











When deployed, generative AI applications face challenges like hallucinated responses, non-compliance, and excessive token consumption due to the unpredictability of LLMs.
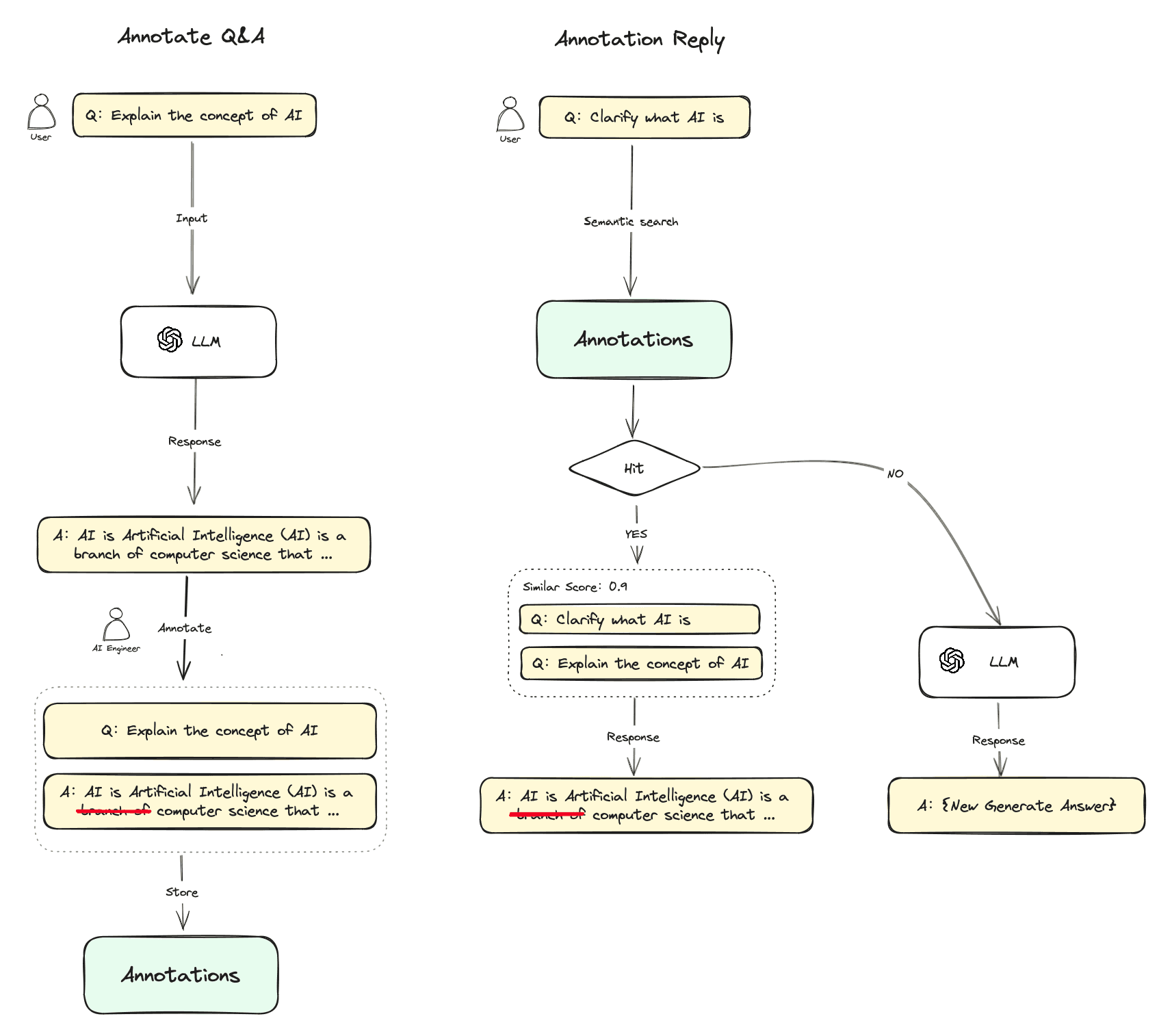
Dify.AI's Annotation Reply feature allows manually editing historical conversations or importing Q&A batches so that similar user questions will be matched and replied with annotated responses first. This customizability enables chatbots to give definite answers in specific question scenarios.
Let's see what it can do for you.
Enhance Reply Quality, Build LLMOps Data Feedback Loop
We believe that every AI application can only achieve 60% expected performance initially. The remaining 40% requires continuous refinement of prompts and replies to meet targets. That's why Dify aims to be an excellent LLMOps platform for developers to iterate on LLM application performance after creation.
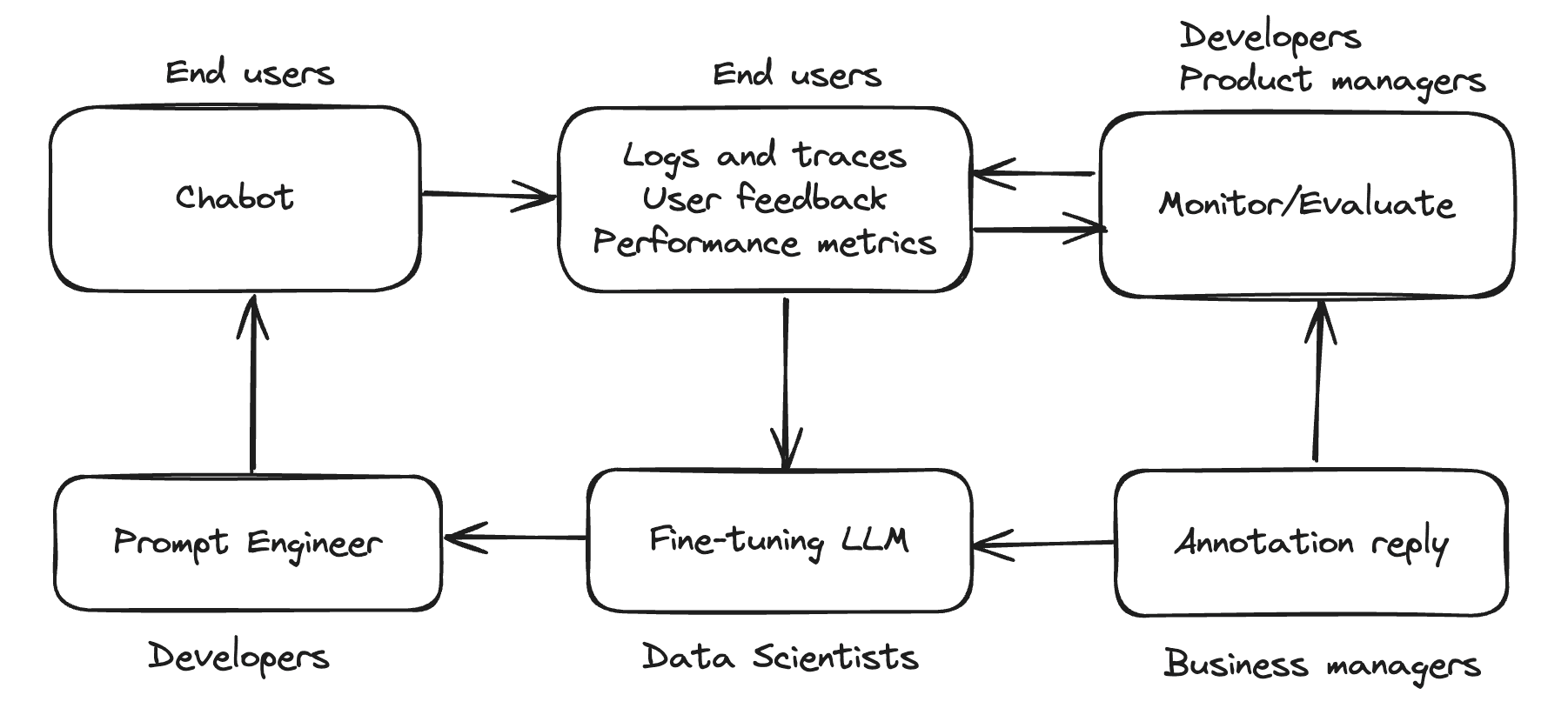
A production-grade LLM application requires a complete loop of application development, monitoring, feedback, and optimization. This allows developers to repeatedly enhance LLM performance, create a data flywheel effect, and steadily improve generation quality and reliability. Annotation Reply feature play a critical role here.
In Dify, you can annotate AI replies during application debugging, so that when demonstrating to important customers, you can pre-annotate answers to specific questions to align LLM output with expectations.
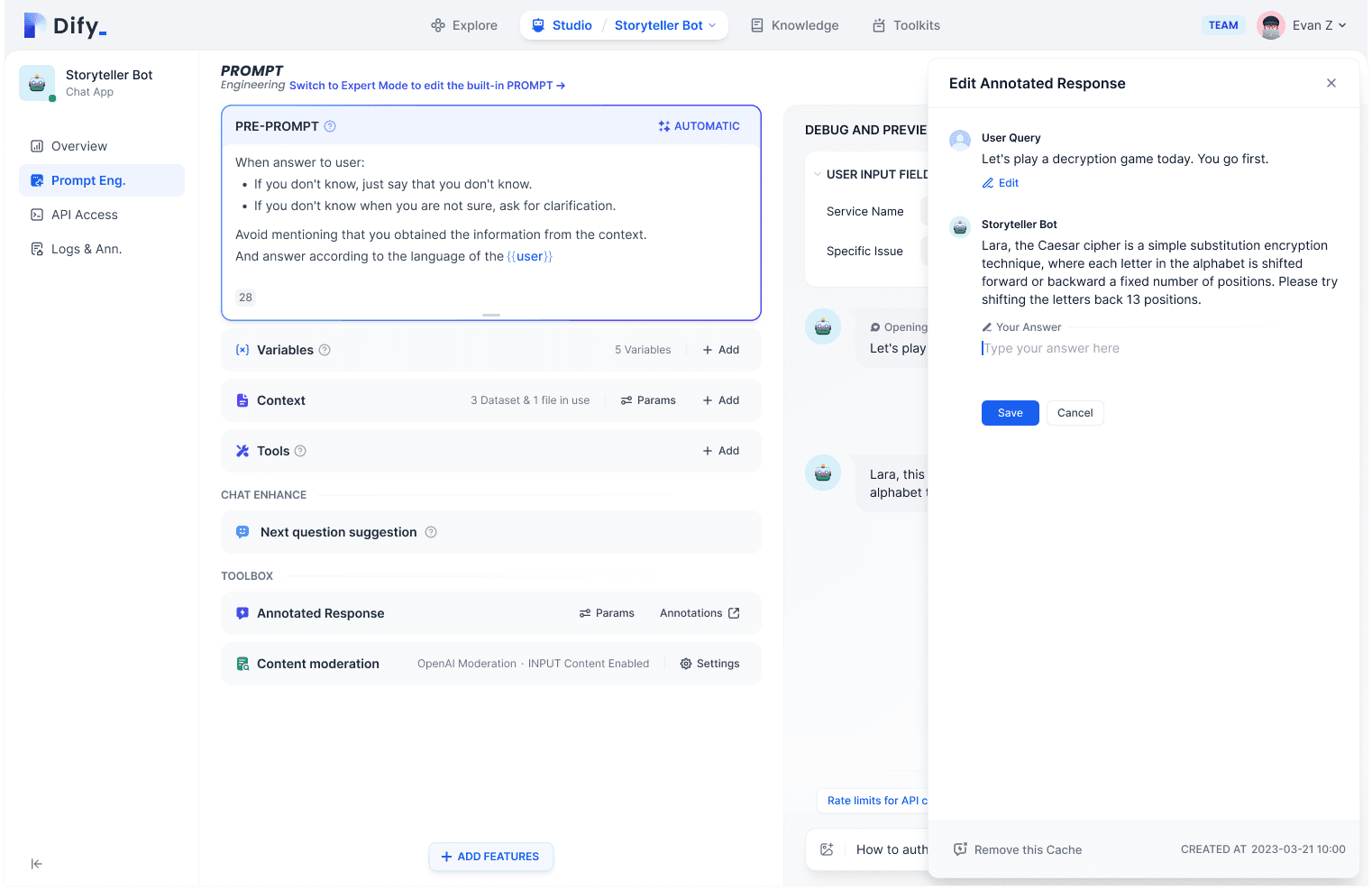
During application operation, Dify also facilitates collaboration between developers and business managers without hard coding changes. Business manager are the best one who understand customer needs and know the optimal answers! After developers build the application, business teams can take over data improvement by editing replies or importing existing Q&A data.
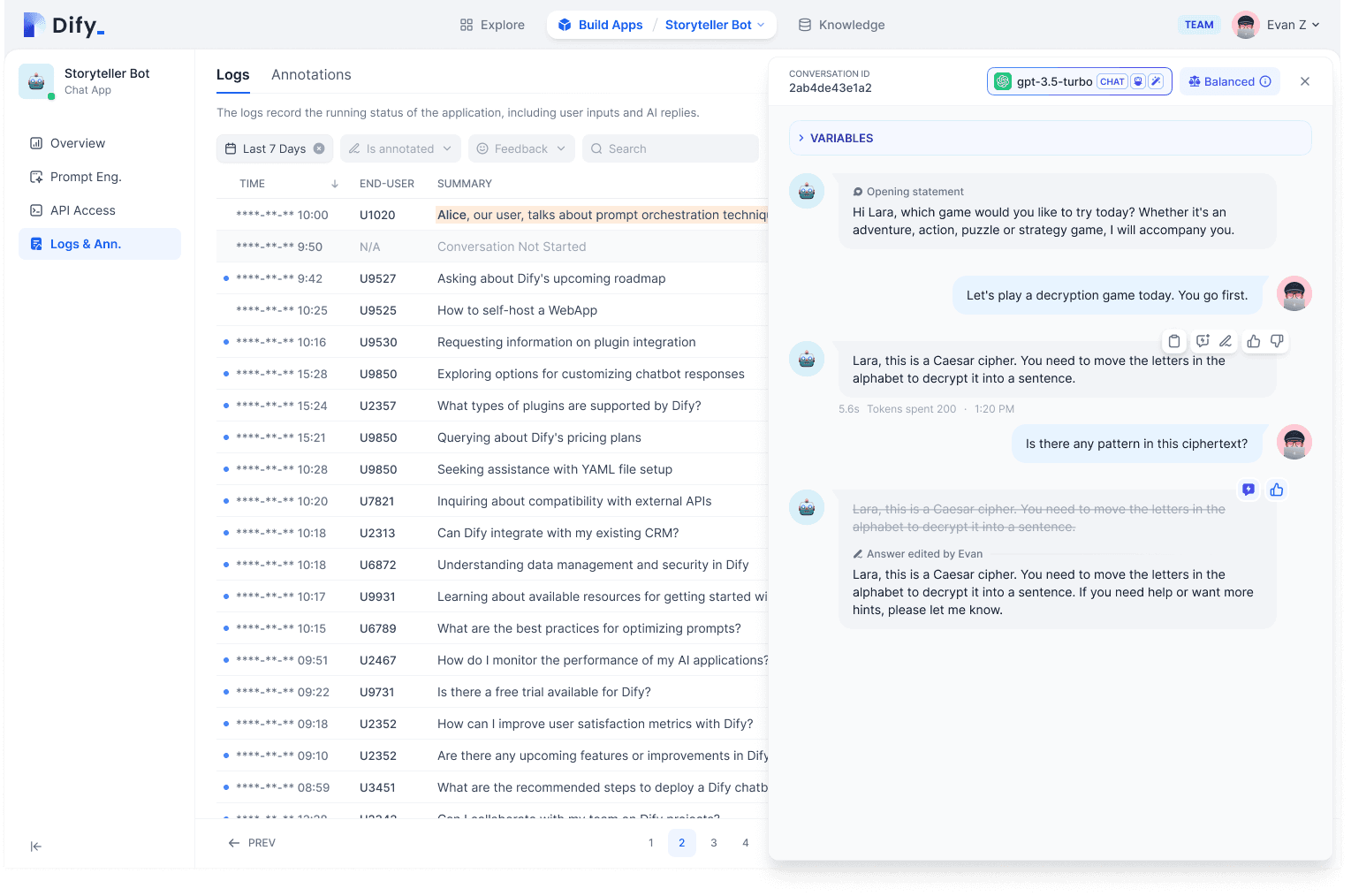
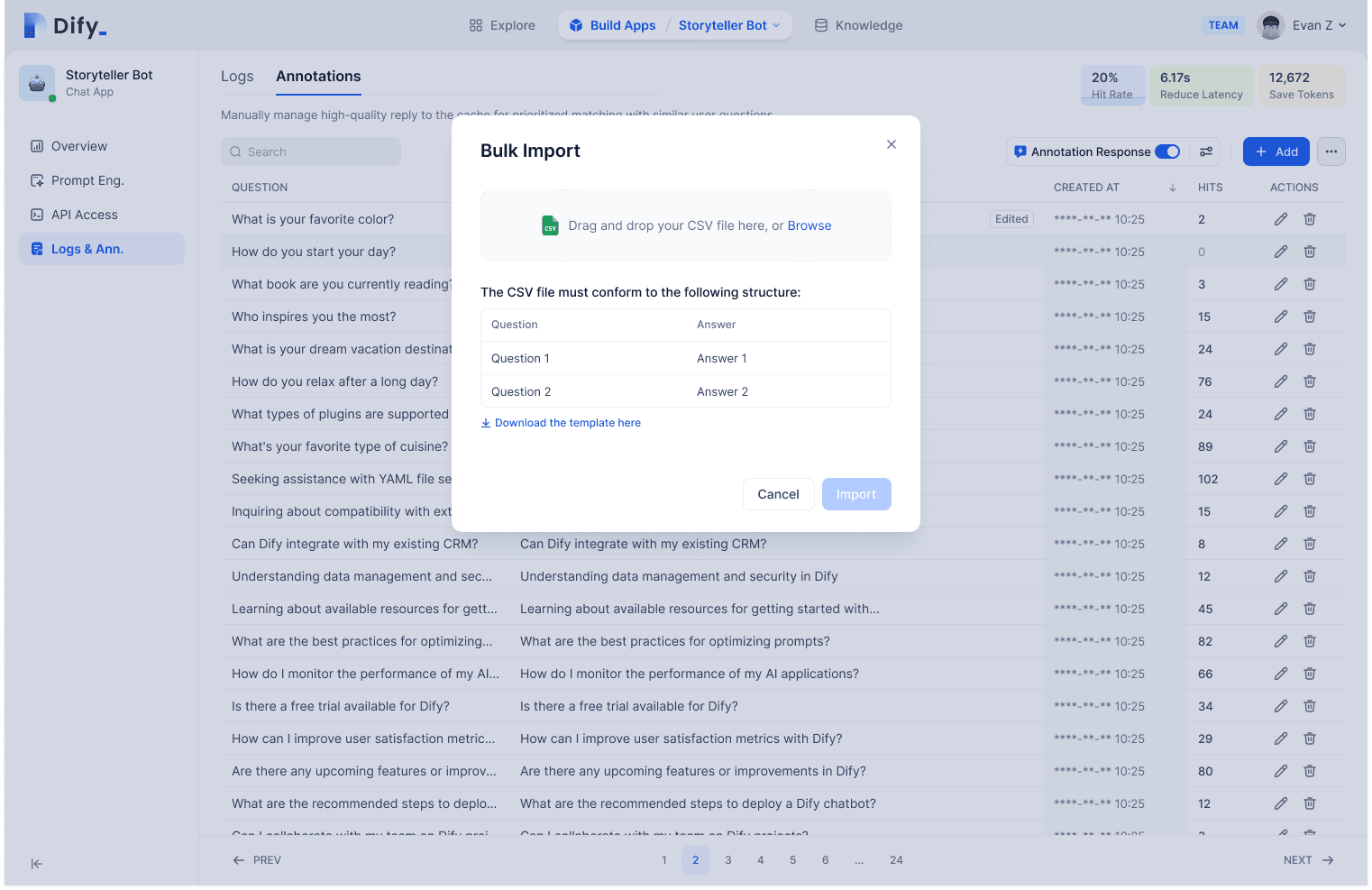
Business teams likely have accumulated standard Q&A pairs as valuable data assets (also why RAG is needed for injecting business knowledge into LLM applications). These can be directly imported through the Dify Annotation Reply feature, easily accessible by logging into Dify.
Lower Token Costs and Faster Response
In conversational scenarios, users often ask duplicate questions that have been answered previously, incurring redundant token costs whenever the LLM is invoked. Dify Annotation Reply data handling has an independent RAG (Retrieval Augmented System) mechanism, separate from the knowledge base. It allows persisting responses for semantically identical queries instead of querying the LLM, hence saving costs and reducing latency.
Why Not GPTCache?
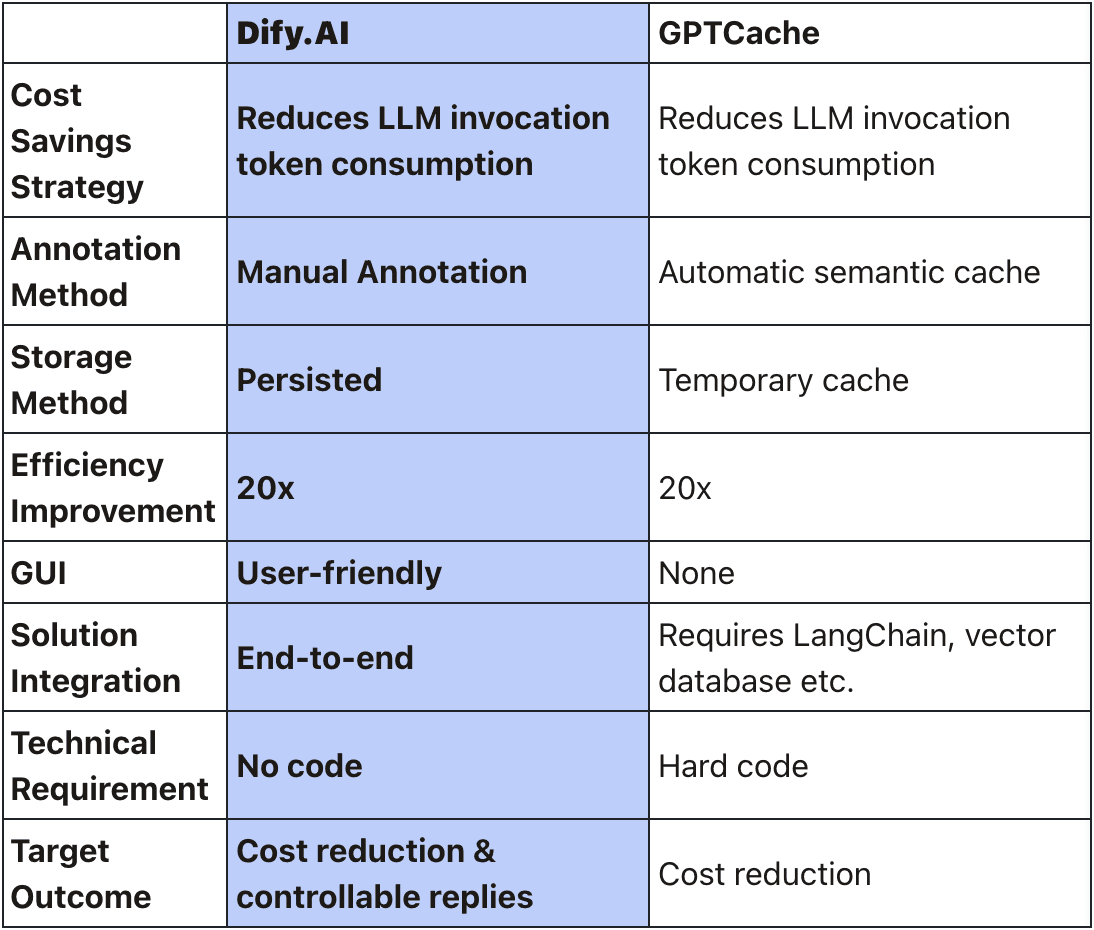
So why choose Dify.AI over GPTCache? GPTCache creates a semantic cache for LLM queries by automatically caching duplicate semantics to reduce requests and tokens sent to LLM services for cost savings. In contrast, Dify persists custom annotated responses to reduce LLM requests, achieving the same cost savings while storing production-quality data more reliably for retrieval.
Regarding automatic semantic caching, VRUSHANK VYAS from Portkey.ai tested in "Reducing LLM Costs & Latency with Semantic Cache" that with semantic caching, these requests can be handled with zero inference latency and token costs, delivering at least a 20x potential speedup at no additional cost.
Additionally, to build an application with GPTCache, more services like LangChain, vector databases, embedding models may be needed, hard coded together into an unverified application. Dify instead provides a complete UI solution where similarity thresholds and embedding models can be tuned flexibly, allowing no code production LLM application development and performance improvement through annotated responses in 2 hours.
Prepare Data for Future Model Fine-tuning
Annotation Reply not only optimizes real-time performance but also accumulates valuable data assets for model fine-tuning. Over time, growing question-answer pairs that capture real user question characteristics and desired replies can be exported on demand for more customized, professionalized capabilities per OpenAI's guidance to significantly improve results from 50-100 effective examples.
Fine-tuning improves on few-shot learning by training on many more examples than can fit in the prompt, letting you achieve better results on a wide number of tasks. Once a model has been fine-tuned, you won't need to provide as many examples in the prompt. This saves costs and enables lower-latency requests.
When Should You Use It?
Here are some examples of using Annotation Reply:
- Fixed responses for sensitive questions:
User: Whose model are you using?
Chatbot(Annotation Reply): Sorry, our business model and technical details are trade secrets which cannot be disclosed. - Standardized question replies:
User: What services do you offer?
Chatbot(Annotation Reply): We offer virtual assistant and knowledge base development services. Standard pricing is $xx/month. - Batch import of existing standardized Q&A:
User: Is your product packaging charged separately?
Chatbot(Annotation Reply): No, we offer standard packaging for free. Premium packaging services can be provided at an additional cost.
How to Use Annotation Reply in Dify.AI?
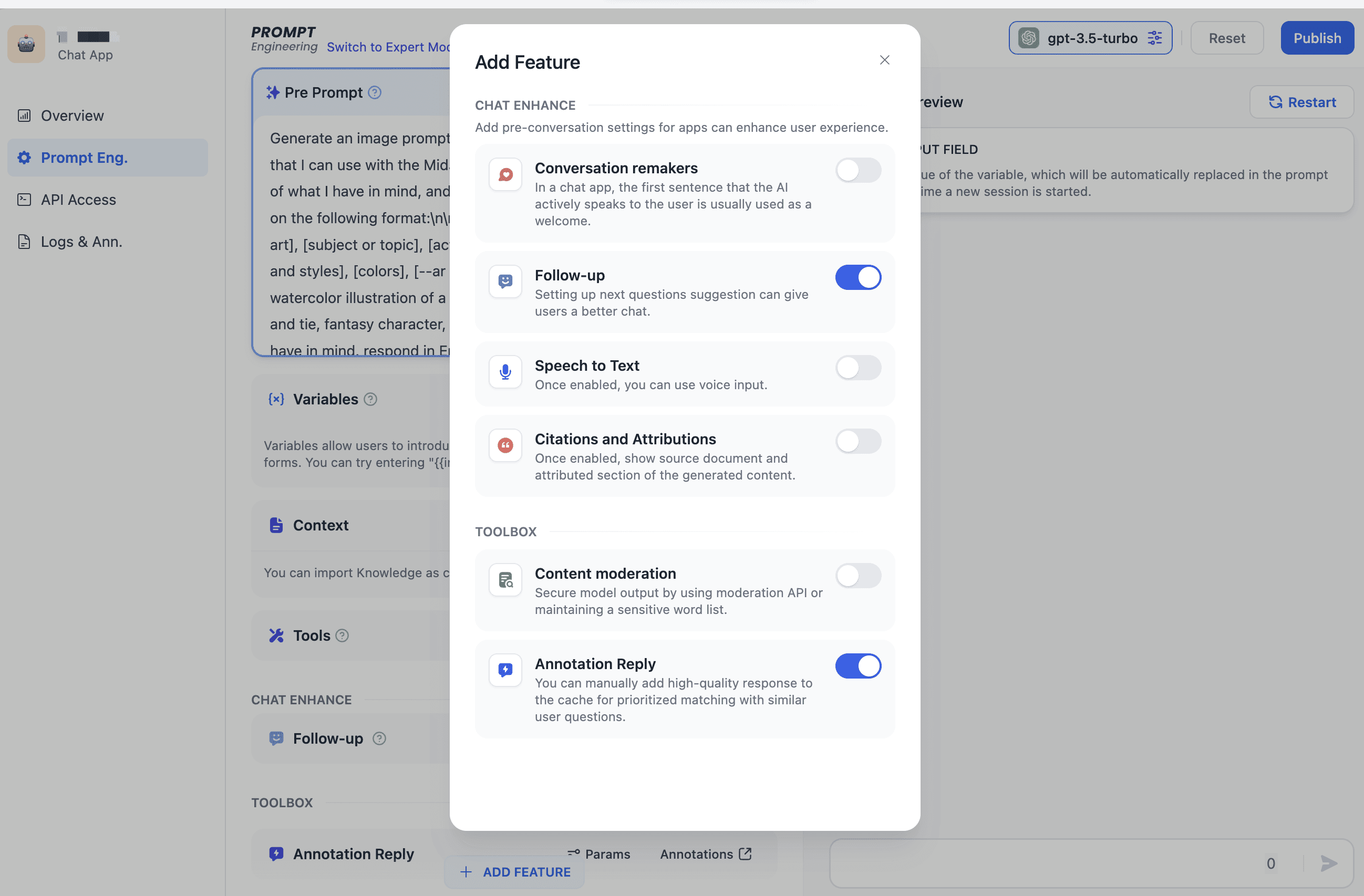
- Enable Annotation Reply under
prompt engineering --> Add feature(currently only supported for chat apps). LLM reply content can then be annotated in LLM apps debug process or logs. High-quality LLM replies can be added directly or edited as needed before being persisted.
- Later questions get vectorized and matched against annotated ones.
- If there is a match, the corresponding annotated response is returned directly without going through LLMs or RAGs.
- If no match, the regular workflow applies (passed to LLMs or RAGs).
- Annotated response matching disabled when the feature is turned off.
Refer to docs for best practices,or see GitHub release notes to upgrade.
Conclusion
Annotation Reply provide an easy way to continuously improve AI application performance towards business objectives. With this feature, you can build consistently improving AI applications.
Related articles
- How to
How to Add an AI Support Assistant to Your Website with Dify
Step-by-step tutorial on how to build, test, and embed an AI chatbot right into your website.
 Dify
Dify - How to
How Marketer Builds Reliable AI Workflows
Every marketer can write a prompt. Few have figured out how to scale them. Inside: three workflows marketing teams actually build. Got a repetitive task you wish was a template? You name it. We build it for free.
Dify - How to
Get Started with Dify
In this guide, you'll learn the core fundamentals, find the right starting point for your first AI application, and grab useful resources to hit the ground running.
Dify - How to
Designing Intent-Based Email Routing with Dify Workflow
Dify uses workflow-based intent routing to automatically classify and assign support emails while keeping decisions controlled and auditable. This approach improves routing consistency and helps support teams scale operations without losing stability.
 Bobby Zhang
Bobby Zhang