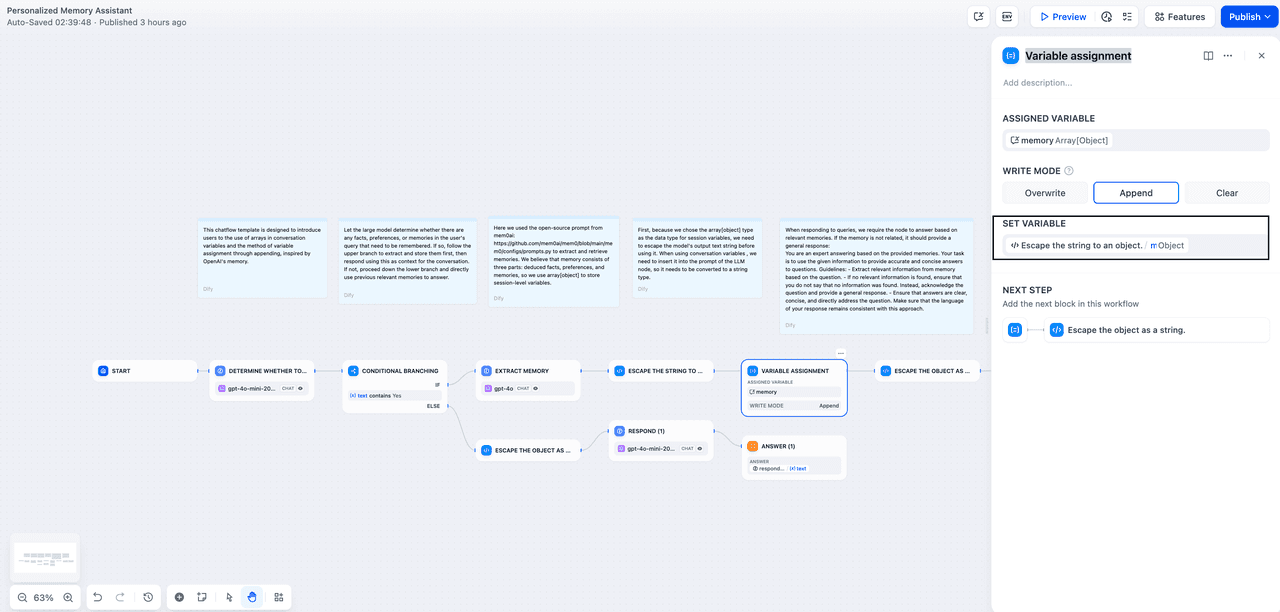
Variable assignment
Here we choose the append mode, which allows us to continuously update memories in multi-turn conversations. The set variable here is object type, so we need an escape node to convert the output of the large model into the correct type.
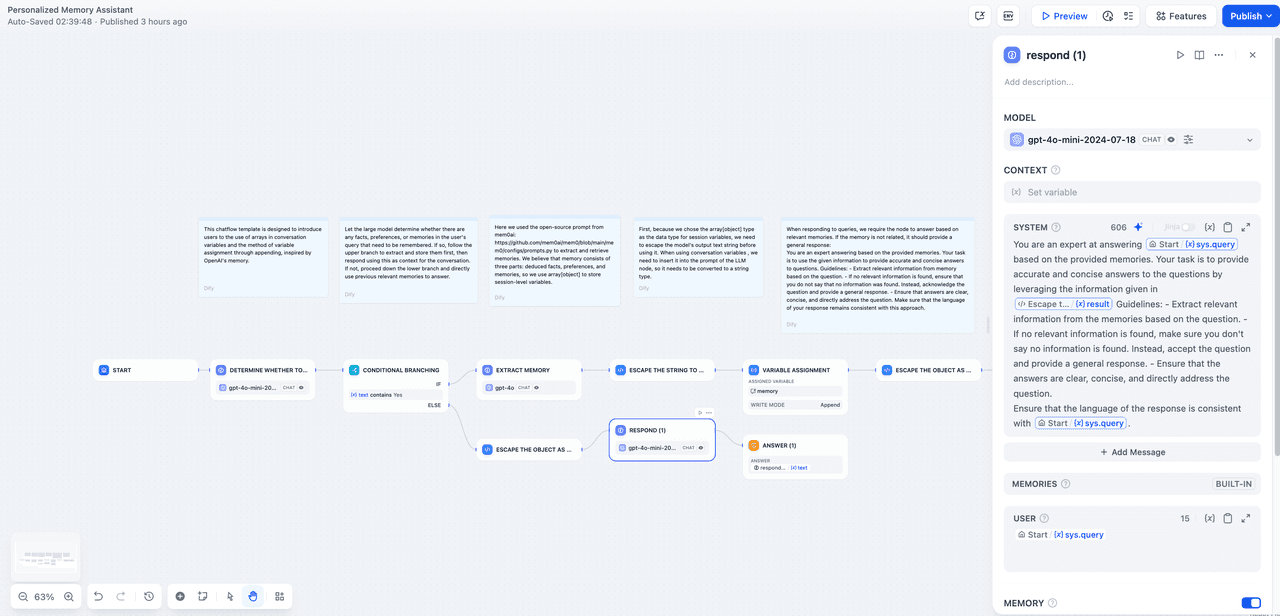
Respond node
Here, we allow the model to respond to the user's sys.query based on the provided memory. If there are no relevant parts in the memory, a generalized answer will be given using the default language of the user's query.
Escape code implementation
Why do we need to escape nodes:
- String to object node: This node is used to convert the output string of a large model into an object type format, so that it can be directly used in variable assignments. However, if the session variable itself is already a string type, then the output of the large model can be referenced directly.
- Object to String Node: In the prompt orchestration of Dify, variables are uniformly treated as string types. Therefore, the Array[object] stored in session variables cannot be directly referenced in the prompt, so we need a node like this for format conversion.
The code for the node in the upper diagram is as follows:
- Escape the string to object
%%BLOCK:0%% - Escape object as string
%%BLOCK:1%%
More scenarios and limitations of this instance
This assistant has more scenarios as follows: If you're interested, you can give it a try. We have already launched this template on the explore page.
- Analyzing past food delivery orders photos to inform future meal suggestions and avoid recent repetitions.
- Utilizing past travel records to collaboratively plan future trips with users over multiple conversation turns.
- Using Conversation Variables to maintain consistency in characters, plot, and themes during long-form writing projects.
- Adapting educational content and recommendations based on a learner's progress and preferences.
Of course, here we hope to achieve the simplest nano personalized memory assistant by extracting and storing memories through passive judgment with as few nodes as possible. To create a more powerful memory assistant, we need more branches to maintain the logic of memory updates and references. Due to the idleness of the context window and the limitations of multi-head attention, when there is too much memory on different topics, using all of it for context construction may not be a good choice. At this point, RAG should be used to match the memories most relevant to the current query in order to build context.
In short, I hope this case can help you better understand our conversation-level variables and the updates to the variable assignment nodes. I look forward to seeing more use cases from the community!
Related articles
- How to
How to Add an AI Support Assistant to Your Website with Dify
Step-by-step tutorial on how to build, test, and embed an AI chatbot right into your website.
 Dify
Dify - How to
How Marketer Builds Reliable AI Workflows
Every marketer can write a prompt. Few have figured out how to scale them. Inside: three workflows marketing teams actually build. Got a repetitive task you wish was a template? You name it. We build it for free.
Dify - How to
Get Started with Dify
In this guide, you'll learn the core fundamentals, find the right starting point for your first AI application, and grab useful resources to hit the ground running.
Dify - How to
Designing Intent-Based Email Routing with Dify Workflow
Dify uses workflow-based intent routing to automatically classify and assign support emails while keeping decisions controlled and auditable. This approach improves routing consistency and helps support teams scale operations without losing stability.
 Bobby Zhang
Bobby Zhang